






论文标题
DEL:Context-AwareDynamic Exit Layer for Efficient Self Speculative Decoding
论文地址
https://arxiv.org/pdf/2504.05598
作者背景
南加州大学
往期相关文章
大模型推理加速: 使用多个异构的小模型加快投机解码
压缩率90%效果依然坚挺?通过蒸馏kv-cache降低部署成本
大模型推理加速:动态调整每个token的计算深度
大模型推理加速:EAGLE-3介绍
动机
大模型采用自回归解码逐个生成token,导致推理速度缓慢以及计算资源的浪费。“投机解码”旨在先用一个小模型生成推理草稿,然后由原始大模型并行验证每个token,从而显著提高速度。往期文章中有详细介绍
早期的投机解码需要维护两个模型,带来了额外开销,“自投机解码”(如LayerSkip)方法则是利用大模型自身的前几层来生成草稿,再用剩余层进行验证,不需额外模型,节省了计算和内存。
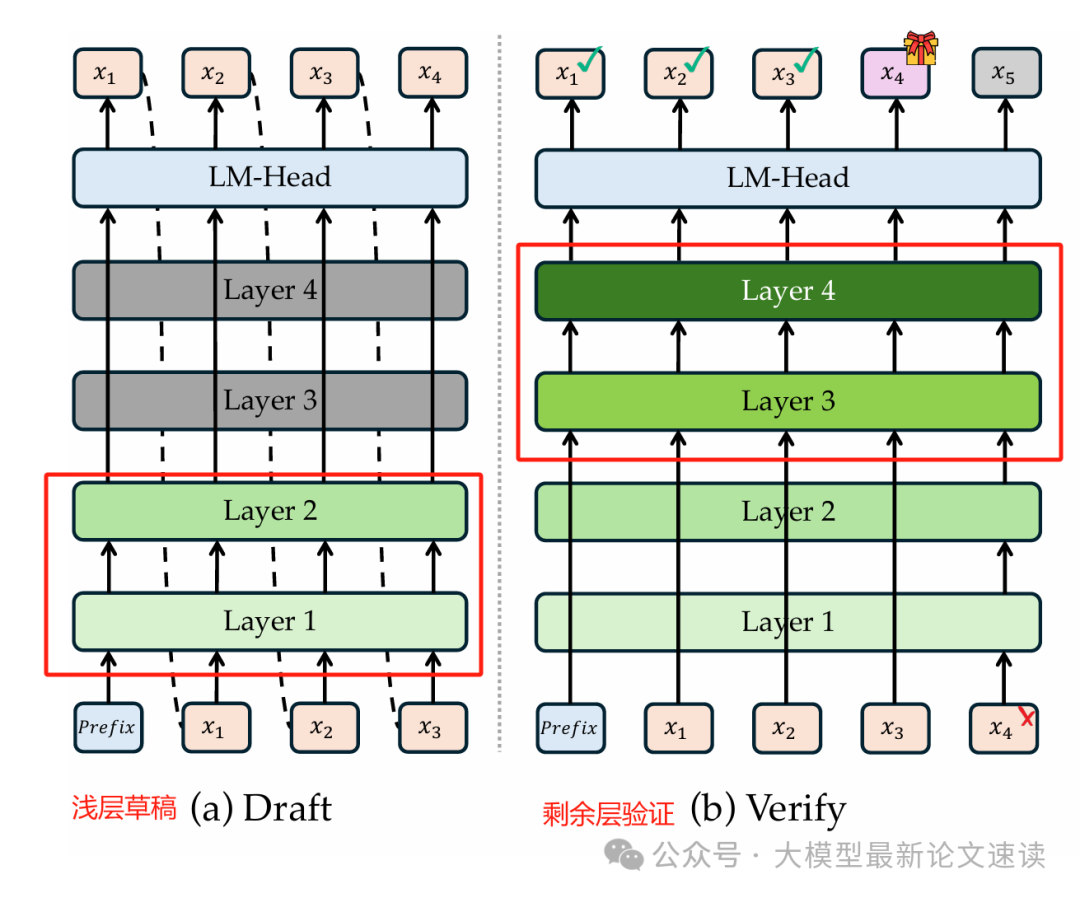
但现有方法中,使用多少层(退出层E)来草拟、每轮草拟几个token(投机长度γ)都是固定的超参数,对不同任务、不同输入,甚至同一个输入的不同生成阶段的适应性欠佳,导致了明显的性能浪费或准确性下降
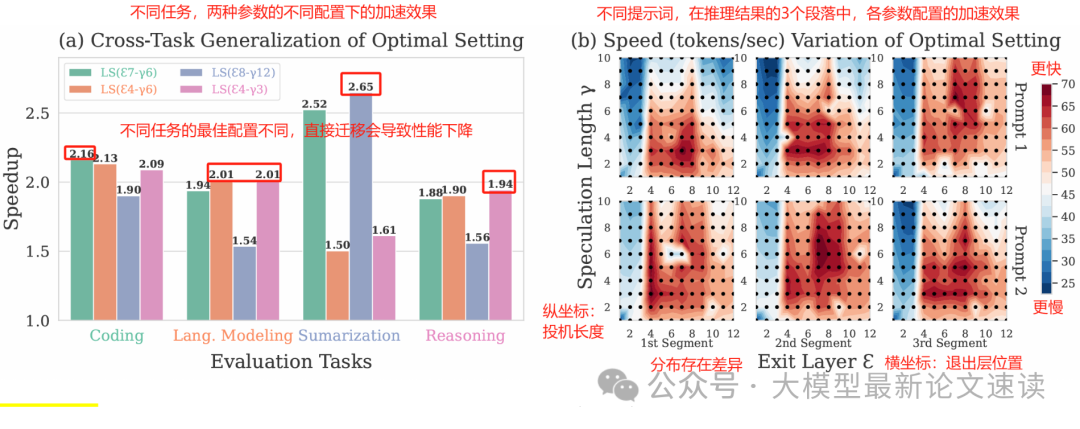
因此,本文希望提出一种能根据当前上下文自动调整退出层和投机长度的方法,最大化加速效果。
本文方法
本文提出DEL(Dynamic Exit Layer,动态退出层),能够实现最佳退出层E和投机长度γ的动态选择,并且不需要额外训练,只需在推理阶段简单添加计算逻辑即可:
一、Token-per-Layer指标
DEL定义TPL为每次投机轮中生成token数量除以使用的总层数,用以衡量整体解码效率。由于使用更浅的退出层草拟可以减少每个token经过的层数、而增加一次性生成的token数量,TPL能综合反映“跳过部分层带来的加速”与“可能增加验证开销”的权衡
二、生成影子token
在每轮草拟和验证时,模型其实计算出所有层的hidden(草拟时用到了前E层,验证用到了剩余层),把每一层的hidden送入llm头,便可同时得到所有可能的退出层在产生的候选token序列,被称为“影子token”。将这些各层的shadow tokens与真正通过完整模型验证后的最终输出tokens进行比较,便可估计出当前上下文中每层输出被接受的概率α
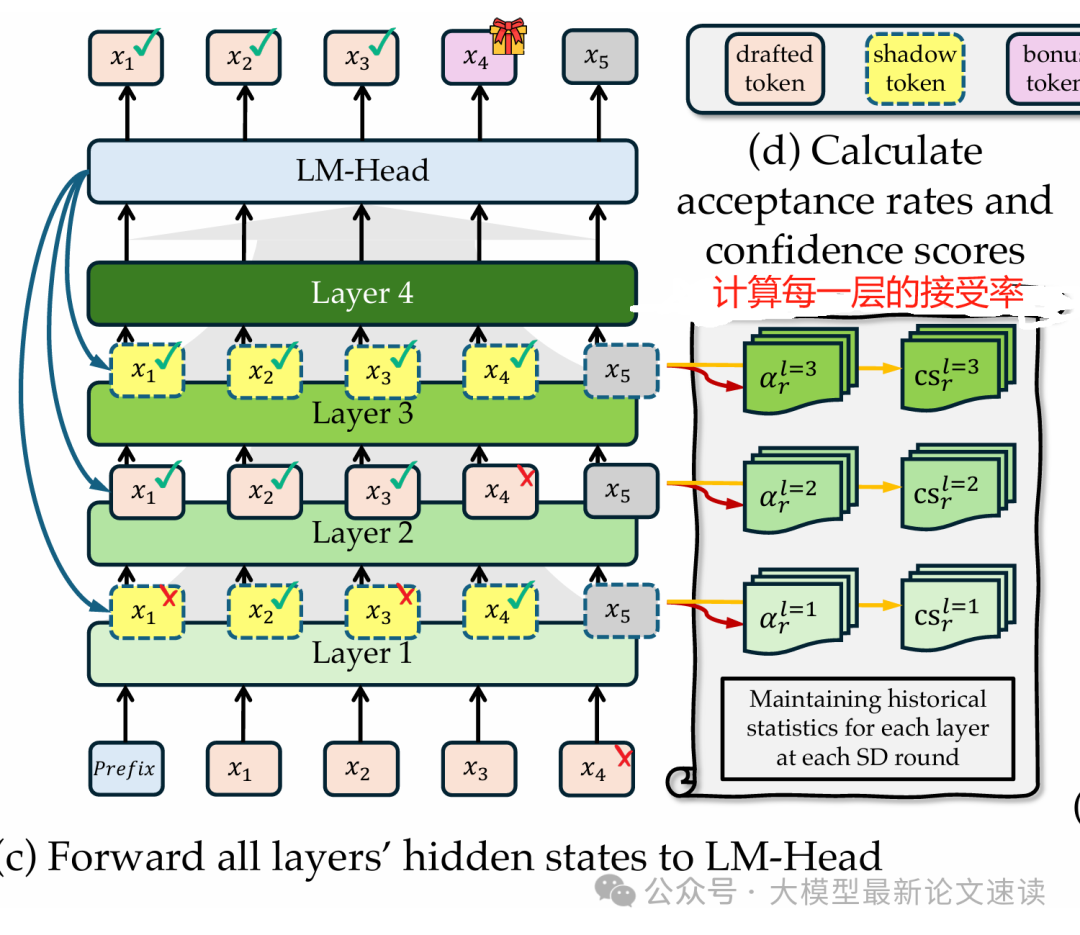
三、动态更新接受率
考虑到上下文会逐渐变化,DEL采用加权移动平均来动态更新α:近期的权重更高,早期的权重逐渐衰减。随着生成推进,如果模型发现某层最近草拟成功率提高(比如输出模式变简单),对应的α会上升;反之如果频频出现错误,α会下降
四、动态置信阈值
在草拟token时,模型会给出一个概率分布,最高概率对应的候选token的概率可视为置信度。如果置信度低于阈值τ,则提前终止草拟;反之只要置信度高于阈值,就继续写草稿。这个阈值τ不是固定不变的,而是根据以往经验动态调整:DEL同时记录历史草拟token被接受时的平均置信度,以及被拒绝时的平均置信度,并采用与α类似的加权更新策略计算出一个介于两者之间的动态阈值τ。当最近出现多次“高置信度却被拒绝”的情况时,阈值会升高(变得更谨慎);如果大部分高置信度token都顺利通过验证,而只有低置信度token才出错,阈值会适当降低以允许更加激进的草拟
在每轮投机解码中,DEL实时选择能使TPL最大化的退出层和投机长度组合(E, γ)。在实际草拟阶段,每生成一个token,DEL都会实时检查置信度,若低于阈值则提前进入验证阶段,确保效率与准确性兼顾。
实验结果
对比基线:
- Vanilla
标准的自回归解码方法,无加速。 - LS(E-γ)
LayerSkip方法,固定退出层E和静态推测长度γ。 - FS(E-γ)
LayerSkip变体,固定退出层E和动态推测长度。 - DV(E)
LayerSkip变体,固定退出层E,动态调整推测长度以维持目标接受率。
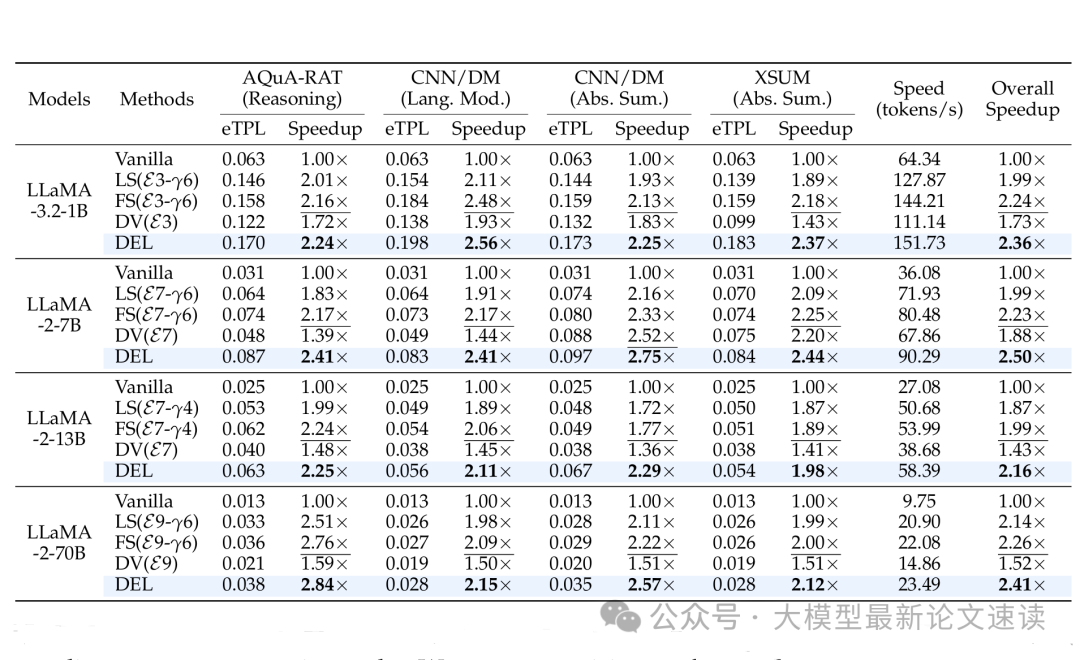
DEL在所有模型和任务上均实现了显著的速度提升,与自回归解码相比,速度提升最高可达2.84倍
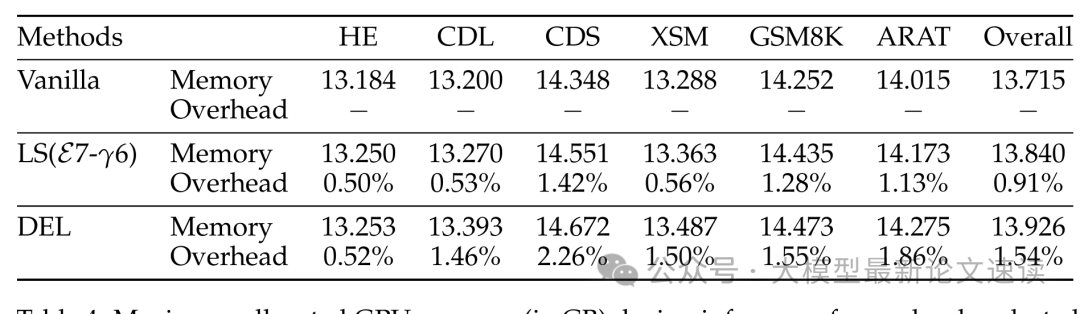
同时,DEL引入的内存开销很小,平均仅为1.54%,这表明DEL在保持高效解码的同时,不会显著增加内存使用量。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









