






给小老板干活用到,想找找相关帖子发现很少,故开贴记录
摘要:
CFR是解决大型非完美信息博弈的主要框架。它通过迭代遍历博弈树收敛到均衡。为了处理规模非常大的博弈,通常在运行CFR之前使用抽象。抽象的游戏常用表格型CFR解决,它的解决方案被映射回完整的游戏。这个过程可能是有问题的,因为抽象的方面通常是手动的和需要专业知识的,抽象算法可能会错过博弈重要的细微差别,还有一个鸡和蛋的问题,因为确定一个好的抽象需要提前了解博弈的均衡。本文介绍了深度反事实遗憾最小化,一种CFR形式,通过使用深度神经网络来近似CFR在整个游戏中的行为,从而避免了对抽象的需要。深度CFR是有原则的,并在大型扑克牌游戏中取得了强大的性能。这是CFR在大型游戏中取得成功的第一个非表格变体。
常见符号及传统CFR的定义见论文,不再赘述。
DeepCFR的目标是近似于CFR的行为,而不需要在每个信息集上计算和积累遗憾,而是通过深度神经网络在类似信息集上进行泛化。
DeepCFR包含价值网络以及策略网络,价值网络V输入为,输出V(I,a)。我们希望V(I,a)与CFR的遗憾值R(I,a)接近。
策略网络的输出近似于平均策略,使用独立的空间存储每个玩家的采样信息集概率向量。
如果迭代次数和每个价值网络模型较小,可以不用训练最后的策略网络而是保存每次迭代的价值网络。在实际的训练中,随机抽样价值网络,玩家基于网络生成的策略进行博弈。这消除了最终平均策略网络的函数逼近误差,但需要存储所有先验的价值网络。
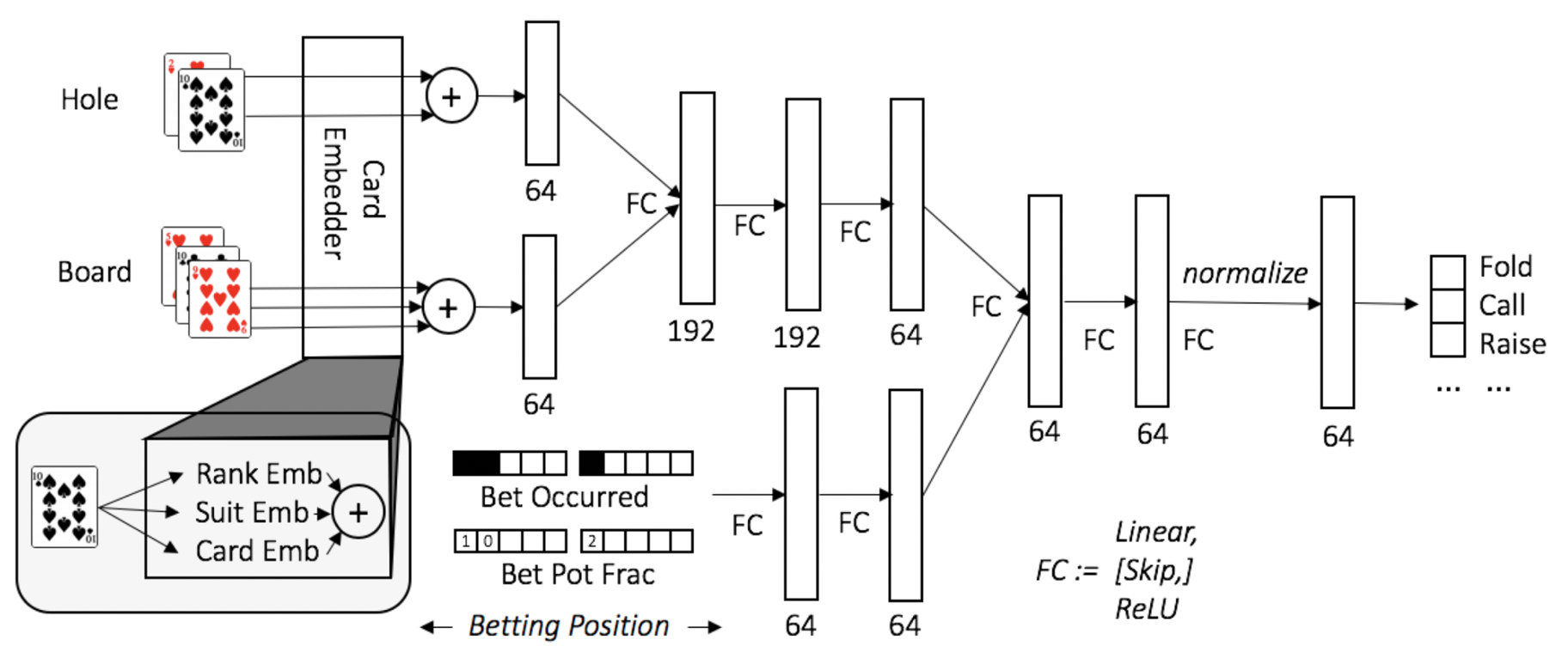
网络的输入为当前的信息集(当前的牌面以及历史动作),输出为每个动作的概率。
在价值网络中,输出向量表示输入信息集上每个动作的预测优势。在平均策略网络中,输出被视为行动的概率分布的对数。
训练过程

使用从CFR算法采样获得的遗憾值以及平均策略训练网络。

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









