







粗略体验了一天时间,做下小结:
结论:
总结:4分(满分5分),暂不能完美替代浏览器,其余均可圈可点,未来可期,推荐尝试使用。
体验版本:1.37.6
缺点:
⭐⭐浏览器功能:同基于chromium内核,但与主流浏览器(Chrome、Edge)在体验上差距较为明显,主要体现在
- 流畅度较差:遇到两三次明显卡顿现象。
- 内存占用高。
- 浏览器功能完善度低:当前版本具备基本浏览器功能,常用的标签页组等不具备。
- 插件体验问题(可能存在):当前安装的油猴、DarkReader等插件,体验上均不如Edge浏览器。
优点:
- ⭐⭐⭐与浏览器结合的内容:
- ai搜索
- 网页文本总结、脑图总结等
- 视频总结
- ⭐⭐⭐与系统结合的内容
- 截图ai处理(文字识别,分析总结等)
- 全局唤起
- 文档解读
- ai阅读
- ai生图
- ai写作
- ⭐⭐⭐⭐与编码结合的内容
- MarsCode AI
- 生成Doc
- 代码解读
- 单元测试
- 代码补全
- MarsCode AI
信息补充说明:
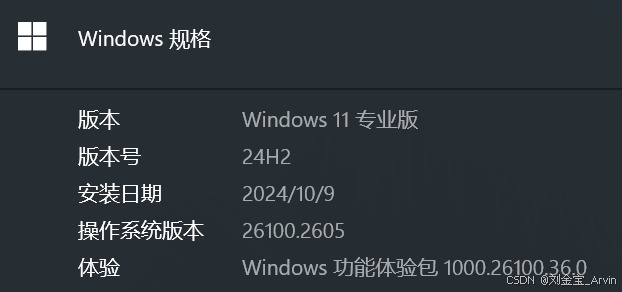
- 体验主机配置信息:


















 4904
4904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









