







技术:Java、JSP等
摘要:
因特网目前是一个巨大、分布广泛、全球性的信息服务中心,它涉及新闻、广告、消费信息、金融管理、教育、政府、电子商务和许多其它信息服务。但Internet所固有的开放性、动态性与异构性,使得准确快捷地获取网络信息存在一定难度。
本文的目的就是对网站内容进行分析,解析其中的超链接以及对应的正文信息,然后再通过URL与正文反馈网站内容,设计出抓取网页链接这个程序。
抓取网页中的所有链接是一种搜集互联网信息的程序。通过抓取网页中的链接能够为搜索引擎采集网络信息,这种方法有生成页面简单、快速的优点,提高了网页的可读性、安全性,生成的页面也更利于设计者使用。
关键词: 网页解析;JAVA;链接;信息抽取
目录:
摘 要 I
ABSTRACT II
1 绪论 1
1.1 课题背景 1
1.2 网页信息抓取的历史和应用 1
1.3 抓取链接技术的现状 2
1.3.1 网页信息抓取的应用 3
1.3.2 网页信息提取定义 4
2 系统开发技术和工具 7
2.1 项目开发的工具 7
2.1.1 Tomcat简介 7
2.1.2 MyEclipse简介 7
2.2 项目开发技术 8
2.2.1 JSP简介 8
2.2.2 Servlet简介 10
2.3 创建线程 11
2.3.1 创建线程方式 11
2.3.2 JAVA中的线程的生命周期 12
2.3.3 JAVA线程的结束方式 12
2.3.4 多线程同步 12
3 系统需求分析 14
3.1 需求分析 14
3.2 可行性分析 14
3.2.1 操作可行性 14
3.2.2 技术可行性 14
3.2.3 经济可行性 15
3.2.4 法律可行性 15
3.3 业务分析 15
3.4 功能需求 17
4 概要设计 18
4.1 运行工具 18
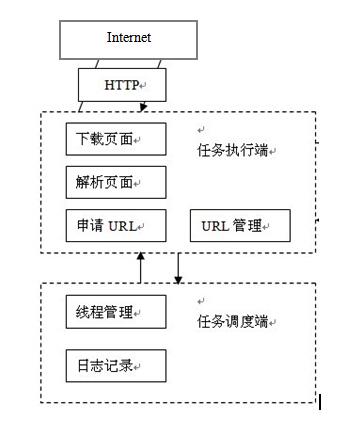
4.2 抓取网页中所有链接的体系结构 18
4.3 抓取网页中链接工作过程 19
4.4 页面的设计 21
4.4.1 页面的配置 21
4.4.2 系统主页面 21
5 系统详细设计与实现 24
5.1 抓取链接工作 24
5.2 URL解析 25
5.3 抓取原理 26
5.3.1 初始化URL 26
5.3.2 读取页面 27
5.3.3 解析网页 27
5.4 URL读取、解析 29
5.4.1 URL读取 29
5.4.2 URL解析 30
6 系统测试 33
6.1 软件测试简介 33
6.2 软件测试方法 33
6.3 测试结果 34
结论 38
参考文献 39
致谢 40
外文原文 41
外文译文 46
包含资料:
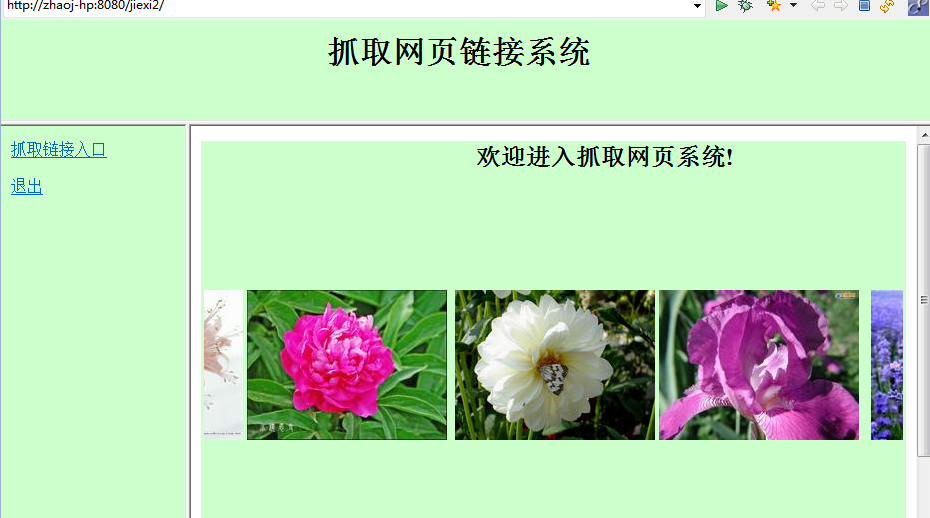
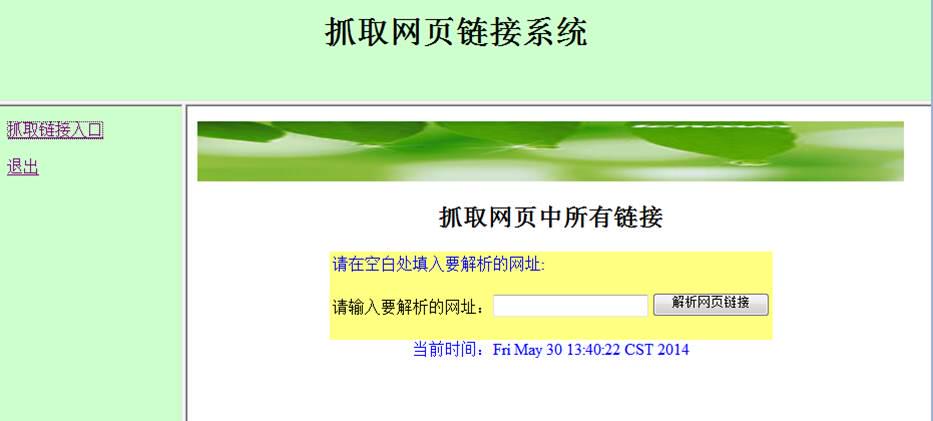
截图:
















 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









