







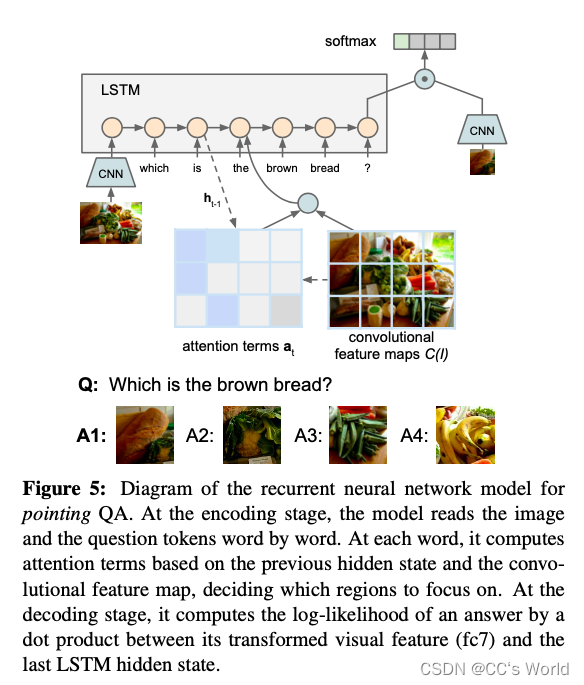
本文是做视觉问答的,模型的主要创新点在于在LSTM中融入对图像特定区域的attention——在 LSTM 架构中添加了一种新的空间注意机制,用于通过文本和视觉答案来处理基于视觉的 QA 任务。 该模型旨在捕捉对图像相关问题的答案通常与特定图像区域相对应的直觉。 当它按顺序读取问题标记时,它会学习关注相关区域。
模型架构为:
给定一个图像 I 和一个问题 Q = (q1, q2, . . . , qm),我们学习图像的嵌入和单词标记如下:
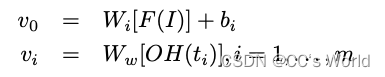
F(·) 将图像 I 从像素空间转换为 4096 维的特征表示。 我们从预训练的 CNN 模型 VGG-16 的最后一个全连接层 (fc7) 中提取。
OH(·) 将单词标记转换为其 one-hot 表示。
Wi 矩阵将 4096 维的图像特征转换为二维嵌入空间 v0,Ww 将 one-hot 向量转换为 dw 维嵌入空间 vi。 我们将 di 和 dw 设置为相同的值 512。
我们将图像作为第一个输入标记。 这些嵌入向量 v0,1,…,m 被一一输入 LSTM 模型。 我们的 LSTM 模型的更新规则可以定义如下:

注意:在LSTM更新公式中,
v
t
v_t
vt是当前时间步的输入,
h
t
−
1
h_{t-1}
ht−1是上一个时间步的隐藏层状态,
r
t
r_t
rt是为了多模态融合而添加的attention,它是基于
h
t
−
1
h_{t-1}
ht−1和每一个视觉区域C(I)而计算出权重,然后对视觉区域C(I)加权求和得到的。C(I)是从同一 VGG-16 模型的第四个卷积层返回图像 I 的 14 × 14 512 维卷积特征图















 7023
7023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









