







Hive分区partition详解
Hive分区更方便于数据管理,常见的有时间分区和业务分区。
下面我们来通过实例来理解Hive分区的原理;
一、单分区操作
1.创建分区表
create table t1(
id int
,name string
,hobby array<string>
,add map<String,string>
)
partitioned by (pt_d string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
;注:这里分区字段不能和表中的字段重复。
如果分区字段和表中字段相同的话,会报错,如下:
create table t1(
id int
,name string
,hobby array<string>
,add map<String,string>
)
partitioned by (id int)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
;
报错信息:FAILED: SemanticException [Error 10035]: Column repeated in partitioning columns

2.装载数据
需要装载的文件内容如下:
1,xiaoming,book-TV-code,beijing:chaoyang-shagnhai:pudong
2,lilei,book-code,nanjing:jiangning-taiwan:taibei
3,lihua,music-book,heilongjiang:haerbin执行load data
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t1 partition ( pt_d = '201701');
3.查看数据及分区
查看数据
select * from t1;结果
1 xiaoming ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 201701
2 lilei ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 201701
3 lihua ["music","book"] {"heilongjiang":"haerbin"} 201701查看分区
show partitions t1;插入另一个分区
在创建一份数据并装载,分区=‘000000’
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t1 partition ( pt_d = '000000');查看数据:select * from t1;
1 xiaoming ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 000000
2 lilei ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 000000
3 lihua ["music","book"] {"heilongjiang":"haerbin"} 000000
1 xiaoming ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 201701
2 lilei ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 201701
3 lihua ["music","book"] {"heilongjiang":"haerbin"} 201701
观察HDFS上的文件
去hdfs上看文件
http://namenode:50070/explorer.html#/user/hive/warehouse/test.db/t1
可以看到,文件是根据分区分别存储

查询相应分区的数据
select * from t1 where pt_d = ‘000000’
添加分区,增加一个分区文件
alter table t1 add partition (pt_d = ‘333333’);

删除分区(删除相应分区文件)
注意,对于外表进行drop partition并不会删除hdfs上的文件,并且通过msck repair table table_name同步回hdfs上的分区。
alter table test1 drop partition (pt_d = ‘20170101’);
二、多个分区操作
创建分区表
create table t10(
id int
,name string
,hobby array<string>
,add map<String,string>
)
partitioned by (pt_d string,sex string)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':'
;装载数据(分区字段必须都要加)
load data local inpath ‘/home/hadoop/Desktop/data’ overwrite into table t10 partition ( pt_d = ‘0’);
如果只是添加一个,会报错:FAILED: SemanticException [Error 10006]: Line 1:88 Partition not found ”0”
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t10 partition ( pt_d = '0',sex='male');
load data local inpath '/home/hadoop/Desktop/data' overwrite into table t10 partition ( pt_d = '0',sex='female');,观察HDFS上的文件,可发现多个分区具有顺序性,可以理解为windows的树状文件夹结构。


表分区的增删修查
增加分区
这里我们创建一个分区外部表
create external table testljb(id int) partitioned by (age int);
添加分区
官网说明:
ALTER TABLE table_name ADD [IF NOT EXISTS] PARTITION partition_spec [LOCATION 'location'][, PARTITION partition_spec [LOCATION 'location'], ...];
partition_spec:
: (partition_column = partition_col_value, partition_column = partition_col_value, ...)实例说明
- 一次增加一个分区
alter table testljb add partition (age=2);- 一次增加多个分区
alter table testljb add partition(age=3) partition(age=4);- 注意:一定不能写成如下方式:
alter table testljb add partition(age=5,age=6);如果我们show partitions table_name 会发现仅仅添加了age=6的分区。
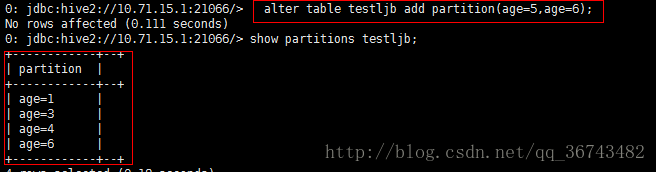
这里猜测原因:因为这种写法实际上:具有多个分区字段表的分区添加,而我们写两次同一个字段,而系统中并没有两个age分区字段,那么就会随机添加其中一个分区。
举个例子,有个表具有两个分区字段:age分区和sex分区。那么我们添加一个age分区为1,sex分区为male的数据,可以这样添加:
alter table testljb add partition(age=1,sex='male');删除分区
删除分区age=1
alter table testljb drop partition(age=1);注:加入表testljb有两个分区字段(上文已经提到多个分区先后顺序类似于windows的文件夹的树状结构),partitioned by(age int ,sex string),那么我们删除age分区(第一个分区)时,会把该分区及其下面包含的所有sex分区一起删掉。
修复分区
修复分区就是重新同步hdfs上的分区信息。
msck repair table table_name;查询分区
这个很简单
show partitions table_name;
















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









