






SIMD即单指令多数据流(Single Instruction Multiple Data)指令集,是通过一条指令同时对多个数据进行运算的硬件加速技术,在传统计算,中使用标量运算一次只能对一对数据执行乘法操作,但是如果使用了SIMD加速,可同时对多对数据进行执行操作,常见的有x86体系下的sse/avx等

传统标量计算:
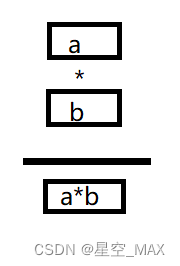
SIMD加速计算:
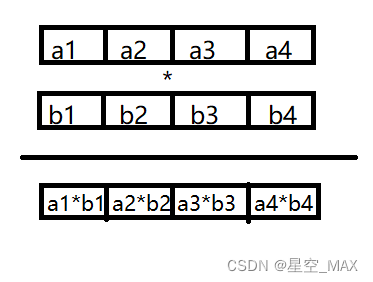
这个过程和现代GPU计算有着相通之处,极大的利用并行计算能力
这个过程及其相似与向量计算过程,数据组织的时候,尽量将数据组织成纵向化或者向量化
同样一条指令下面,并行进行了四个乘法计算,这一过程可以大大加速运算流程,在go语言源码中利用了大量该类计算方法
间隔简单的使用方法:
#include<stdio.h>
#include<emmintrin.h>
int main()
{
__m128 v1 = _mm_set_ps(1.0f, 2.0f, 3.0f, 4.0f);
__m128 v2 = _mm_set_ps(5.0f, 6.0f, 7.0f, 8.0f);
__m128 result = _mm_add_ps(v1, v2);
printf("%f,%f,%f,%f",result[3],result[2],result[1],result[0]);
}下面将举个例子利用流水线加速128组浮点数的加运算,来看看没有加速下的运行效率和使用SIMD优化下的效率
传统方式实现10000次128组浮点数的加法:
#include<iostream>
#include <chrono>
#define FNUM 128
int main()
{
clock_t start,end;
static_assert(FNUM%4==0, "error");
float data0[FNUM];
float data1[FNUM];
float data2[FNUM];
std::chrono::steady_clock::time_point now = std::chrono::steady_clock::now();
for(int x=0;x<10000;++x)
{
for(int i=0;i<FNUM;++i)
{
data2[i]=data1[i]+data0[i];
}
}
auto t2 = std::chrono::steady_clock::now();
std::chrono::duration<double> time_span = std::chrono::duration_cast<std::chrono::duration<double>>(t2 - now);
std::cout<<time_span.count()<<std::endl;
}
由于现代计算机速度非常快,所以将这个过程执行10000次,以获取更加准确的时间
时间如下:

通过SIMD实现10000次128组浮点数的加法:
#include<iostream>
#include <chrono>
#include<emmintrin.h>
#define FNUM 128
using namespace std;
using namespace std::chrono;
int main()
{
static_assert(FNUM%4==0, "error");
float data0[FNUM];
float data1[FNUM];
float data2[FNUM];
int step=FNUM/4;
std::chrono::steady_clock::time_point now = std::chrono::steady_clock::now();
for(int i=0;i<10000;i++)
{
for(int i=0;i<step;++i)
{
__m128 v1 = _mm_set_ps(data0[i*step+0],data0[i*step+1],data0[i*step+2],data0[i*step+3]);
__m128 v2 = _mm_set_ps(data1[i*step+0],data1[i*step+1],data1[i*step+2],data1[i*step+3]);
__m128 result = _mm_add_ps(v1, v2);
}
}
auto t2 = std::chrono::steady_clock::now();
std::chrono::duration<double> time_span = std::chrono::duration_cast<std::chrono::duration<double>>(t2 - now);
std::cout<<time_span.count()<<std::endl;
}
时间如下:

流水线加速和传统方法一样可能的原因:
在一些情况下,使用了流水线加速后计算速度可能会一样变得比原来更慢,原因在于现代编译器完成了大量优化工作,可能一些计算被编译器已经处理为了SIMD,所以会变得非常快














 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









