







1、eagle
1.1 背景
自回归解码是大型语言模型(LLM)的实际标准,它按顺序生成标记,导致生成速度慢且成本高。基于推测采样的方法(Leviathan 等人,2023;Chen 等人,2023a)通过将过程分为低成本草稿阶段和对草稿标记的并行验证阶段来解决这个问题,允许在单个 LLM 传递中验证多个标记。这些方法通过每传递生成多个标记来加速生成。更重要的是,验证阶段确保文本分布与原始 LLM 的解码结果完全一致,从而保持生成内容的完整性。
应用推测性采样的关键在于找到一个与原始LLM功能相似的草稿模型,但延迟更低,通常涉及来自同一LLM系列的更低参数版本。使用7B模型作为70B模型的草稿模型是有效的,而为最小的7B变体找到合适的草稿模型则很棘手。尽管7B模型有潜力作为草稿模型,但其高开销降低了加速收益。专门为推测性采样训练一个新的、大小合适的草稿模型也不是一个理想的解决方案,因为成本太高。
在推测性采样中提高加速的关键在于减少时间开销并提高原始 LLM 对草稿的接受率(Chen 等人,2023b;Xia 等人,2023;Santilli 等人,2023)。许多方法都集中于减少草稿阶段的开销。前瞻(Fu 等人,2023)采用 n 元语法和雅可比迭代,而 Medusa(Cai 等人,2023)则利用一组 MLP,根据原始 LLM 的第二层特征预测标记。这些策略显著降低了生成草稿的延迟,从而提高了加速。然而,它们的有效性受到生成草稿准确率较低的影响,Medusa 的准确率约为 0.6,而前瞻的准确率更低。相比之下,我们的方法达到了约 0.8 的准确率。
备注:与medusa比,草稿模型更准确、速度更快
为了克服这些局限性,我们引入了 EAGLE(用于提高大型语言模型效率的推断算法),这是一种高效的推测性采样方法,它基于以下两个观察结果。
首先,在特征层面上进行自回归比在词元层面上更简单。在本文中,“特征”指的是原始LLM的倒数第二层特征,位于LM头之前。与自然语言的简单变换词元序列相比,特征序列表现出更高的规律性。在特征层面上进行自回归处理,然后使用原始LLM的LM头推导出词元,比直接自回归预测词元效果更好。如图4所示,自回归预测特征可以获得更好的性能,表现为更高的加速比。
其次,采样过程固有的不确定性极大地限制了预测下一个特征的性能。如图3所示,对不同标记(如“am”或“always”)进行采样会导致不同的特征序列,从而在特征级自回归中引入歧义。Medusa在预测间隔标记时也面临类似问题,它不确定输入FI的真实目标应该是Pam还是Palways。为了解决这个问题,EAGLE将来自提前一步的时间步的标记序列(包括采样结果)输入到草稿模型中。在图3所示的示例中,这涉及到基于FI和Talways预测Falways,以及基于FI和Tam预测Fam。如图4所示,通过解决不确定性问题,加速比从1.9倍进一步提高到2.8倍。
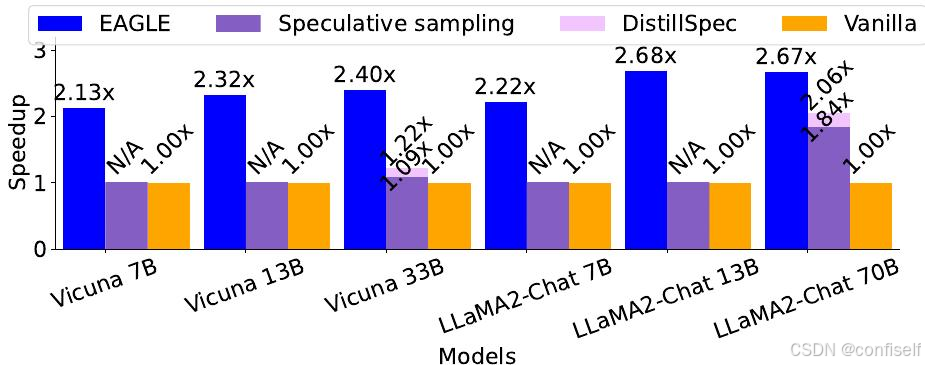
图4
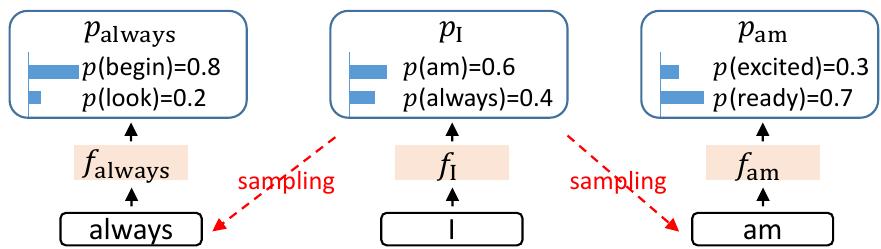
Figure 3: Uncertainty in feature sequences. The next feature following fI is contingent on the sampling outcome and cannot be determined solely based on fI , where both “always” and “am” are possible to follow the token “I” and lead to two branches.
图 3:特征序列中的不确定性。紧随 fI 的下一个特征取决于采样结果,不能仅根据 fI 确定,其中“always”和“am”都可能跟随“I”并导致两个分支。
1.2 优势
EAGLE 拥有较低的训练成本。对于 LLaMA2-Chat 70B 模型,EAGLE 使用不超过 70k 个来自 ShareGPT 数据集的对话来训练一个参数量少于 10 亿的参数的解码器层。训练在 4x A100 (40G) GPU 上完成,耗时 1-2 天。EAGLE 在 7B、13B 和 33B 模型上的训练甚至可以在一个 RTX 3090 节点上完成,耗时 1-2 天。在实际应用中,EAGLE 仅需一次训练即可为每个查询提供加速。随着查询数量的增加,EAGLE 的摊销训练成本变得可以忽略不计。
The method adds only a lightweight plug-in (a single transformer decoder layer) to the LLM, which can be easily deployed in a production environment
该方法仅在大型语言模型中添加了一个轻量级插件(一个单一的 Transformer 解码器层),该插件可以轻松部署在生产环境中。
可靠性:EAGLE 不涉及对原始 LLM 的任何微调,并且理论上保证了 EAGLE 在贪婪和非贪婪设置下都能够保留输出分布。这与 Lookahead 和 Medusa 形成鲜明对比,它们要么只关注贪婪设置,要么不能保证在这些设置下保留分布。
1.3 方法


eagle也使用了推测采样的方法,区别点在于草稿模型和他们不一样。
EAGLE 与其他基于推测性采样的方法一致,包含草稿阶段和验证阶段。
1.3.1 起草阶段
EAGLE 与其他方法的主要区别在于草稿阶段,如图5所示。
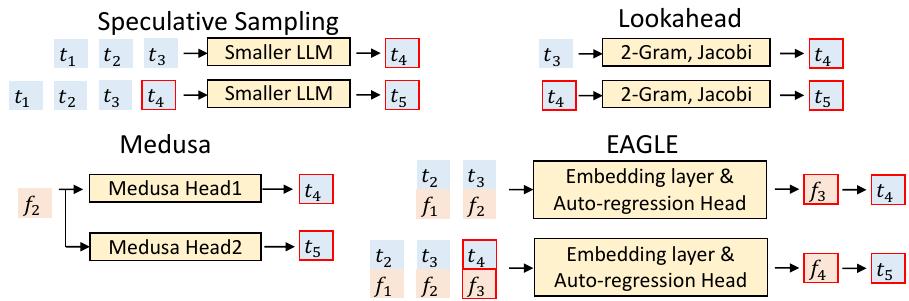
Figure 5: A comparison of the methods for drafting the fourth
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1009
1009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









