






近期EAGLE-3发布,大模型推理加速能力更上一层楼。此工作是EAGLE系列的延展,所以本文主要对EAGLE等大模型推理加速方案做简单梳理,然后再介绍EAGLE-3的改进思路与效果
EAGLE-3论文地址
https://arxiv.org/pdf/2503.01840
发布日期
2025-03-03
代码地址
https://github.com/SafeAILab/EAGLE
动机
主流大语言模型通过自回归依次产生每个输出token,所以推理阶段的计算效率非常低下。人们希望适当打破自回归模式,让大模型一次突出多个token,从而缩短推理时间,更快地拿到输出结果
投机算法
目标模型:需要生成最终推理的大模型
草稿模型:一个尺寸更小的模型
-
先把当前query输入草稿模型,让其快速生成“草稿”
-
让目标模型并行地检查草稿,判断每个token是否可以被接受
包括EAGLE系列在内,本文所介绍的推理加速方法都符合上述投机算法框架。最原始的投机算法是一种链式结构:

至于选择什么模型作为草稿模型,可以选择一个相同类型但尺寸更小的模型,比如目标模型是llama2-70B,可选用llama2-7B来打草稿:

更简单地,可以直接使用N-gram模型来做简单的推理,

在整个过程中,有以下几个环节影响推理耗时:
-
草稿模型生成草稿的速度
-
目标模型计算草稿token概率的速度
-
草稿token被接受的比率
多头美杜莎机制与树形Attention
投机算法问世以来,如何选择合适的草稿模型成为了实际应用中的难点,我们往往难以在【快速生成】和【结果准确】之间找到平衡:
使用小尺寸大模型来实现的投机算法,草稿模型的推理开销依然很大,并且市面上大模型的尺寸都是固定的,可选范围较少(如果目标模型本身就是7B的,未必能找到更小的如1B尺寸的同类模型);
而lookahead方法虽然效率更高但草稿的接受率较低,总是需要重新采样,加速效果不理想
美杜莎算法的出发点在于:不再去寻找一个新的草稿模型,而是在目标模型的基础上,增加一些输出头来打草稿,如下图所示:

接下来需要使用目标模型从这些候选结果中挑选出概率最大的一条路径。乍一看这个任务和自回归解码很像,需要多次调用目标模型确定每个位置的token
但实际上多头美杜莎使用了【树形Attention】来一次性地生成每条路径的概率,极大地提高了验证草稿token的速度:
-
从第2个位置开始,把每个位置的所有候选重复m次,m的取值为此位置之前的路径数量。例如位置1的候选是[it, i],位置2的候选是[is, ', the],位置2需要重复两次,因为位置1存在两种取值,得到[is, ', the, is, ', the]
-
将上述候选token拉平成一维序列,得到[it, i, is, ', the, is, ', the],输入到目标模型计算attention并应用以下掩码,最终得到各条路径的概率

总之,美杜莎机制通过复用目标模型的高层特征,避免了去挑选草稿模型(但需要对新加的那几个输出头做微调),并且草稿token更容易被目标模型接受;通过同时预测不同位置的token加快了生成草稿的速度;通过树形注意力提高了目标模型做验证的速度
EAGLE
EAGLE也是一种较新的投机算法,主要有两个出发点:
-
相比于让草稿模型直接预测next token,让草稿模型预测next feature会更容易,因为token是feature离散采样后的结果(把概率分布变成了一个确切的值),存在很多信息损失
-
每个feature的具体分布,不仅取决于上一个feature,还取决于上一个feature的采样结果。也就是说,虽然采样过程损失了信息,但也做了一次“拍板”,敲定了最终输出哪个token。如果缺少这个拍板环节,那么输入的feature便存在歧义,每个位置都可能会产生更多候选token,产生更多路径分支

如下图所示,相比于美杜莎,EAGLE在目标模型的隐藏层后面接的自回归头是预测feature的,而不是直接预测token;预测出来的token会再经过一个解码头生成最终的token分布,并采样出top-k个结果

同样地,EAGLE也使用了树形attention来加速验证。这里与美杜莎机制的不同在于,美杜莎通过多个解码头同时预测多个位置的token,而EAGLE做的还是自回归任务,不需要组合路径

所以EAGLE直接把候选结果拉平便可得到attention矩阵,不用再做重复
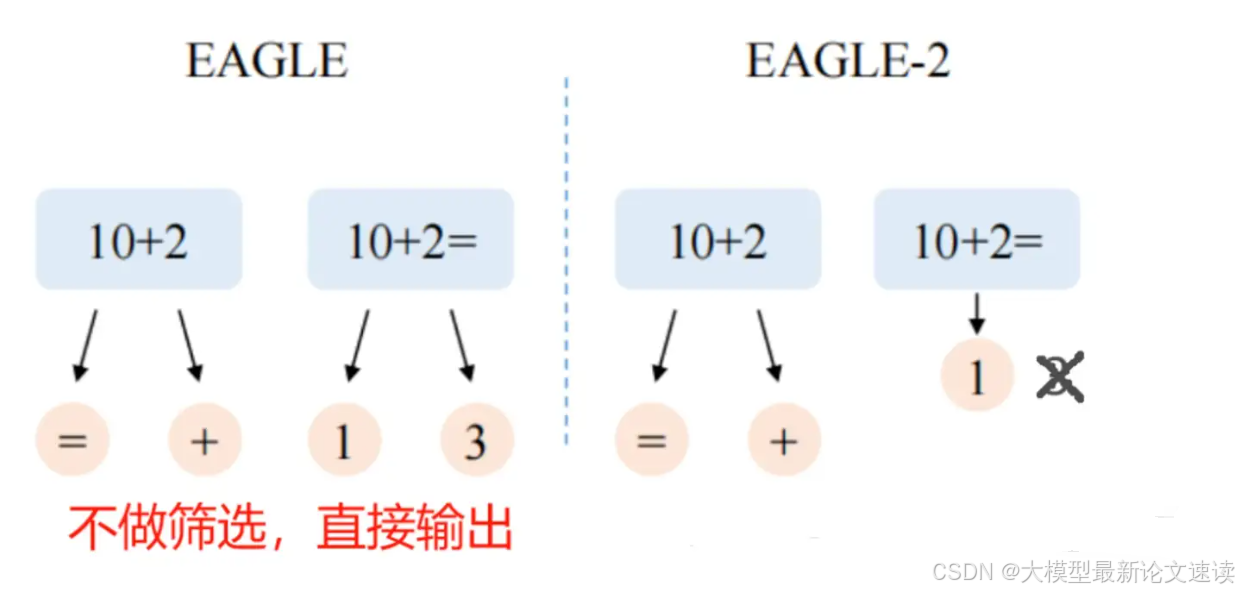
EAGLE2
EAGLE2主要是把EAGLE中的静态草稿树改成了动态草稿树,删除了一些草稿模型自己都认为不自信的结果
EAGLE3
EAGLE3主要有以下几点改进:
-
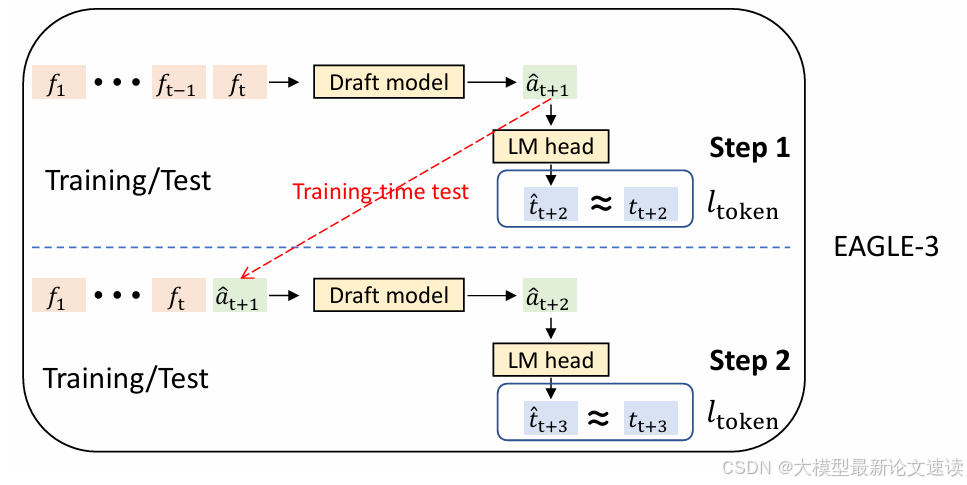
尽管next feature预测任务可能比较容易,但要求草稿模型去拟合目标模型的隐藏层是一种限制,导致在训练数据扩增时,草稿模型的表达能力没能得到相应提升,所以又改回了next token预测;
-
此后,草稿模型的隐藏层将不再与目标模型的隐藏层同分布,于是从第二步开始,模型的输入出现了偏差

此时便需要修改微调任务:把每一步模型推理时产生的feature,添加到下一步的输入中,而非全部使用目标模型产生的feature,从而让模型在训练时便适应新的分布
- 最后一个隐藏层的feature代表的是高层理解结果,可能对低层细节的理解不够,所以还concat了目标模型的中、低层feature作为草稿模型的输入

从最终效果来看,EAGLE-3的加速比和接受率相比EAGLE-2都有明显提升,并且草稿模型的训练数据量越大,加速效果越好,这在之前的工作中从未出现过

各方法效果对比


















 535
535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









