






 本文深入探讨了视觉问答(VQA)领域的现状,包括现有数据集的局限性、评估指标的挑战以及算法的有效性。文章强调了当前数据集在评估算法全面图像理解能力方面的不足,讨论了VQA与图像字幕等任务的区别,并提出了未来VQA数据集发展的建议。
本文深入探讨了视觉问答(VQA)领域的现状,包括现有数据集的局限性、评估指标的挑战以及算法的有效性。文章强调了当前数据集在评估算法全面图像理解能力方面的不足,讨论了VQA与图像字幕等任务的区别,并提出了未来VQA数据集发展的建议。
Abstract
视觉问答(VQA)是计算机视觉和自然语言处理领域的一个新问题,引起了深度学习、计算机视觉和自然语言处理领域的极大兴趣。在VQA,一种算法需要回答基于文本的图像问题。自2014年第一个VQA数据集发布以来,已经发布了更多数据集,并提出了许多算法。在这篇综述中,我们从问题表述、现有数据集、评估指标和算法等方面批判性地考察了VQA的现状。特别是,我们讨论了当前数据集在正确训练和评估VQA算法方面的局限性。然后我们详尽地回顾现有的VQA算法。最后,我们讨论了VQA和图像理解研究未来可能的方向。
1 Introduction
计算机视觉和深度学习研究的最新进展使许多计算机视觉任务取得了巨大进展,如图像分类[1,2),物体检测[3,4],和活动识别[5,6,7]。给定足够的数据,深度卷积神经网络可以与人类进行图像分类的能力相媲美[2]。由于众包,带注释的数据集在规模上迅速增加,类似的结果也可以预期用于其他聚焦的计算机视觉问题。然而,这些问题范围狭窄,不需要对图像的整体理解。作为人类,我们可以识别图像中的物体,理解这些物体的空间位置,推断它们的属性和彼此的关系,并且在给定周围环境的情况下推断每个物体的用途。我们可以对图像随意提问,也可以交流从图像中收集的信息。
直到最近,开发一种能够回答关于图像的任意自然语言问题的计算机视觉系统一直被认为是一个雄心勃勃但棘手的目标。然而,自2014年以来,在开发具有这些能力的系统方面取得了巨大进展。视觉问答(VQA)是一项计算机视觉任务,系统被给予一个关于图像的基于文本的问题,并且它必须推断出答案。问题可以是任意的,它们包含计算机视觉中的许多子问题,例如,
- 物体识别——图像中有什么?
- 物体探测——图像中有猫吗?
- 属性分类——猫是什么颜色?
- 场景分类——天气晴朗吗?
- 计数-图像中有多少只猫?
除此之外,还有许多更复杂的问题可以问,比如物体之间的空间关系(猫和沙发之间是什么?)和常识推理问题(为什么女孩在哭?)。一个强大的VQA系统必须能够解决大范围的经典计算机视觉任务,并且需要对图像进行推理的能力。
VQA有许多潜在的应用。最直接的方法是帮助盲人和视障人士,使他们能够在网上和现实世界中获得图像信息。例如,当盲人用户滚动他们的社交媒体时,字幕系统可以描述图像,然后用户可以使用VQA来查询图像以获得关于场景的更多见解。更一般地说,VQA可以用来改善人机交互,作为查询视觉内容的一种自然方式。VQA系统也可以用于图像检索,而不使用图像元数据或标签。例如,为了找到在雨天拍摄的所有图像,我们可以简单地问“下雨了吗?”数据集中的所有图像。除了应用,VQA是一个重要的基础研究问题。因为一个好的VQA系统必须能够解决许多计算机视觉问题,它可以被认为是图灵测试的一个组成部分,用于图像理解[8,9]。
视觉图灵测试严格评估计算机视觉系统,以评估它是否能够对图像进行人类层面的语义分析[8,9]。通过这个测试需要一个系统能够完成许多不同的视觉任务。VQA可以被认为是一种视觉图灵测试,它也需要理解问题的能力,但不一定需要更复杂的自然语言处理。如果一种算法在图像的任意问题上表现得和人类一样好或者比人类更好,那么可以说大部分的计算机视觉都会得到解决。但是,只有当基准和评估工具足以做出如此大胆的声明时,这才是正确的。
在这篇综述中,我们讨论了VQA现有的数据集和方法。我们特别强调探索当前的VQA基准是否适用于评估系统是否具有强大的图像理解能力。在第二部分,我们将VQA与其他计算机视觉任务进行比较,其中一些任务还需要视觉和语言的结合(例如,图像字幕)。然后,在第3节中,我们描述了VQA目前可用的数据集,并强调了它们的优势和劣势。我们讨论这些数据集中的偏见如何严重限制他们评估算法的能力。在第4节中,我们讨论了用于VQA的评估指标。然后,我们回顾现有的VQA算法,并在第5节分析它们的有效性。最后,我们讨论了VQA未来可能的发展和有待解决的问题。
2 Vision and Language Tasks Related to VQA
VQA的首要目标是从图像中提取与问题相关的语义信息,其范围从微小细节的检测到基于问题的整个图像的抽象场景属性的推断。尽管许多计算机视觉问题都涉及到从图像中提取信息,但与VQA相比,它们在范围和通用性上是有限的。目标识别、活动识别和场景分类都可以作为图像分类任务,目前最好的方法是使用经过训练的神经网络将图像分类到特定的语义类别中。其中最成功的是物体识别,现在算法在精确度上可以和人类媲美[2]。但是,目标识别只需要对图像中的主要目标进行分类,而不需要知道其空间位置或在更大场景中的角色。对象检测包括通过在图像中对象的每个实例周围放置边界框来定位特定的语义概念(例如,汽车或人)。最好的物体探测方法都是使用[11,4,3深度中枢神经系统]。语义分割通过将每个像素分类为属于特定语义类别[12,13]而将定位的任务向前推进了一步。实例分割通过区分相同语义类的不同实例进一步建立在本地化的基础上[14,15,16]。
虽然语义和实例分割是概括目标检测和识别的重要计算机视觉问题,但是它们不足以理解整体场景。他们面临的主要问题之一是标签模糊。例如,在图1中,黄色十字位置的指定语义标签可以是“包”、“黑”或“人”标签取决于任务。此外,这些方法本身并不理解对象在更大范围内的作用。在这个例子中,将一个像素标记为“包”并不能告诉我们它是否被人携带,而将一个像素标记为“人”并不能告诉我们这个人是坐着、跑步还是滑板。这与VQA形成对比,在那里,系统需要回答关于图像的任意问题,这可能需要对物体之间的关系以及整个场景进行推理。适当的标签由问题指定。

与VQA相比,目标检测、语义分割和图像字幕。中间的图显示了典型对象检测系统的理想输出,右图显示了来自COCO数据集[10的语义分割图。这两个任务都缺乏提供关于对象的上下文信息的能力。这个COCO图像的说明从非常一般的场景描述开始,例如,街道停车场和十字路口旁边的繁忙的城镇人行道,对单一活动进行非常集中的讨论,而不限定整个场景,例如,一个女人牵着一条狗慢跑。两者都是可以接受的标题,但是VQA可以提取更多的信息。对于CoCo-VQA数据集,关于这张图片的问题是溜冰者穿的是什么样的鞋?城市还是郊区?,那是什么动物?
除了VQA,还有大量近期的工作将视觉和语言结合在一起。其中最受研究的是图像字幕[17,5,18,19,20],其中一个算法的目标是产生一个给定图像的自然语言描述。图像字幕是一项非常广泛的任务,可能涉及描述复杂的属性和对象关系,以提供图像的详细描述。
然而,视觉字幕任务有几个问题,评价字幕是一个特殊的挑战。理想的方法是由人类法官来评估,但这既慢又贵。为此,已经提出了多种自动评估方案。最广泛使用的字幕评估方案是BLEU [21], ROUGE [22], METEOR [23], and CIDEr [24]。除了CIDEr,它是专门为评分图像描述开发的,所有的字幕评估指标最初都是为机器翻译评估开发的。这些指标都有局限性。众所周知,最广泛使用的度量标准BLEU对于语义内容变化很大的句子结构变化具有相同的分数[25]。对于在[26]中生成的字幕,BLEU分数将机器生成的字幕排在人类字幕之上。然而,当人类评委被用来评判相同的字幕时,只有23.3%的评委认为字幕的质量等于或优于人类字幕。虽然其他评估指标,尤其是METEOR和CIDEr,在与人类判断的一致性方面显示出更强的鲁棒性,但它们仍然经常将自动生成的字幕排在比人类字幕更高的位置上[27]。
评估字幕具有挑战性的一个原因是,给定的图像可以有许多有效的字幕,有些非常具体,有些本质上是通用的(见图1)。然而,产生仅表面描述图像内容的通用字幕的字幕系统通常根据评估指标排名较高。通用标题,如“一个人在街上走”或“几辆车停在路边”,可适用于大量图像,通常由评估方案和人类判断进行高度排序。事实上,使用最近邻返回具有最相似视觉特征的训练图像的标题的简单系统使用自动评估度量产生相对高的分数[28]。
密集图像字幕(DenseCap)通过用与小而显著的图像区域相关的简短视觉描述对图像进行密集注释,避免了一般字幕问题[29]。例如,DenseCap系统可以输出“一个穿黑衬衫的人”、“大绿树”和“建筑物的屋顶”,每个描述都附有一个边界框。一个系统可以为丰富的场景生成大量这样的描述。尽管许多描述都很简短,但仍然很难自动评估它们的质量。DenseCap还可以通过只为每个区域生成独立的描述来忽略场景中对象之间的重要关系。字幕和DenseCap也是与任务无关的,并且不需要系统来执行详尽的图像理解。
总之,字幕系统可以随意选择图像分析的粒度级别,这与VQA的情况不同,后者的粒度级别由所提问题的性质决定。例如,“这是什么季节?”需要理解整个场景,但是‘站在穿白色衣服的女孩后面的狗是什么颜色的?’需要注意场景的具体细节。此外,许多类型的问题都有具体而明确的答案,这使得VQA比字幕更容易接受自动评估标准。对于某些类型的问题,模糊性可能仍然存在(见第4节),但是对于许多问题,由VQA算法产生的答案可以通过与基本真实答案的一对一匹配来评估。
3 Datasets for VQA
从2014年开始,VQA的五个主要数据集已经公开发布。这些数据集使得VQA系统能够被训练和评估。截至本文,VQA的主要数据集是DAQUAR [30], COCO-QA [31], The VQA Dataset [32], FM-IQA [33], Visual7W [34], and Visual Genome [35]。除了数据采集程序,所有的数据集都包括来自微软通用对象上下文(COCO)数据集[10]的图像,该数据集包括328000幅图像,91个通用对象类别,超过200万个标记实例,平均每幅图像有5个标题。Visual7W [34], and Visual Genome [35]除了使用COCO图像外,还使用了Flickr100M的图像。VQA数据集的一部分包含合成卡通图像,我们称之为SYNTH-VQA。与其他论文一致,[36,37,38],其余的VQA数据集将被称为CoCo-VQA,因为它包含来自CoCo图像数据集的图像。表1包含每个数据集的统计数据。
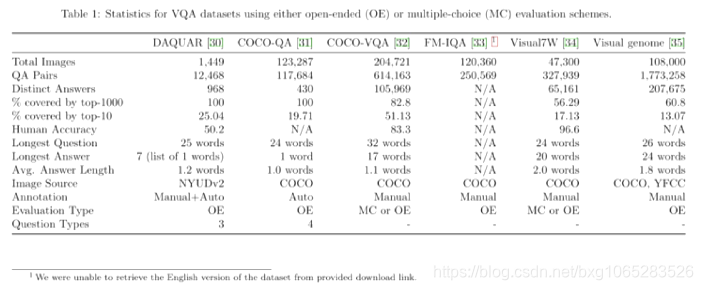
理想的VQA数据集需要足够大,以捕捉现实世界场景中出现的问题、图像和概念的可变性。它还应该有一个公平的评估方案,这是很难“游戏”和做得好,这表明一个算法可以回答各种各样的问题类型的图像有明确的答案。如果数据集在问题或答案的分布中包含容易利用的偏差,算法可能在数据集上表现良好,而不真正解决VQA问题。
在接下来的小节中,我们将重点回顾可用的数据集。我们描述数据集是如何创建的,并讨论它们的局限性。
3.1 DAQUAR
真实世界图像问答数据集[30]是第一个发布的主要VQA数据集。这是最小的VQA数据集之一。它由6795个训练和5673个测试质量保证对组成,基于来自NYU深度V2数据集[39]的图像。数据集也可以在一个更小的配置中使用,该配置只包含37个对象类别,称为DAQUARA-37。DAQUUAR-37仅包含3825个训练QA对和297个测试QA对。在[40]中,为数据采集和分析系统收集了额外的基础事实答案,以创建一个替代评估指标。这种数据采集器的变体被称为数据采集器一致性,以评估度量命名。尽管数据采集和分析是VQA的一个开创性数据集,但它太小,无法成功地训练和评估更复杂的模型。除了体积小之外,数据采集器还专门包含室内场景,这限制了可用问题的多样性。图像往往有明显的杂乱,在某些情况下还有极端的光照条件(见图2)。这使得许多问题难以回答,甚至人类在整个数据集上也只能达到50.2%的准确率。
3.2 COCO-QA
在COCO-QA [31中,QA对是使用自然语言处理(NLP)算法为图像创建的,该算法从COCO图像标题中导出它们。例如,使用图片说明一个男孩正在玩飞盘,有可能产生一个问题:这个男孩在玩什么?答案是飞盘。CoCo-QA数据集包含78736个训练对和38948个测试对。大多数问题是关于图像中的物体(69.84%),其他问题是关于颜色(16.59%)、计数(7.47%)和位置(6.10%)。所有的问题都有一个单词的答案,只有435个唯一的答案。这些对答案的限制使得评估相对简单。
COCO-QA的最大缺点是用于生成质量保证对的自然语言处理算法的缺陷。为了便于处理,较长的句子被分成较小的块,但是在许多这样的情况下,该算法不能很好地处理句子结构中从句和语法变化的存在。这导致了措词笨拙的问题,其中许多包含语法错误,其他的则完全无法理解(见图2)。另一个主要的缺点是它只有四种问题,而且这些问题仅限于COCO的标题中描述的那种事情。

大量的COCO-QA问题都有语法错误,而且没有意义,而数据采集图像经常被杂乱和低分辨率的图像所破坏。
3.3 The VQA Dataset
VQA数据集[32]由CoCo的真实图像和抽象卡通图像组成。这个数据集上的大部分工作仅仅集中在包含来自COCO的真实世界图像的部分,我们称之为COCO-VQA。我们将数据集的合成部分称为合成VQA。
CoCo-VQA由每张图片三个问题组成,每个问题有十个答案。亚马逊土耳其机械公司(AMT)的工作人员被要求为每幅图像生成问题,他们被要求“给一个智能机器人做树桩”,另外还雇佣了一个单独的工作人员来生成问题的答案。与其他VQA数据集相比,COCO-VQA包含相对较多的问题(总共614163个,其中248349个用于训练,121512个用于验证,244302个用于测试)。每个问题都由10个独立的注释器来回答。每个问题的多个答案用于数据集的基于共识的评估指标,这将在第4节中讨论。
SYNTH-VQA由50000个合成场景组成,在不同的模拟场景中描绘卡通形象。场景由100多个不同的物体、30个不同的动物模型和20个人类卡通模型组成。这些人体模型与[41]中使用的相同,它们包含可变形的肢体和八种不同的面部表情。这些模特还跨越不同的年龄、性别和种族,以提供不同的外表。SYNTH-VQA有150000个问答对,每个场景有3个问题,每个问题有10个基本的真实答案。通过使用合成图像,有可能创建一个更加多样和平衡的数据集。自然图像数据集倾向于具有更一致的上下文和偏见,例如,街道场景更可能具有狗的图片而不是斑马的图片。使用合成图像,可以减少这些偏差。阴阳[42]是一个建立在SYNTH-VQA之上的数据集,它试图消除人们对问题的回答中的偏见。我们将在第6.1节进一步讨论阴阳。
SYNTH-VQA和COCO-VQA都有开放式和多项选择两种形式。多项选择格式包含所有相同的QA对,但它也包含18种不同的选择,包括:
- 正确答案,这是十个注释者给出的最常见的答案。
- 似是而非的答案,这是从注释者那里收集的三个答案,无需查看图像。
- 热门答案,是数据集中十大最热门的答案。
- 随机答案,为其他问题随机选择正确答案。
由于数据集的多样性和规模,COCO-VQA已被广泛用于评估算法。但是,数据集有多个问题。CoCo-VQA有很多不同的问题,但是由于语言偏见,很多问题不用图片就能得到准确的回答。相对简单的图像盲算法在可可-VQA上仅用问题就达到了49.6%的准确率[36]。数据集还包含许多主观的、寻求意见的问题,这些问题没有一个单一的客观答案(见图3)。同样,许多问题寻求解释或详细描述。图3c给出了一个例子,它也显示了人类注释者的不可靠性,因为最流行的答案是“是”,这对于给定的问题来说是完全错误的。这些复杂情况反映在这个数据集上的人与人之间的一致性,约为83%。数据集的偏差也引发了其他几个实际问题。例如,“是/否”的回答覆盖了所有问题的38%,其中近59%的回答是“是”结合COCO-VQA使用的评估指标(见第4节),这些偏差会使评估一个算法是否仅使用这个数据集就能真正解决VQA问题变得困难。我们将在第4节进一步讨论这个问题。
3.4 FM-IQA
自由式多语言图像问答(调频-IQA)数据集是另一个基于CoCo[33]的数据集。它包含人类生成的答案和问题。数据集最初是用中文收集的,但现在已经有了英文译本。与COCO-QA和DAQUAR不同,这个数据集还允许答案是完整的句子。这使得使用通用指标进行自动评估变得很难。出于这个原因,作者建议使用人类法官进行评估,法官的任务是决定答案是否由人类提供,并在0-2的范围内评估答案的质量。这种方法对于大多数研究小组来说是不切实际的,并且使得算法的开发变得困难。我们将在第4节进一步讨论自动评估指标的重要性。
3.5 Visual Genome
Visual Genome [35]由108,249幅图像组成,这些图像同时出现在YFC10M[43]和COCO图像中。它包含170万个QA对,每个图像平均有17个质量保证对。截至本文,视觉基因组是最大的VQA数据集。因为它是最近才引入的,所以在作者建立的基线之外没有对它进行评估的方法。
Visual Genome由六种类型的“W”问题组成:什么、在哪里、如何、何时、谁和为什么。使用两种不同的数据收集模式来制作数据集。在自由形式方法中,注释者可以自由地询问关于图像的任何问题。然而,当问自由形式的问题时,人类注释者倾向于问关于图像整体内容的类似问题,例如,问“有多少匹马?”或者“天气晴朗吗?”这可能会导致提问中的偏见。视觉基因组的创建者也通过提示工作人员询问特定图像区域的问题来对抗这个问题。使用这种特定于区域的方法时,可能会提示工作人员询问有关包含消防栓的图像区域的问题。使用Visual Genome的描述性边框提示注释,特定区域的问题提示成为可能。Visual Genome的区域边界框和QA对的例子如图4a所示。

与其他数据集相比,Visual Genome有更大的答案多样性,如图5所示。在Visual Genome中出现频率最高的1000个答案只覆盖了数据集中所有答案的65%,而对于CoCo-VQA,它们覆盖了82%,对于数据CoCo-VQA,它们覆盖了100%。Visual Genome的长尾分布也可以在答案的长度上观察到。只有57%的答案是单个单词,相比之下,COCO-VQA有88%的答案,COCO-QA有100%的答案,DAQUAR有90%的答案。答案的多样性使得开放式评估更具挑战性。此外,由于类别本身被要求严格地属于六种“W”类型之一,答案的多样性有时可能仅仅是由于措辞的变化而造成的,这种变化可以通过提示注释者选择更简洁的答案来消除。例如,汽车停在哪里?可以用“在街上”来回答,或者更确切地说,用“街道”来回答。
Visual Genome没有二进制(是/否)问题。数据集创建者认为这将鼓励使用更复杂的问题。这与VQA数据集形成对比,在该数据集中,“是”和“否”是更常见的答案。我们将在第6.4节进一步讨论这个问题。
3.6 Visual7W
Visual7W数据集是视觉基因组的一个子集。Visual7W包含47300张来自Visual Genome的图像,这些图像也存在于COCO中。Visual7W是根据它包含的七类问题命名的:什么、在哪里、如何、何时、谁、为什么和哪个。数据集由两种不同类型的问题组成。“讲述”问题与视觉基因组问题相同,答案是基于文本的。“指向”问题是以“哪个”开头的问题,对于这些问题,算法必须在选项中选择正确的边界框。一个指向问题的例子如图4b所示。
Visual7W使用一个选择题答案框架作为标准评估,在评估期间为算法提供四个可能的答案。为了使任务更具挑战性,多项选择包括了对给定问题合理的答案。通过提示注释者在不看到图像的情况下回答问题,收集貌似合理的答案。对于指向问题,多项选择选项是围绕可能答案的四个看似合理的边界框。与Visual Genome一样,数据集不包含任何二进制问题。
3.7 SHAPES
其他VQA数据集包含真实场景或合成场景,而形状数据集[44]包含不同排列、类型和颜色的形状。问题是关于属性、关系和形状的位置。这种方法可以创建大量的数据,避免了其他数据集在不同程度上存在的许多偏差。
SHAPES由244个独特的问题组成,每个问题都与数据集中的64幅图像有关。与其他数据集不同,这意味着它是完全平衡的,没有偏见。所有问题都是二元的,有是/否的答案。许多问题需要对形状的布局和属性进行位置推理。尽管SHAPES不能代替真实世界的图像,但它背后的理念是非常有价值的。一个算法在SHAPES上不能很好地执行,但是在其他VQA数据集上可以很好地执行,这可能表明它只能以有限的方式分析图像。
4 Evaluation Metrics for VQA
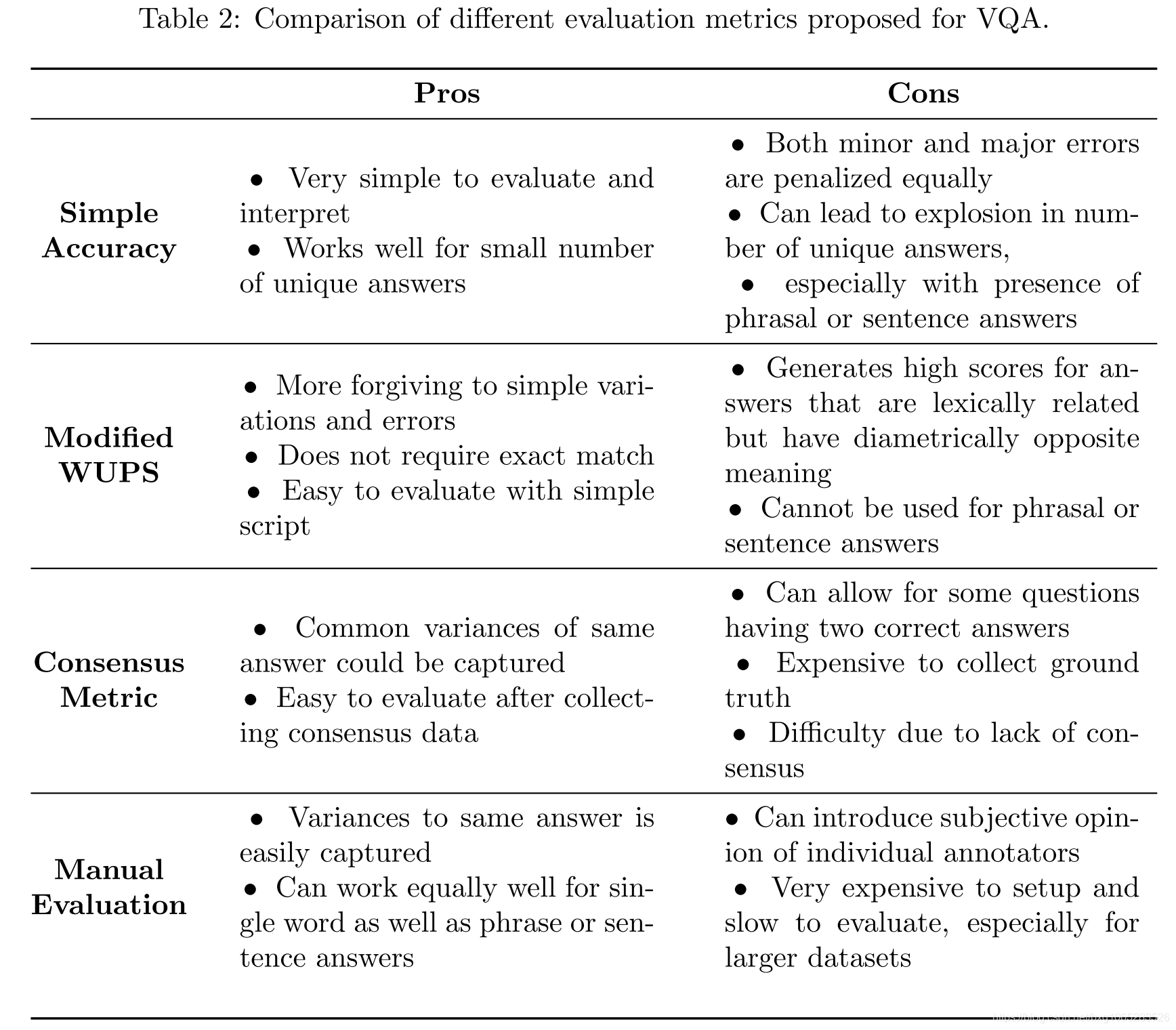
VQA要么是一个开放式任务,算法生成一个字符串来回答一个问题,要么是一个多项选择题,它在选项中进行选择。对于多项选择,通常使用简单的准确性来评估,如果算法做出正确的选择,它就会得到正确的答案。对于开放式VQA,也可以使用简单的精确度。在这种情况下,算法的预测答案字符串必须与基本真实答案完全匹配。然而,准确性可能过于严格,因为有些错误比其他错误更糟糕。例如,如果问题是“照片里有什么动物?”一个系统输出“狗”而不是正确的标签“复数狗”,它受到的惩罚和输出“斑马”一样严重。问题也可能有多个正确答案,例如,“树里有什么?”可能将“秃鹰”列为正确的地面真实答案,因此输出“鹰”或“鸟”的系统将受到惩罚,就像它输出的答案是“是”一样。由于这些问题,已经提出了几种精确精度的替代方法来评估开放式VQA算法。
吴-帕尔默相似性(WUPS)45]在30中被提出作为准确度的替代方法。它试图根据语义的不同来衡量一个预测的答案与基本事实有多大的不同。给定一个基本的真实答案和一个问题的预测答案,WUPS将根据它们之间的相似性指定一个介于0和1之间的值。它通过在两个语义之间找到最不常见的包含者,并根据需要遍历语义树多远来找到常见的包含者来分配分数。使用WUPS,语义相似但不完全相同的单词相对较少受到惩罚。根据我们前面的例子,“秃鹰”和“鹰”的相似度为0.96,而“秃鹰”和“鸟”的相似度为0.88。然而,WUPS倾向于给更远的概念分配相对较高的分数,例如,“乌鸦”和“写字台”的WUPS分数为0.4。为了弥补这一点,[30]建议将WUPS分数设置为阈值,低于阈值的分数将按比例缩小一个系数。[30]建议阈值为0.9,比例因子为0.1。除了简单的准确性之外,这种改进的WUPS度量是用于评估DAQUAR和CoCo-QA的标准度量。
WUPS有两个主要缺点,使得它很难使用。首先,尽管使用了WUPS的阈值版本,但某些词对在词汇上非常相似,但含义却大相径庭。这对于关于对象属性的问题尤其成问题,例如颜色问题。例如,如果正确答案是“白色”,而预测答案是“黑色”,那么答案仍然会得到0.91的WUPS分数,这似乎过高了。WUPS的另一个主要问题是它只适用于严格的语义概念,这些概念几乎都是单个单词。WUPS不能用于偶尔在VQA数据集和大部分Visual7W中发现的短语或句子答案。
对于VQA数据集,注释者为每个问题生成十个答案。这些与精度度量的变化一起使用,精度度量由下式给出
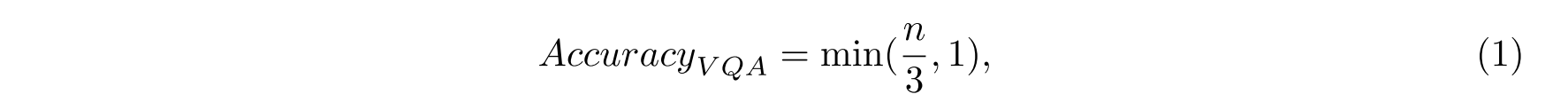
其中n是与算法具有相同答案的注释器的总数。使用这个度量,如果算法与三个或更多的注释者一致,那么它将获得一个问题的满分。尽管这个度量对模糊性问题有很大的帮助,但是仍然存在实质性的问题,尤其是数据集的COCO-VQA部分,我们将在接下来的几个段落中进一步研究这个部分。
使用AccuracyVQA,关于COCO-VQA的注释者拥有共识仅为83.3%。 算法不可能达到100%的准确性。 对于“为什么”的问题,人与人之间的共识特别差,其中超过59%的问题中只有不到三个注释者给出完全相同的答案。 这使得无法在这些问题上获得满分。 在更简单,更直接的问题中也可以看出缺乏人与人之间的共识(见图7)。 在此示例中,如果系统预测了10个答案中的任何一个,则将获得至少1/3的分数。 在某些情况下,注释者提供的答案包含完整的反义词(例如,左和右)。

在许多其他情况下,AccuracyVQA可以为彼此直接对立的问题提供多个正确答案。 例如,在COCO-VQA中,超过13%的“是/否”答案中有超过三个注释者重复了“是”和“否”。 回答“是”或“否”将获得最高分。 即使八个注释者回答“是”,如果两个注释者回答“否”,那么该问题的算法仍将获得0.67的分数。 多数人的权重在评估中不起作用。
这些问题可能导致分数被夸大。 例如,在所有“是/否”问题中回答“是”,理想情况下,这些问题的得分应在50%左右。 但是,使用AccuracyVQA,得分为71%。 这部分是由于数据集存在偏见,这些问题的大多数答案在58%的时间中是“是”,但71%的分数过分夸大了。
当答案由一个单词组成时,评估VQA系统的开放式响应将变得更加简单。 87%的COCO-VQA问题,100%的COCO-QA问题和90%的DAQAUR问题中都会出现这种情况。 当答案需要为多个单词时,多个正确答案的可能性会大大增加。 这在FM-IQA,Visual7W和Visual Genome中经常发生,例如27%的Visual7W答案包含三个或更多单词。 在这种情况下,诸如AccuracyVQA之类的指标不太可能为开放式VQA中的地面真相答案打分。
FM-IQA的创建者[33]建议使用人类法官来评估多词答案,但这带来了许多问题。 首先,就时间,资源和费用而言,聘请人类法官是一个极其苛刻的过程。 通过测量更改算法如何更改性能将很难迭代地改进系统。 其次,需要给人类法官提供判断答案质量的标准。 FM-IQA的创建者为人类法官提出了两个指标。 首先是要确定答案是否由人为产生,而不管答案是否正确。 单独使用该指标可能无法很好地说明VQA系统的功能,并且有可能被操纵。 第二个度量标准是对三分制的答案进行评分,该分数为完全错误(0),部分正确(1)和完全正确(2)。
使用判断器处理多词答案的另一种方法是使用多项选择范式,该范式由VQA数据集,Visual7W和Visual Genome的一部分使用。 无需生成答案,系统只需预测给定选择中的哪一个是正确的即可。 这极大地简化了评估,但是我们认为,除非谨慎使用,否则多项选择不适合VQA,因为它允许系统窥视正确答案,从而破坏了工作量。 我们将在6.5节中讨论此问题。
评估VQA系统的最佳方法仍然是一个悬而未决的问题。 每种评估方法都有其优点和缺点(摘要请参见表2)。 使用的方法取决于数据集的构造方式,其中的偏差程度以及可用资源。 为了开发更好的工具来测量答案的语义相似性和处理多词答案,需要做大量的工作。
5 Algorithms for VQA
在过去的三年中,已经提出了大量的VQA算法。现有的所有方法包括:1)提取图像特征(图像特征化),2)提取问题特征(问题特征化)和3)组合这些特征以产生答案的算法。对于图像特征,大多数算法使用在ImageNet上经过预训练的CNN,常见示例为VGGNet [1],ResNet [2]和GoogLeNet [58]。已经探索了各种各样的问题特征化,包括单词袋(BOW),长期短期记忆(LSTM)编码器[59],门控递归单元(GRU)[60]和跳跃思想向量[61]。 。为了产生答案,最常见的方法是将VQA视为分类问题。在此框架中,图像和问题特征是分类系统的输入,每个唯一答案都被视为不同的类别。如图8所示,特征化方案和分类系统可以采用多种形式。这些系统在集成问题和图像功能方面有很大不同。一些示例包括:
- 使用简单的机制(例如,串联,逐元素乘法或逐元素加法)将图像和问题特征进行组合,然后将其提供给线性分类器或神经网络[36,38,32,33],
- 在神经网络框架中使用双线性池或相关方案将图像和问题特征进行组合[46,53,62],
- 具有使用问题特征为视觉特征计算空间注意图或根据其相对重要性自适应缩放局部特征的分类器,[49,51,48,63],
- 使用贝叶斯模型来利用问题图像-答案特征分布[36,30]
- 使用问题将VQA任务分解为一系列子问题[50,44]。
在后面的小节中,我们将详细介绍这些基于分类的方法。
尽管大多数开放式VQA算法都使用分类框架,但是这种方法只能生成在训练过程中看到的答案,从而促使一些人探索替代方法。 在[33]和[40]中,使用LSTM一次生成一个多单词答案。 但是,所产生的答案仍然仅限于训练期间看到的单词。 对于多项选择的VQA,[64]和[63]建议将VQA视为排名问题,训练系统对每个可能的多项选择答案,问题和图像三重奏产生分数,然后选择最高分数 评分答案选择。
在以下小节中,我们基于VQA算法的共同主题将其分组。表3中按性能从高到低的顺序列出了DAQUAR,COCO-QA和COCO-VQA的结果。 在表3中,我们报告了DAQUAR和COCO-QA的简单准确性,我们报告了COCO-VQA的AccuracyVQA。 表4细分了基于每篇论文使用的COCO-VQA的结果。
5.1 Baseline Models
基线方法可帮助确定数据集的难度,并确定更复杂的算法应超过的最低性能水平。 对于VQA,最简单的基准是随机猜测和猜测最多重复的答案。 广泛使用的基线分类系统是将线性或非线性(例如多层感知器(MLP))分类器应用于图像和问题特征,然后将它们组合为单个向量[32、36、38]。 组合特征的常用方法包括级联,按元素乘积或按元素和。 也已经探索了将这些方案结合起来可以改善结果的方法[62]。
基线分类框架已使用了多种特征化方法。 在[38]中,作者使用了一个词袋来表示问题和来自GoogLeNet的CNN视觉特征。 然后,他们将这些特征的组合输入到多类逻辑回归分类器中。 他们的方法效果很好,超过了先前的COCO-VQA基线,后者使用了理论上更强大的模型LSTM来表示问题[32]。 类似地,[36]使用跳思想向量[61]作为问题特征,并使用ResNet-152提取图像特征。 他们发现,具有针对这些现成特征进行训练的两个隐藏层的MLP模型适用于所有数据集。 但是,在他们的工作中,线性分类器在较小的数据集上的表现优于MLP模型,这可能是由于MLP模型过度拟合造成的。
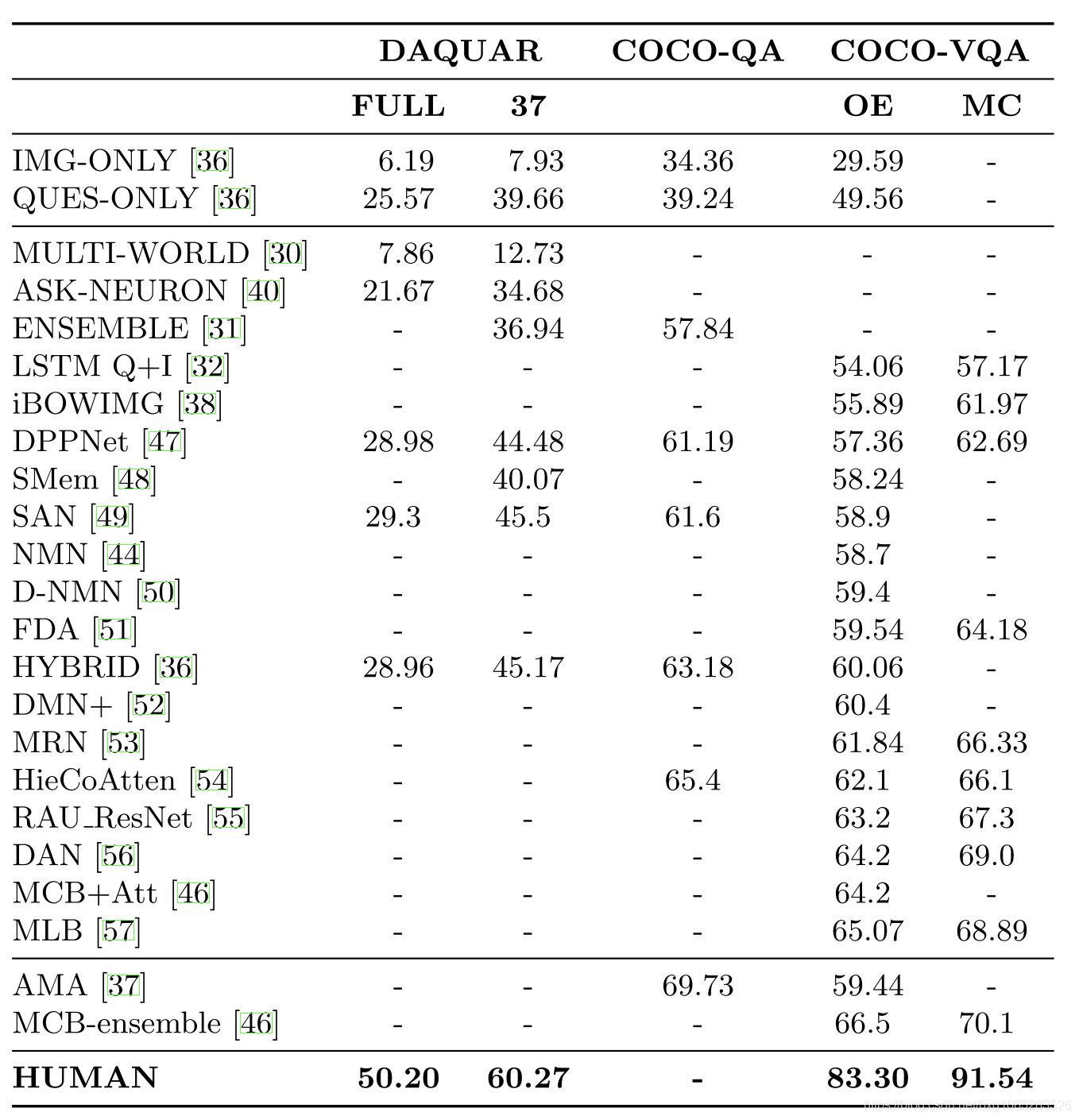
开放式(OE)和多项选择(MC)评估方案的VQA数据集的结果。 还显示了仅对图像数据(仅IMG)和仅对问题数据(QUES-ONLY)以及人员性能进行训练的简单模型。 仅在IMG和QUES模型在COCO-VQA的“测试开发”部分进行评估。 MCB-ensemble [46]和AMA [37]是分开介绍的,因为它们使用其他数据进行训练。
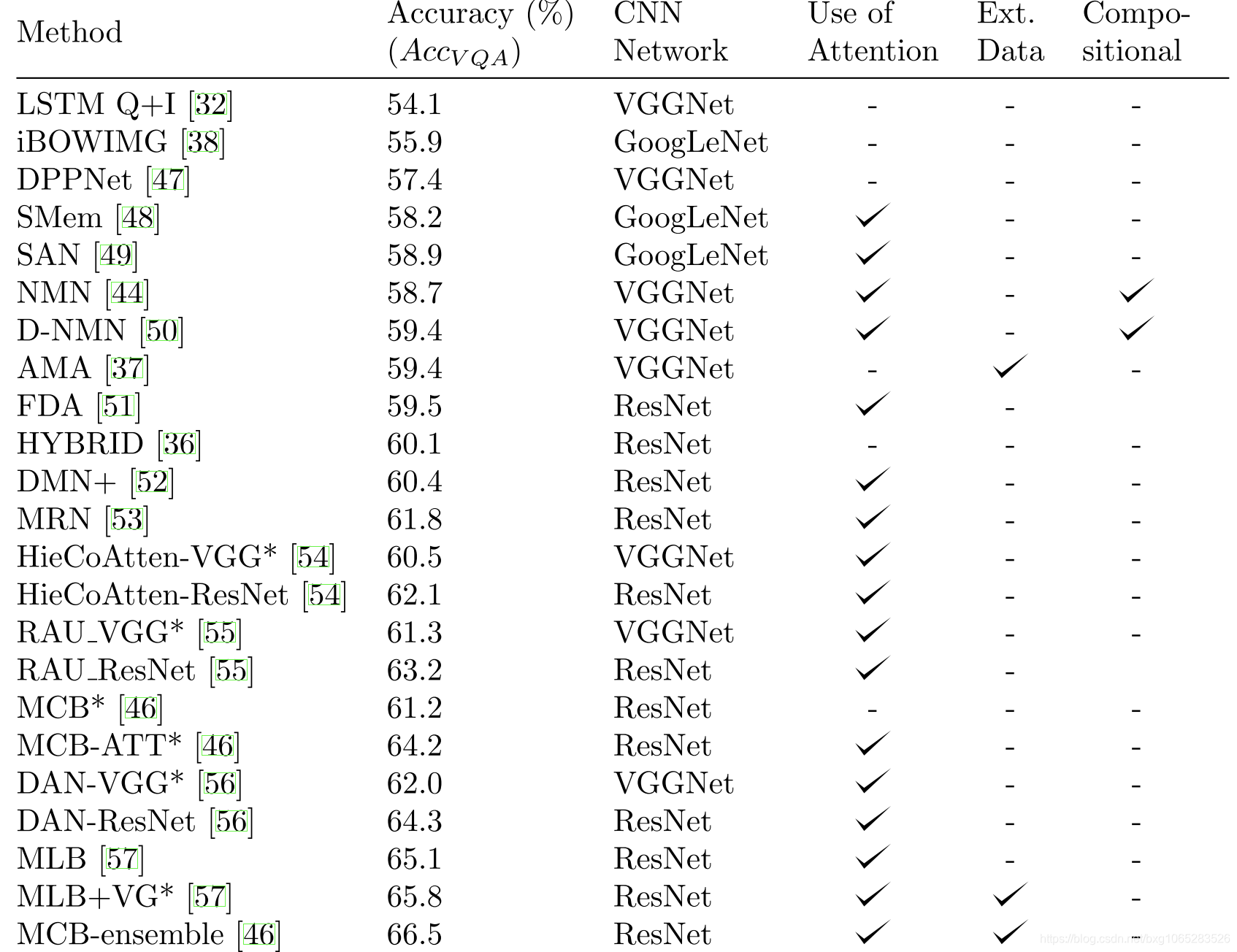
在开放式COCO-VQA上评估的不同方法及其设计选择的概述。当“测试标准”结果不可用时,结果是关于“测试-dev”分割的报告(用*表示)
几种VQA算法已使用LSTM编码问题。在[32]中,使用对句子进行一次热编码的LSTM编码器来表示问题特征,而GoogLeNet则用于图像特征。减少CNN特征的维数以匹配LSTM编码的维数,然后使用这两个向量的Hadamard乘积将它们融合在一起。融合的矢量用作具有两个隐藏层的MLP的输入。在[40]中,LSTM模型被顺序地嵌入了每个单词,并带有与其相连的CNN特征。这一直持续到问题结束为止。随后的时间步骤用于生成答案列表。在[31]中使用了一种相关的方法,在LSTM中,在最初和最后的时间步骤中向CNN特征提供了LSTM,并且在这两个词之间插入了词特征。图像特征充当句子中的第一个和最后一个单词。 LSTM网络之后是softmax分类器,以预测答案。在[33]中使用了类似的方法,但是CNN图像特征仅在问题末尾馈入LSTM中,而不是使用分类器,而是使用另一个LSTM一次生成一个单词的答案。
5.2 Bayesian and Question-Aware Models
VQA要求在问题和图像之间进行推理和建模。 一旦对问题和图像进行了特征化处理,对问题和图像特征的共现统计建模就可以帮助得出有关正确答案的推论。 两个主要的贝叶斯VQA框架已探索对这些关系进行建模。 在[30]中,提出了第一个VQA贝叶斯框架。 作者使用语义分割来识别图像中的对象及其位置。 然后,对贝叶斯算法进行了训练,以对物体的空间关系进行建模,该算法用于计算每个答案的概率。 这是最早的VQA算法,但简单的基线模型已超过了它的功效。 部分原因是它依赖于不完美的语义分割结果。
文献[36]提出了一种非常不同的贝叶斯模型。 该模型利用了一个事实,即仅使用问题就可以预测答案的类型。 例如,“花是什么颜色?”将由模型分配为颜色问题,从本质上将开放式问题转变为多项选择题。 为此,该模型使用了二次判别分析的变体,该模型对给定问题特征和答案类型的图像特征概率进行了建模。 ResNet-152用于图像特征,而跳越思想的矢量用于表示问题。
5.3 Attention Based Models
仅使用全局功能可能会使输入空间中与任务相关的区域模糊。 attention模型试图克服这一限制。 这些模型学会了“参与”输入空间中最相关的区域。 注意模型已经在其他视觉和NLP任务中取得了巨大的成功,例如对象识别[65],字幕[20]和机器翻译[66,67]。
在VQA中,许多模型都利用空间注意力来创建特定于区域的CNN特征,而不是使用整个图像中的全局特征。 更少的模型也已经探索将注意力引入文本表示中。 所有这些模型背后的基本思想是,图像中的某些视觉区域和问题中的某些单词在回答一个给定问题方面比其他方面更具信息性。 例如,对于回答“雨伞是什么颜色?”的系统,包含雨伞的图像区域比其他图像区域更具信息性。 同样,“颜色”和“伞”是需要比其他输入更直接解决的文本输入。 全局图像功能(例如,CNN的最后一个隐藏层)和全局文本功能(例如,单词袋,跳过思想等)可能不够精细,无法解决区域特定的问题。
在使用空间注意机制之前,算法必须代表所有空间区域的视觉特征,而不是仅仅代表全局水平。然后,根据提出的问题,可以使来自相关区域的局部特征更加突出。有两种常见的方法来实现局部特征编码。如图9所示,一种方法是在所有图像位置上施加一个统一的网格,在每个网格位置都存在局部图像特征。这通常是通过在使特征平坦化的最终空间池之前对最后一个CNN层进行操作来完成的。然后由问题确定每个网格位置的相关性。进行空间关注的另一种方法是为图像生成区域建议(边界框),使用CNN对每个框进行编码,然后使用问题确定每个框的特征的相关性。尽管有多篇论文致力于将空间视觉注意力用于VQA [63、49、52、48、54、51、46、55],但这些方法之间存在显着差异。

该图说明了将注意力纳入VQA系统的一种常用方法。 CNN中的卷积层输出特征响应的K×K×N张量,对应于N个特征图。 引起关注的一种方法是通过抑制或增强不同空间位置处的特征。 通过将问题特征与这些本地图像特征结合使用,可以计算出每个网格位置的权重因子,从而确定空间位置与问题的相关性,然后可以将其用于计算注意力加权的图像特征。
VQA的聚焦区域[63]和聚焦动态注意力(FDA)模型[51]都使用边缘框[68]生成图像的边界框区域提议。 在[63]中,使用CNN从这些盒子的每一个中提取特征。 他们的VQA系统的输入内容包括这些CNN特征,问题特征以及多项选择答案之一。 他们的系统经过训练可以为每个选择题答案产生一个分数,并选择得分最高的答案。通过将区域CNN特征的点积和问题嵌入到完全连接的层中而简单地学习权重的每个区域的分数的加权平均值,即可计算出分数。
在FDA [51]中,作者建议仅使用具有问题中提到的对象的图片区域建议。 他们的VQA算法需要输入带有相应对象标签的边界框列表作为输入。 在训练期间,对象标签和边界框是从COCO注释中获得的。 在测试期间,通过使用ResNet [2]对每个边界框进行分类来获得标签。 随后,使用word2vec [69]计算问题中的单词与分配给每个边界框的对象标签之间的相似度。 分数大于0.5的任何盒子都将被连续馈入LSTM网络。 在最后一个时间步,整个图像的全局CNN特征也被馈入网络,从而可以访问全局和局部特征。 单独的LSTM也用作问题表示。 然后,将这两个LSTM的输出馈入一个完全连接的层,该层将馈入softmax分类器以产生答案预测。
与使用区域提议相比,堆叠注意力网络(SAN)[49]和动态内存网络(DMN)[52]都使用了CNN特征图空间网格中的视觉特征(请参见图9)。 [49]和[52]都使用了来自VGG-19的最后一个卷积层,具有448×448图像,以在每个网格位置生成具有512维特征的14×14滤波器响应图。
在SAN [49]中,关注层是由单层权重指定的,该权重层使用问题和带有softmax激活函数的CNN特征图来计算图像位置之间的注意力分布。 然后,将这种分布应用于CNN特征图,以使用加权总和在空间特征位置上进行合并,该加权总和生成全局图像表示,该图像表示比其他空间区域更多地强调某些空间区域。 然后将此特征向量与问题特征向量组合在一起,以创建可与softmax层一起使用以预测答案的表示形式。 他们推广了这种方法来处理多个(堆叠的)注意层,从而使系统能够对图像中多个对象之间的复杂关系进行建模。
在空间记忆网络[48]模型中使用了类似的注意机制,其中空间注意力是通过估计图像补丁与问题中单个单词的相关性而产生的。 单词引导的注意力用于预测注意力分布,然后用于计算嵌入图像区域的视觉特征的加权和。 然后探索了两种不同的模型。 在单跳模型中,对整个问题进行编码的特征与加权的视觉特征相结合以预测答案。 在两跳模型中,视觉和问题特征的组合被循环回用于细化注意力分布的注意力机制。
在[52]中提出了使用CNN特征图合并空间注意力的另一种方法。为此,他们使用了经过修改的动态内存网络(DMN)[70]。 DMN由输入模块,情景存储模块和应答模块组成。 DMN已用于基于文本的QA,其中句子中的每个单词都输入到最新的神经网络中,并且网络的输出用于提取“事实”。然后,情节记忆模块对子集进行多次遍历这些事实。每次通过时,网络的内部存储器表示都会更新。应答模块使用存储器表示的最终状态和输入问题来预测答案。要将DMN用于VQA,他们除了文字之外还使用了视觉事实。为了生成视觉事实,每个空间网格位置处的CNN特征都被视为句子中的单词,这些单词依次被馈送到递归神经网络中。情节式记忆模块然后通过文本和视觉事实来更新其记忆。应答模块保持不变。
分层共同注意模型[54]将注意力同时应用于图像和问题,以共同推理两个不同的信息流。该模型的视觉注意力方法类似于空间内存网络[48]中使用的方法。除了视觉上的注意,此方法还使用了问题的分层编码,其中编码发生在单词级别(使用单次热编码),短语级别(使用二元或三元语法窗口大小) )和问题级别(使用LSTM网络的最终时间步)。使用这种分层的问题表示,作者建议使用两种不同的注意机制。平行共同注意方法同时关注问题和形象。另一种共同注意方法是在关注问题或图像之间交替进行。这种方法允许彼此确定问题中单词的相关性和特定图像区域的相关性。答案预测是通过递归组合问题层次结构所有三个级别的共同参与特征来进行的。
在[56]中还探讨了使用联合注意力来获取图像和问题特征。 主要思想是使图像和问题的注意力相互引导,同时将注意力引导到相关的单词和视觉区域。 为了实现这一点,视觉和问题输入由存储向量共同表示,该存储向量用于同时预测问题和图像特征的注意力。 细心机制将计算更新的图像和问题表示形式,然后将其用于递归更新存储向量。 此递归内存更新机制可以重复K次,以分多个步骤改善注意力。 作者发现,K = 2的值最适合COCO-VQA。
5.4 Bilinear Pooling Methods
VQA依靠共同分析图像和问题。 早期的模型通过使用简单的方法(例如,级联或在问题和图像特征之间使用按元素的乘积)组合各自的特征来做到这一点,但是在这两种信息流之间的外部乘积可能会进行更复杂的交互 。 相似的想法被证明对改善细粒度图像识别效果很好[71]。 下面,我们描述了使用双线性池[46,57]的两种最突出的VQA方法。
在[46]中,提出了多峰紧凑双线性(MCB)合并作为在VQA中组合图像和文本特征的新方法。 与其他机制(例如,级联或逐元素乘法)相比,该想法是近似估计图像和文本特征之间的外部乘积,从而允许两种模态之间进行更深层的交互。 MCB不会显式地制作尺寸很高的外部乘积,而是在较低尺寸的空间中制作外部乘积。 然后将其用于预测哪些空间特征与问题相关。 在该模型的变体中,还使用了一种类似于[49]中方法的软注意力机制,唯一的主要变化是使用MCB组合文本和问题特征,而不是逐元素相乘 在[49]中。 这种组合在COCO-VQA上取得了非常好的成绩,并且是2016年VQA挑战赛的获胜者。
在[57]中,作者认为,尽管使用了近似的外部乘积,但MCB在计算上过于昂贵。 相反,他们提出使用多模式低秩双线性池(MLB)方案,该方案使用Hadamard乘积和线性映射来实现近似双线性池。 当与空间视觉注意力机制一起使用时,MLB在VQA上可与MCB媲美,但具有较低的计算复杂度并使用参数较少的神经网络。
5.5 Compositional VQA Models
在VQA中,问题通常需要多个推理步骤才能正确回答。 例如,“马的左边是什么?”之类的问题可能涉及首先找到马,然后将对象命名为马的左边。 已经为VQA提出了两个组成框架,试图通过一系列子步骤来解决VQA问题[44、50、55]。 神经模块网络(NMN)[44,50]框架使用外部问题解析器来查找问题中的子任务,而循环应答单元(RAU)[55]被端到端训练,并且子任务可以隐式地进行学习。
NMN是VQA的一种特别有趣的方法[44,50]。 NMN框架将VQA视为由独立的神经子网执行的一系列子任务。每个子网都执行一个明确定义的任务,例如,find [X]模块会为特定对象的存在生成热图。其他模块包括描述,度量和转换。然后,必须将这些模块组装成有意义的布局。已经探索出两种方法来推断所需的布局。在[44]中,自然语言解析器用于输入问题,既可以找到问题中的子任务,又可以推断子任务的所需布局,当按顺序执行该子任务时,将产生给定问题的答案[ 44]。例如,回答“领带是什么颜色?”将涉及执行find [tie]模块,然后执行describe [color]模块,后者会生成答案。在[50]中,同一组研究人员使用算法从一组自动生成的布局候选中动态选择给定问题的最佳布局。
RAU模型[55]可以隐式执行合成推理,而无需依赖外部语言解析器。 在他们的模型中,他们使用了多个可以解决VQA子任务的独立应答单元。 这些应答单元以循环方式排列。 链上的每个答题单元都配备了一种源自[49]的注意机制和一个分类器。 作者声称,包含多个循环应答单元可以从每个应答单元解决的一系列子任务中推断出答案。 但是,他们没有进行可视化或消融研究以显示答案在每个时间步长中如何得到完善。 这使得很难评估是否正在进行逐步完善和推理,尤其是考虑到在每个时间步长所有回答单元都可获得完整的图像和问题信息,并且在测试过程中仅使用了第一个回答单元的输出 阶段。
5.6 Other Noteworthy Models
回答有关图像的问题通常可能需要信息,而这些信息无法通过分析图像直接推断出来。 了解图像中对象的用途和典型上下文对于VQA很有帮助。 例如,可以访问知识库的VQA系统可以使用它来回答有关特定动物的问题,例如它们的栖息地,颜色,大小和喂养习惯。 在[37]中探索了这个想法,他们证明了知识库提高了绩效。 外部知识库是根据DBpedia的一般信息量身定制的[72],并且有可能使用针对VQA量身定制的资源可以产生更大的改进。
在[47]中,作者将动态参数预测层合并到了CNN的完全连接层中。 通过使用递归神经网络,可以从问题中预测该层的参数。 这允许在最终分类步骤之前,模型使用的视觉特征特定于问题。 这种方法可以看作是一种隐式注意机制,因为它可以根据问题修改视觉输入。
在[53]中,为VQA提出了多模式残差网络(MRN),这是由于ResNet体系结构在图像分类中的成功所致。 他们的系统是对ResNet [2]的修改,可以在残差映射中使用视觉和问题功能。 可视和问题嵌入被允许具有其自己的带有跳过连接的剩余块。 然而,在每个残差块之后,视觉数据与问题嵌入交织在一起。 作者探索了几种用于构建具有多模式输入的残差架构的替代方案,并根据性能选择了上述网络。
5.7 What methods and techniques work better?
尽管已经提出了许多用于VQA的方法,但是很难确定哪种通用技术更好。表4提供了基于COCO-VQA评估的不同算法的细分,这些算法基于它们使用的技术和设计选择。表4还尽可能地包括来自各个算法的消融模型。烧蚀模型有助于我们确定作者做出的设计选择的个人贡献。我们可以做出的第一个观察结果是,在多种算法中,ResNet的性能均优于VGGNet或GoogLeNet。从使用相同设置并且仅更改图像表示的模型中可以明显看出这一点。在[55]中,通过使用ResNet-101而不是VGG-16 CNN可以观察到2%的图像特征增长。在[54]中,当他们对模型进行相同的更改时,他们发现增加了1.3%。同样,在[56]中,将VGG-19更改为ResNet-152可使性能提高2.3%。在所有情况下,其余架构均保持不变。
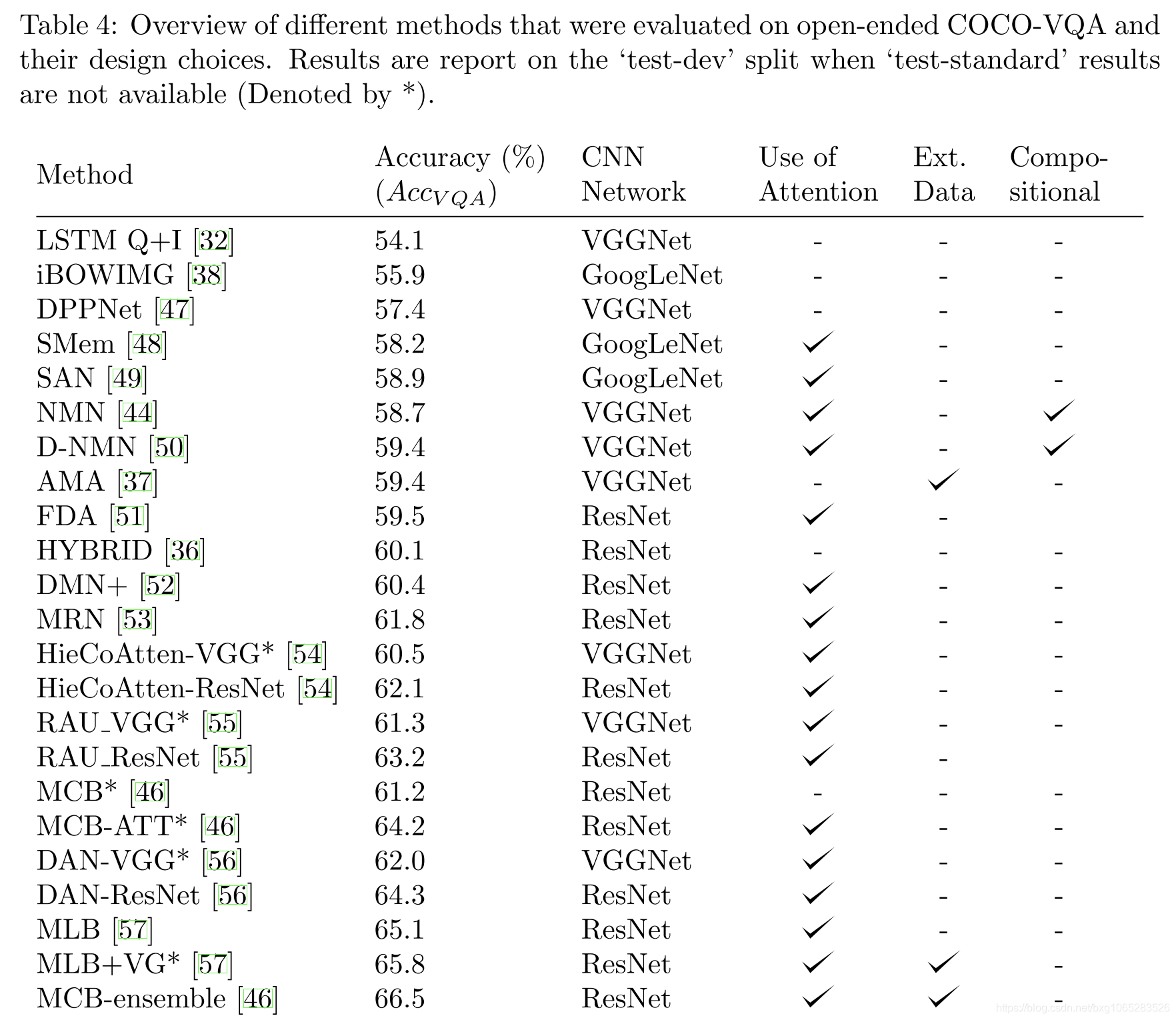
通常,我们认为可以将空间注意力用于提高模型的性能。 [46]和[54]中的实验表明了这一点,其中在有和没有注意的情况下对模型进行了评估,并且在两种情况下,细心的版本都表现更好。 但是,仅靠注意力似乎还不够。 我们将在6.2节中进一步讨论
尽管是有趣的方法,但贝叶斯和组合体系结构并未比可比模型显着改善。在[36]中,该模型仅在与MLP模型结合后才具有竞争性。目前尚不清楚该增加是否是由于模型平均或提议的贝叶斯方法引起的。同样,[44]和[50]中的NMN模型也没有优于可比的非组成模型,例如[49]。这两种方法都可能在特定的VQA子任务上表现良好,例如NMN被证明对SHAPES数据集中的位置推理问题特别有帮助。但是,由于主要数据集未提供问题类型的详细细分,因此无法量化系统如何处理特定问题类型。此外,对稀有问题类型的任何改进对整体绩效得分的影响都可以忽略不计,从而难以正确评估这些方法的优势。我们将在6.3节中进一步讨论这些问题。
6 Discussion
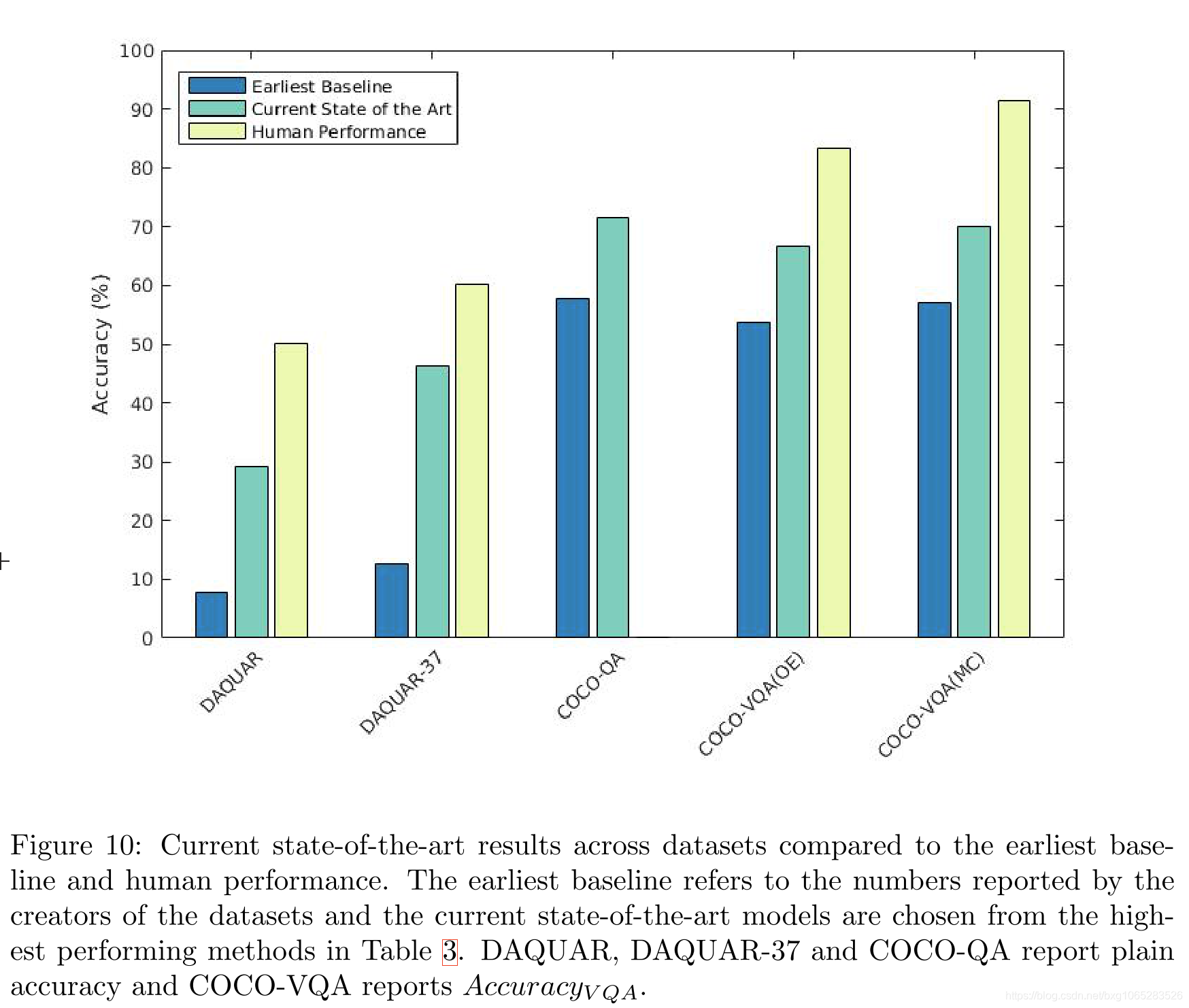
如图10所示,VQA算法的性能已经得到快速提高,但是最好的方法与人类之间仍然存在巨大差距。 尚不清楚性能的提高是来自后来系统中合并的机制,例如注意力,还是归因于其他因素。 而且,可能难以孤立地分离文本和图像数据的贡献。 由于算法评估方式的差异,比较算法也面临许多挑战。 在本节中,我们将讨论每个问题。
6.1 Vision vs. Language in VQA
VQA由两个不同的数据流组成,这些数据流需要正确使用以确保强大的性能:图像和问题。但是,当前的系统是否充分利用了视觉和语言?消融研究[36,32]常规显示,仅问题模型的性能比仅图像模型好得多,尤其是在开放式COCO-VQA上。在COCO-QA上,仅使用问题的简单图像盲模型可以实现50%的精度,而使用图像的收益则相对适中[36]。在[36]中,还表明,对于DAQUAR-37,使用更好的语言嵌入和图像盲模型产生的结果要优于采用图像和问题的早期作品。这主要是由于两个因素。首先,该问题严重地限制了在许多情况下期望的答案的种类,本质上将开放式问题变成了多项选择题,例如,有关对象颜色的问题将以颜色作为答案。其次,数据集倾向于具有强烈的偏见。这两个因素使语言比单独的图像功能更强大。
语言对图像的预测能力已通过消融研究得到证实。[73]作者研究了使用图像和问题特征训练的模型。 然后,他们研究了仅给出图像或仅给出问题时与给出两种图像时相比,模型的预测有何不同。 他们发现,仅图像模型的预测与合并模型的预测相较于仅问题模型的预测相差40%。 他们还表明,问题的措词方式强烈地使答案有偏颇。 训练神经网络时,这些规律性将被纳入模型。 虽然这可以提高数据集的性能,但可能不利于创建通用的VQA系统。
在[42]中,使用合成卡通图像研究了VQA中的偏差。 他们创建了一个仅包含二元问题的数据集,其中可以针对两个基本相同的图像询问相同的问题,除了较小的更改会导致正确答案有所不同。 他们发现,与在数据集的平衡版本上训练的模型相比,在该数据集的非平衡版本上训练的模型在平衡测试数据集上的性能(绝对差)差11%。
我们进行了两个实验,以评估语言偏见对VQA的影响。首先,我们使用[38]中的model3。该模型在COCO-VQA上进行了训练,通过将softmax输出层的权重分为图像和问题分量,可以独立评估问题和图像特征的贡献。对于这两种选择,我们都提出了先后相对相等的简单二元问题,因此必须分析图像以回答问题。示例如图12所示。我们可以看到系统性能很差,尤其是考虑到COCO-VQA的是/否问题的基线准确度约为80%时。接下来,我们研究了语言偏见如何影响在COCO-VQA上训练的更复杂的MCB集成模型[46]。该模型是2016年VQA挑战研讨会的获胜者。为此,我们创建了一个仅包含是/否问题的小型数据集。为了创建此数据集,我们使用了来自COCO数据集验证段的注释来确定图像是否包含人物,然后询问是否存在有人,是否回答相同的“是”和“否”问题。我们使用了以下问题:“照片中有人吗?”,“照片中有人吗?”和“照片中有人吗?”对于每个变体,有38,514个是/否问题(115,542)总)。此数据集上MCB集成的准确性比偶然性差(47%),这与在COCO-VQA上的结果形成鲜明对比(即在COCO-VQA是/否问题上为83%)。这可能是由于训练数据集中的严重偏差,而不是由于MCB无法学习任务。

如图11所示,VQA系统对问题的表达方式很敏感。当使用[32]中的系统时,我们观察到了相似的结果。为了量化这个问题,我们从验证COCO数据集中创建了另一个玩具数据集,并将其用于评估在COCO-VQA上训练的MCB集成模型。在此玩具数据集中,任务是识别正在玩的运动。我们问了同一个问题的三个变体:1)“他们在做什么?”,2)“他们在玩什么?”和3)“他们在玩什么运动?”每个变体都包含有关7种常见运动的5237个问题(共15,711个问题)。 MCB集成的变体1达到33.6%,变体2达到78%,变体3达到86.4%。从变体1到2的性能显着提高是由于包含关键字“ playing”而不是通用动词“ doing”从变化2到变化3的增量是由在问题中明确包含关键字“运动”引起的。这表明VQA系统过度依赖注释者经常包括的语言“线索”。总之,这些实验表明语言偏向是严重影响当前VQA系统性能的问题。
总之,当前的VQA系统比图像内容更依赖于问题。 数据集中的语言偏差会严重影响当前VQA系统的性能,从而限制了它们的部署。 新的VQA数据集必须通过补偿图像内容的问题和/或减少数据集的偏倚来努力弥补这一问题。
6.2 How useful is attention for VQA?
很难确定多少注意力可以帮助VQA算法。在消融研究中,当从模型中删除注意机制时,会损害其性能[46,54]。当前,COCO-VQA的最佳模型的确采用了空间视觉注意力[46],但是已经证明,不使用注意力的简单模型已经超过了使用复杂注意力机制的早期模型。例如,在[62]中,使用了多个全局图像特征表示(VGG-19,ResNet-101和ResNet-152)而不是单个CNN的无注意力模型,与某些注意模型相比,表现非常好。他们使用逐元素的乘法和加法来组合图像和问题特征,而不是仅仅将它们串联在一起。与合奏相结合,产生的结果明显高于[49]和[52]中使用的基于注意力的复杂模型。其他不使用空间注意力的系统,例如[36、64、53],也获得了类似的结果。仅注意不能确保良好的VQA性能,但是在不使用注意的情况下,将注意力合并到VQA模型中似乎可以提高性能。
在[74]中,作者表明,通常用于将空间注意力整合到特定图像特征上的方法不会导致模型与接受VQA任务的人员参与相同的区域。 他们使用[49]和[54]中使用的注意力机制进行了观察。 这可能是因为模型学习的区域是可区分的,这是由于数据集中的偏差,而不是由于算法应参加的区域。 例如,当问到有关窗帘中是否存在悬垂性的问题时,该算法可能会在床底而不是窗户上查看图像的底部,因为有关悬垂性的问题往往在卧室中发现。 这表明由于偏见,可能无法正确部署注意机制。
6.3 Bias Impairs Method Evaluation
数据集偏差会严重影响评估VQA算法的能力。需要使用图像内容的问题通常相对容易回答。许多关于对象或场景属性的存在。 CNN往往会很好地处理这些问题,而且语言偏见也很强烈。相对困难的问题(例如以“为什么”开头的问题)相对较少。这对评估性能具有严重的影响。对于COCO-VQA(训练和验证分区),将以“ Is”和“ Are”开头的问题的准确性提高15%的系统会将总体准确性提高5%。但是,“为什么”和“哪里”问题的增加只会使准确性提高0.6%。实际上,即使正确回答了所有“为什么”和“哪里”的问题,准确性的整体提高也仅为4.1%。另一方面,如果对所有以“是否存在”开头的问题回答“是”,则这些问题的准确性为85.2%。如果单独评估每种类型的问题,则可以克服这些问题,然后使用各种问题类型的平均准确性代替基准算法的总体准确性。这种方法类似于用于评估对象分类算法的平均每类准确性度量标准,该度量标准是由于可用于不同对象类别的测试数据量存在偏差而采用的。
6.4 Are Binary Questions Sufficient?
在VQA社区中,使用二进制(是/否或正确/错误)问题评估算法引起了广泛的讨论。 反对使用二元问题的主要论据是缺乏复杂的问题,并且相对容易回答通常由人类注释者生成的问题。 Visual Genome和Visual7W完全排除了二进制问题。 作者认为,这种选择会鼓励注释者提出更复杂的问题。
另一方面,二元问题易于评估,从理论上讲,这些问题可以包含各种各样的任务。 SHAPES数据集[44]仅使用二元问题,但包含涉及空间推理,计数和绘图推论的复杂问题(见图6)。 使用卡通图像,[42]还表明,当数据集平衡时,这些问题对于VQA算法可能特别困难。 但是,为现实世界的图像创建平衡的二进制问题面临挑战。 在COCO-VQA中,“是”比“否”更为常见,原因是人们倾向于提出偏向“是”的问题。
只要能够控制偏差,是/否问题就可以在将来的VQA基准测试中发挥重要作用,但是VQA系统应该不仅可以解决二元问题,还可以充分评估其能力。 VQA的所有实际应用程序(例如使盲人能够提出有关视觉内容的问题)都要求VQA系统的输出是开放式的。 只能处理二进制问题的系统在实际应用中会受到限制。
6.5 Open Ended vs. Multiple Choice
由于评估开放式多词答案具有挑战性,因此已提出多项选择作为评估VQA算法的方法。 只要备选方案足够困难,就可以以这种方式评估系统,然后将其部署为回答开放式问题。 由于这些原因,可以使用多种选择来评估Visual7W,Visual Genome和VQA数据集的变体。 在此框架中,算法可以访问许多可能的答案(例如,COCO-VQA为18)以及问题和图像。 然后,它必须在可能的选择中进行选择。
选择题评估的一个主要问题是,可以将问题简化为确定哪个答案是正确的,而不是实际回答问题。 例如,在[64]中,他们将VQA公式化为答案评分任务,其中训练系统根据图像,问题和潜在答案产生分数。 答案本身作为特征输入系统。 它在Visual7W上取得了最先进的结果,并与COCO-VQA上的最佳方法相媲美,其方法的性能比许多需要注意的复杂系统要好。 在很大程度上,我们认为他们的系统运行良好,因为它学会了更好地利用答案中的偏差,而不是对图像进行推理。 在Visual7W上,他们展示了他们系统的一个变体,该变体仅使用答案,并且在使用问题和图像的情况下,图像和问题盲的基线都可以与之匹敌。
我们认为,任何VQA系统都应该能够运行,而不会得到输入的答案。 多项选择可能是评估多词答案的重要因素,但仅凭它是不够的。 当使用多项选择时,必须仔细选择选项,以确保问题很难解决,并且不能仅从提供的答案中得出。 完全能够使用提供的答案进行操作的系统并不能真正解决VQA,因为在部署系统时这些功能不可用。
7 Recommendations for Future VQA Datasets
现有的VQA基准还不足以评估算法是否已“解决” VQA。 在本节中,我们讨论VQA数据集的未来发展,这将使它们成为解决问题的更好基准。
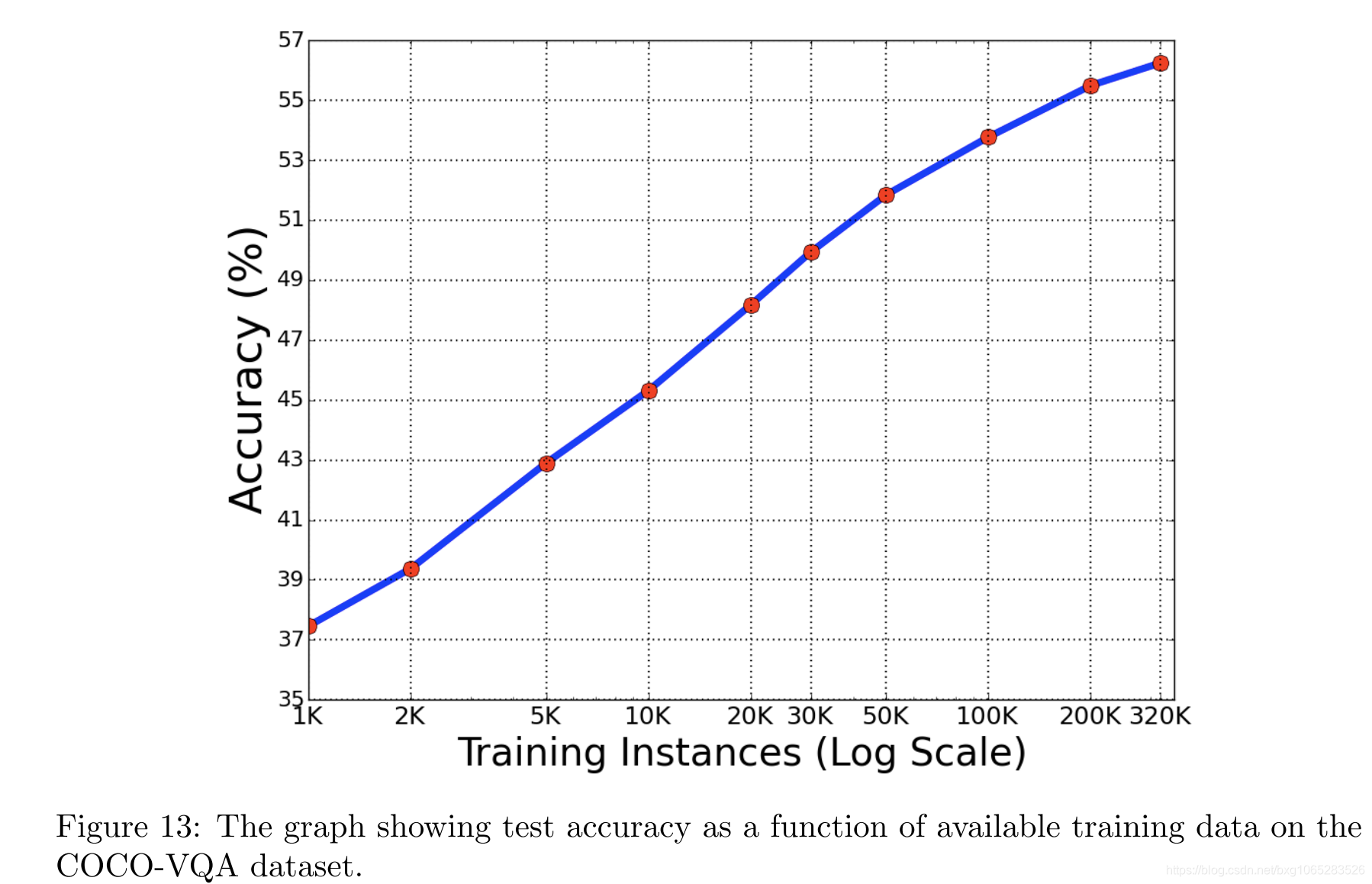
未来的数据集需要更大。 尽管VQA数据集的规模和多样性不断增长,但是算法没有足够的数据用于训练和评估。 我们进行了一个小实验,其中使用ResNet-152图像特征和跳过问题的特征为VQA训练了简单的MLP基线模型,并根据COCO-VQA上可用的训练数据量对性能进行了评估。 结果如图13所示,很明显,曲线尚未开始接近渐近线。 这表明即使在有偏差的数据集上,增加数据集的大小也可以显着提高准确性。 但是,这并不意味着增加数据集的大小足以使其成为一个良好的基准,因为人类倾向于提出带有强烈偏见的问题。
未来的数据集需要减少偏差。 在本文中,我们反复讨论了现有VQA数据集中的偏差问题,并指出了这些偏差导致真正评估VQA算法的问题种类。 对于现实世界的开放式VQA,如果不仔细指导产生问题的人员,将很难实现这一目标。 长期以来,偏向一直是用于计算机视觉数据集的图像中的问题(有关评论,请参见[75]),而对于VQA,该问题也由于问题的偏见而变得更加复杂。
除了更大,更少偏见之外,未来的数据集还需要进行更细微的分析以进行基准测试。所有公开发布的数据集都使用评估度量标准,以相等的权重对待每个问题,但是由于偏见或因为现有算法擅长回答此类问题(例如对象识别问题),因此某些类型的问题要容易得多。某些数据集(例如COCO-QA)已将VQA问题划分为不同的类别,例如,对于COCO-QA,这些是颜色,计数(数字),位置和对象。我们认为,每个问题的平均表现应该代替标准的准确性,因此每个问题在评估表现时都不会具有同等的权重。这将使VQA算法必须在各种问题类型上都必须表现出色才能总体上表现良好,否则将有很长的路要走,否则,在回答“为什么”问题方面表现出色但在更常见的问题上要比另一种模型稍差的系统没有得到公正的评估。为此,需要为每个问题分配一个类别。我们相信这项工作将使基准测试结果变得更加有意义。每种问题类型的分数也可用于比较算法,以查看它们擅长的问题类型。
8 Conclusions
VQA是计算机视觉和自然语言处理中一个重要的基础研究问题,它要求系统执行比任务特定算法(例如对象识别和对象检测)更多的工作。 可以回答有关图像的任意问题的算法将是人工智能的里程碑。 我们认为,VQA应该是任何视觉图灵测试的必要部分。
在本文中,我们严格审查了VQA的现有数据集和算法。 我们讨论了评估算法所产生答案的挑战,尤其是多词答案。 我们描述了偏见和其他问题如何困扰现有数据集。 这是一个主要问题,该领域需要一个评估VQA算法重要特征的数据集,因此,如果算法在该数据集上表现良好,则意味着它在VQA上总体上表现良好。
关于VQA的未来工作包括创建更大,更多样的数据集。 这些数据集中的偏差将很难克服,但是以细微的方式分别评估不同类型的问题,而不是仅使用幼稚的准确性,将大有帮助。 需要进一步的工作来开发可以推断图像内容的VQA算法,但是这些算法可能会导致重要的新研究领域。

















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









