






1、提取收件名和发件名
首先我们需要将所有的文件提取出来,转化为字典模式,id对应姓名和真实身份,最后提取的emails.MetadataTo和emails.MetadataFrom要对应其真实身份。
import pandas as pd
import networkx as nx
import numpy as np
from collections import defaultdict
import matplotlib.pyplot as plt
# 数据加载
emails = pd.read_csv("./input/Emails.csv")
# 读取别名文件
file = pd.read_csv("./input/Aliases.csv")
aliases = {}
for index, row in file.iterrows():
aliases[row['Alias']] = row['PersonId']
# 读取人名文件
file = pd.read_csv("./input/Persons.csv")
persons = {}
for index, row in file.iterrows():
persons[row['Id']] = row['Name']
# 针对别名进行转换
def unify_name(name):
# 姓名统一小写
name = str(name).lower()
# 去掉, 和@后面的内容
name = name.replace(",", "").split("@")[0]
# 别名转换
if name in aliases.keys():
return persons[aliases[name]]
return name
# 将寄件人和收件人的姓名进行规范化
emails.MetadataFrom = emails.MetadataFrom.apply(unify_name)
emails.MetadataTo = emails.MetadataTo.apply(unify_name)2、图像的准备函数
利用nexworkx画图:边,点和标签的大小,图像可视化
# 画网络图
def show_graph(graph, layout='spring_layout'):
# 使用Spring Layout布局,类似中心放射状
# - circular_layout:节点在一个圆环上均匀分布
# positions = nx.spring_layout(graph)
if layout == "circular_layout":
positions = nx.circular_layout(graph)
else:
positions = nx.spring_layout(graph)
# 设置网络图中的节点大小,大小与pagerank值相关,因为pagerank值很小所以需要*20000
nodesize = [x['pagerank'] * 20000 for v, x in graph.nodes(data=True)]
# 设置网络图中的边长度 (1, 2, {'weight': 100000}) -> e[2]['weight'] = 100000
# edgesize = [np.sqrt(e[2]['weight']) for e in graph.edges(data=True)]
# 绘制节点
nx.draw_networkx_nodes(graph, positions, node_size=nodesize, alpha=0.4)
# 绘制边 width=edgesize,
nx.draw_networkx_edges(graph, positions, alpha=0.2)
# 绘制节点的label
nx.draw_networkx_labels(graph, positions, font_size=10)
# 输出希拉里邮件中的所有人物关系图
plt.show()3、权重的设置与遍历
# 设置边的权重等于发邮件的次数
edges_weights_temp = defaultdict(list)
for row in zip(emails.MetadataFrom, emails.MetadataTo, emails.RawText):
temp = (row[0], row[1])
if temp not in edges_weights_temp:
edges_weights_temp[temp] = 1
else:
edges_weights_temp[temp] = edges_weights_temp[temp] + 1
# 转化格式 (from, to), weight => from, to, weight
edges_weights = [(key[0], key[1], val) for key, val in edges_weights_temp.items()]4、最后利用pagerank和graph设置
# 创建一个有向图
graph = nx.DiGraph()
# 设置有向图中的路径及权重(from, to, weight)
graph.add_weighted_edges_from(edges_weights)
# 计算每个节点(人)的PR值,并作为节点的pagerank属性
pagerank = nx.pagerank(graph)
# 获取每个节点的pagerank数值
pagerank_list = {node: rank for node, rank in pagerank.items()}
# 将pagerank数值作为节点的属性
nx.set_node_attributes(graph, name='pagerank', values=pagerank_list)
# 画网络图
show_graph(graph)5、设置PR值的阈值,筛选大于阈值的重要核心节点
pagerank_threshold = 0.005
# 复制一份计算好的网络图
small_graph = graph.copy()
# 剪掉PR值小于pagerank_threshold的节点
for n, p_rank in graph.nodes(data=True):
if p_rank['pagerank'] < pagerank_threshold:
small_graph.remove_node(n)
# 画网络图
show_graph(small_graph, "circular_layout")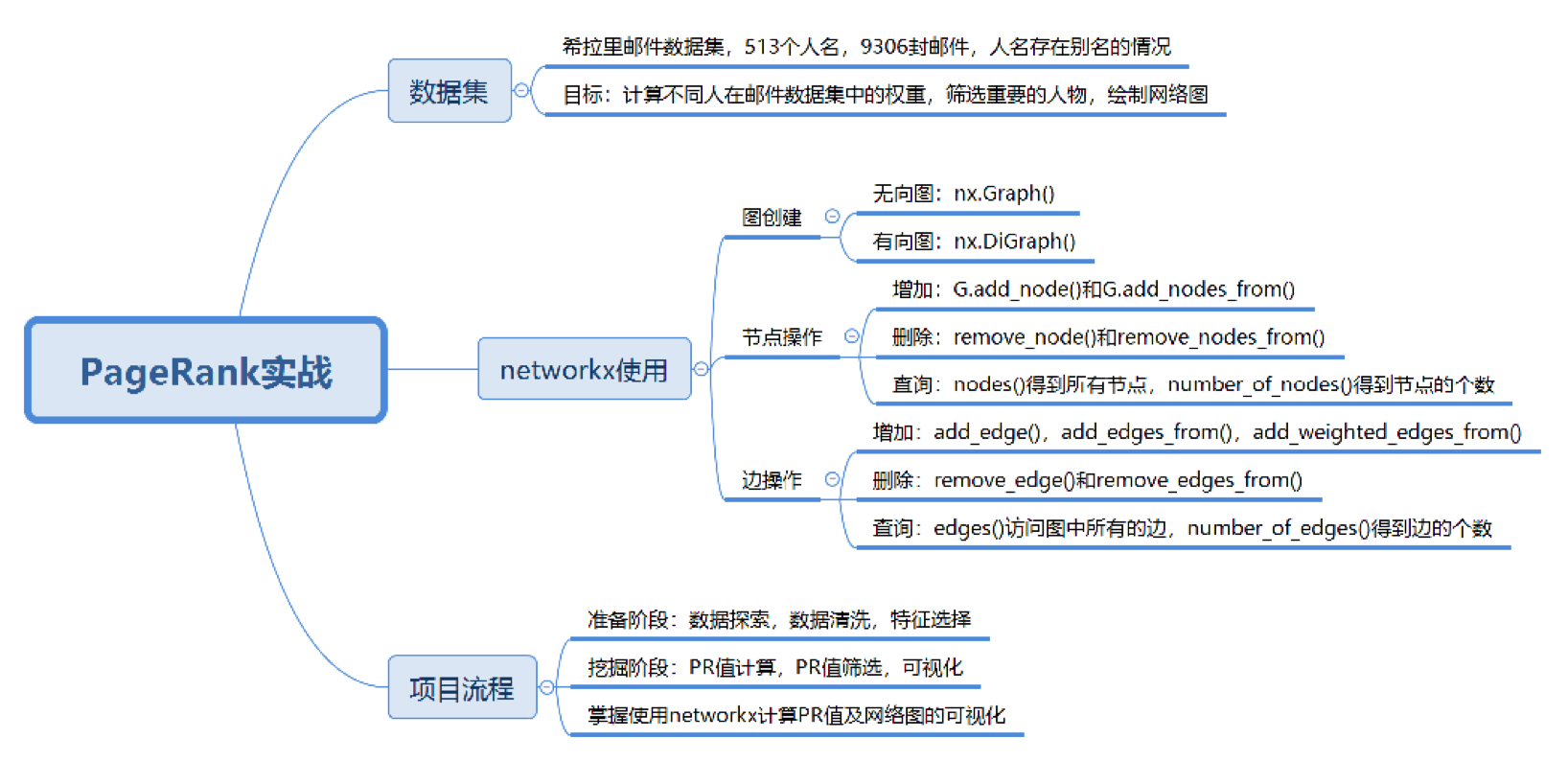















 5278
5278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









