







0在线课程
1. 综述
2. 非完全信息
参考文献
在围棋这种完全信息的零和博弈中,作为算法需要解决的仅仅只是如何搜索大规模博弈树的问题,但是在德州扑克这种非完全信息博弈的问题中往往还藏有欺骗诈唬等等手段。

Code Explanation
下图中的, 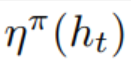
或者, z ==terminal history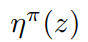

一个 s 对应一个 a, 也有 p(a | s), 所有的p 累乘就完事了(一个z 有 好多个 s),
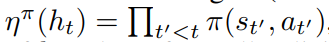
pass_bet = {'p': 0, 'b': 1}
if len(h) % 2 == 0:
tmp_h = str(self.p1.hand) + h # 手牌hand + 每个玩家的动作 e.g. pp
else:
tmp_h = str(self.p2.hand) + h
states = {'1': [0.5, 0.5], '1b': [0.5, 0.5], '1p': [0.5, 0.5], '1pb': [0.5, 0.5], '2': [0.5, 0.5], '2b': [0.5, 0.5],
'2p': [0.5, 0.5], '2pb': [0.5, 0.5], '3': [0.5, 0.5], '3b': [0.5, 0.5], '3p': [0.5, 0.5], '3pb': [0.5, 0.5]}
# 通过递归实现 累乘
def CFR_algorithm(self, h, pai1, pai2):
tmp_va = self.CFR_algorithm(
h + a, pai1 * states[tmp_h][pass_bet[a]], pai2)
# [tmp_h][0] 表示玩家1的后悔值,
CFR_r[tmp_h][0] = CFR_r[tmp_h][0] + oppo_pai * (va[0] - ave_va)
求和

states[tmp_h] = [p / (p + b), b / (p + b)]
# 完整代码
def change_states(self, h, p):
if p == 1:
tmp_h = str(self.p1.hand) + h
else:
tmp_h = str(self.p2.hand) + h
p = max([CFR_r[tmp_h][0], 0])
b = max([CFR_r[tmp_h][1], 0])
if p == 0 and b == 0:
states[tmp_h] = [0.5, 0.5]
else:
states[tmp_h] = [p / (p + b), b / (p + b)]
3. CFR+“直觉”(DeepStack)
参考文献
而在deepstack中采用的方案是CFR+“直觉”。也就是类似于Alphago的估值函数,并不搜索到最终局,在树发展到一定深度就进行截断评估。















 7514
7514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









