







本人小白一个,不能保证博客中内容都准确,如果博客中有错误的地方,望各位多多指教,请指正。
上面的内容仅仅能解决本人遇到的错误,不一定适用于所有人,如有不适用,请多多包涵。
问题1:
运行elasticsearch之后,立马报错 java.lang.RuntimeException: can not run elasticsearch as root

原因:elasticsearch 不支持root用户启动
解决:切换用户运行
问题2:
运行elasticsearch之后,立马报错 future versions of Elasticsearch will require Java 11; your Java version from [/opt/jdk1.8/jre] does not meet this
原因:elasticsearch需要 jdk 11的支持,而我Linux上的jdk是8
解决:
第一种方法:修改 Linux 的JAVA_HAME 和 CLASSPATH ,改成JDK11的
第二种方法:elasticsearch 有自带的jdk ,而我又不想修改 Linux 的JAVA_HAME 和 CLASSPATH ,所以修改 elasticsearch 安装目录下bin下面的elasticsearch中的配置。
输入命令 : vim /opt/elasticsearch-7.4.0/elasticsearch-7.4.0/bin/elasticsearch
在最上面添加下面一段 : 下面一段话的意思相当于定义了一个局部变量JAVA_HOME和PATH,并重新赋值,然后让elasticsearch中的JAVA_HOME和PATH使用局部变量,此时就相当于局部变量把全局变量覆盖了 ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓ ↓
#配置自己的jdk11
export JAVA_HOME=/opt/elasticsearch-7.4.0/elasticsearch-7.4.0/jdk
export PATH=$JAVA_HOME/bin:$PATH
#添加jdk判断
if [ -x "$JAVA_HOME/bin/java" ]; then
JAVA="/opt/elasticsearch-7.4.0/elasticsearch-7.4.0/jdK/bin/java"
else
JAVA=`which java`
fi
问题3:
运行elasticsearch之后,立马报错 java.nio.file.AccessDeniedException

原因:该用户没有权限执行这个文件
解决:给该用户授权 chown -R 用户名:用户名 /opt/elasticsearch-7.4.0
问题4:
运行 kibana 之后,立马报错 Kibana should not be run as root. Use --allow-root to continue.
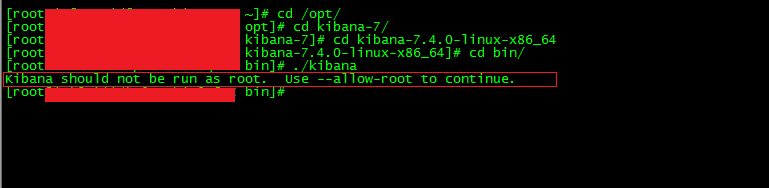
原因:kibana 不支持root用户启动
解决:如果硬是要用root用户启动 就在后面加 --allow-root ,要么就切换用户执行(记得授权)

问题5:
运行 kibana 之后,elasticsearch 立马就蹦了,直接 killed 自杀了 ,心态炸了


原因:具体我也不知道,改了jvm的 内存参数就可以了 ,默认1g不行,改成512m就可以,这SB玩意,是为什么???有人知道求告诉
解决:
输入命令 : vim /opt/elasticsearch-7.4.0/elasticsearch-7.4.0/config/jvm.options

问题5:
java.net.SocketTimeoutException: 30,000 milliseconds timeout on connection http-outgoing-0 [ACTIVE]

原因:
ElasticSearch 与客户端的默认 socket 超时时间只有 30,000 milliseconds ,操作的时间过长(查询的数据过大时),所需要的时间超过了 30,000 milliseconds 就会报错
解决:
RestHighLevelClient中有个 setRequestConfigCallback 方法 提供了设置 socket 的 超时时间,代码如下:
RestClient.builder(
new HttpHost(
host,
port,
"http")
).setRequestConfigCallback( // 自定义超时时间
new RestClientBuilder.RequestConfigCallback() {
@Override
public RequestConfig.Builder customizeRequestConfig(RequestConfig.Builder requestConfigBuilder) {
return requestConfigBuilder.setConnectTimeout(5000 * 1000) // 自定义连接超时时间
.setSocketTimeout(6000 * 1000);// 自定义Socket超时时间(默认 30,000 milliseconds )
}
}
)
问题6:
query_string:识别query中的连接符(or 、and)
queryString多条件查询时 ,query_string 中 query的值为 "华为 AND 手机 " 去查询,与 query的值为 "华为手机 " 设置 "default_operator": "AND" 去查询 ,查询到的结果不一样????为什么 ??? 两者的区别在哪里???

原因:以下原因仅仅我个人理解,如有误解,敬请指正。
分析问题图中第一个查询: "query": "华为手机"
我们在使用query_string ,多条件查询时,会识别query中的连接符(or 、and),会自动将query中的条件进行分词 。
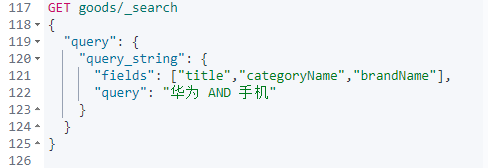
此时的query查询条件就变成了 "title","categoryName","brandName" 三个field 与 "华为","手机" 做全排列,然后两两结合成条件 取 AND ,两两结果取OR 。
具体请看下图:

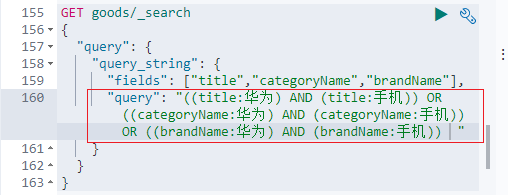
分析问题图中第二个查询: "query": "华为手机 " , "default_operator": "AND"
关于 "default_operator" 前置知识:
"default_operator" : 默认运算法,有 AND 、OR 、NOT 三个取值 ,默认为OR
当 "default_operator" 的 值 为 AND 时,会将先 "华为手机" 分词,分为 "华为" 、"手机" 、"华" 、"为手"、 "为" 、 "手" 、"机" ,字段内必须同时包含这些词才可以匹配。
当 "default_operator" 的 值 为 OR时,会将先 "华为手机" 分词,分为 "华为" 、"手机" 、"华" 、"为手"、 "为" 、 "手" 、"机" ,字段中只要包含其中一个就可以匹配。
分析:
我们在使用query_string ,多条件查询时,会识别query中的连接符(or 、and),会自动将query中的条件进行分词 。

此时的query查询条件就变成了 , "title","categoryName","brandName" 三个field 各自与 "华为","手机" 做同时匹配,然后结合成条件 取 AND ,两两结果取OR 。
具体请看下图:














 1241
1241











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









