







在本章中,我们对GAN的核心概念加以扩展,并应用卷积神经网络。我们也将创建一个条件式GAN,用于生成指定类型的数据。
3.1 卷积GAN
在本节中,我们将从以下两个角度出发,改良之前创建的CelebA GAN。
- 生成的图像看起来仍然比较模糊。有些我们希望色彩相当平滑的区域被高对比度的像素图案覆盖。
- 全连接的神经网络消耗大量内存。即便是中等大小的图像或网络,也会很快使GPU达到极限,以至于训练无法继续。大多数消费级GPU的内存要比谷歌Colab提供的Tesla T4或P100小得多。
3.1.1 内存消耗
在探索新的GAN技术之前,我们先来看看之前创建的GAN消耗了多少内存。如果我们再次运行整个笔记本,鉴别器网络和生成器网络都会消耗内存。更准确地说,输入数据、网络中间层的结果、输出数据以及可学习参数,都是会占用GPU内存的张量。
我们可以通过以下代码查看当前所分配的内存大小。
结果除以1 0241 0241 024,目的是将字节(byte)单位转换为吉字节(gigabyte,GB)。
可以看到,运行笔记本中所有代码后,GPU分配了大约0.70 GB的内存给张量。这主要是因为鉴别器对象和生成器对象仍然存在,随时可以再次调用。
不过,这个数字并不能说明全部情况。在运行GAN代码后,有些内存会被释放出来。通过以下代码,我们可以知道运行过程中张量消耗的内存峰值是多少。
该峰值应该比之前的结果大。
我们看到,在代码运行过程中,张量消耗的内存峰值约为1.09GB。
通过以下代码,我们可以了解更多关于内存消耗的统计数字。
在汇总的信息中,有我们刚刚看到的当前和峰值内存消耗。
在上表中的已分配内存(Allocated memory)行,当前消耗(Cur Usage)为733 992 KB,与我们之前计算的0.70GB一致;峰值消耗(Peak Usage)为1 119 MB,与1.09 GB一致。这些数字是很好的基准,能够帮助我们评估某种改良方法是否可以有效减少内存消耗。
3.1.2 局部化的图像特征
机器学习的黄金法则之一是,最大限度地利用任何与当前问题相关的知识。这些领域知识(domain knowledge)可以帮助我们排除不成立的选项,从而简化问题空间。这样一来,可学习参数的组合变少了,机器学习相对更容易了。
如果对图像进行进一步的思考,我们会发现,大多数有意义的特征(feature)是局部化(localised)的。例如,表示眼睛或鼻子的像素靠得很近。利用这些信息,我们可以将图像分类为人脸。我们应该设计一个神经网络,利用相邻像素群的局部特征进行分类。
在之前的MNIST分类器和CelebA分类器中,我们没有这样做,而是把图像的所有像素一起考虑。这么做也没有错。这些网络可以学习正确的链接权重,并挑选正确的特征来帮助图像分类。唯一的区别在于,利用所有像素学习的难度更大些。
3.1.3 卷积过滤器
让我们以一个6像素× 6像素的简单笑脸图像为例。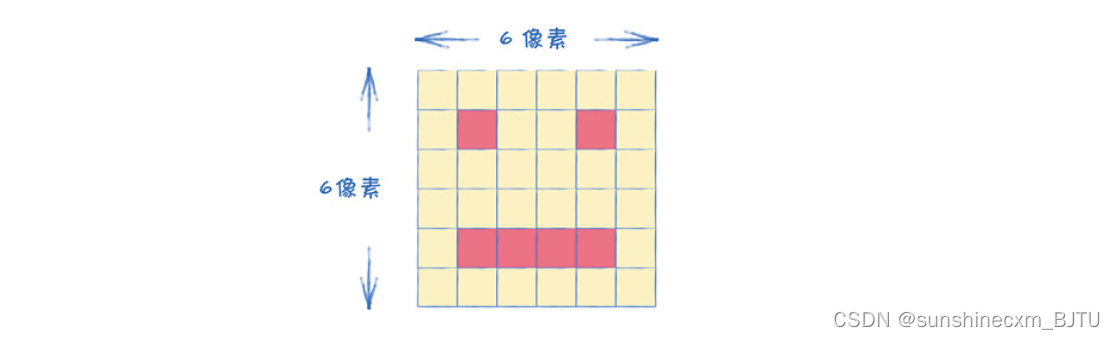
假设有一个放大镜,如果我们用它对准任何图像,它只能看到图像中一个4像素× 4像素的区域。如果用这个放大镜在上图中移动,它只能看到一只眼睛,或者看到嘴巴的一部分。这个放大镜就体现了我们所说的局部性(locality)。
假设我们在图像上移动放大镜,并计算在4像素× 4像素的区域内有多少个深色像素,我们就可以创建一个新的、汇总局部信息的网格。下图直观地解释了这个过程。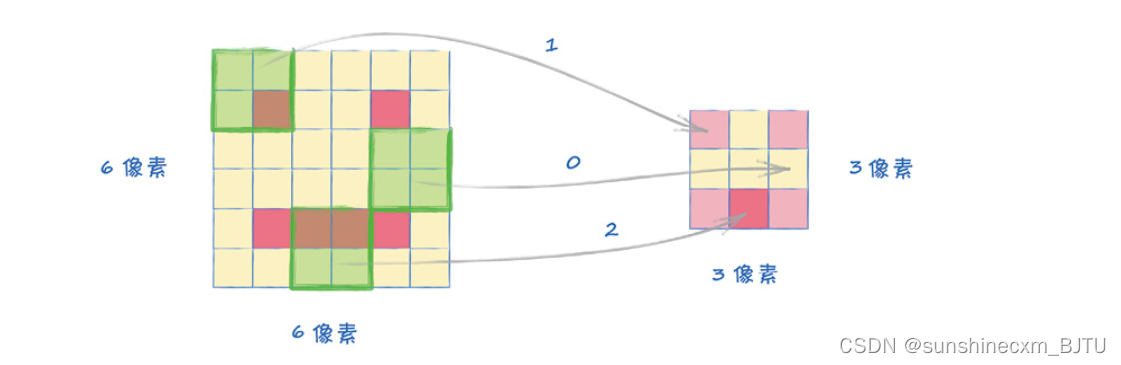
上图中右边较小的网格大小是3像素× 3像素,汇总了放大镜在图像的每个区域的发现。我们可以看到,它在图像的左上方和右上方各发现了一只眼睛。同时,它也发现了底部的暗像素区域,底部中间格像素最暗。此外,中间行的左、中、右都没有暗像素。
我们可以看出,这个汇总网格对于脸部图像的分类是有帮助的。下图显示了使用这种方法对一张稍有不同的哭脸图像进行分类的过程。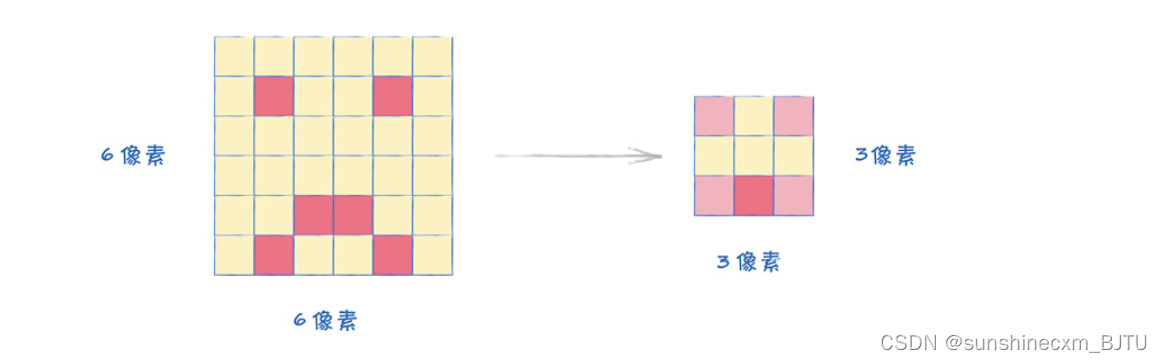
我们发现,对于上面两幅不同的脸部图像,汇总后的网络是一样的。这个过程看起来相当实用,因为它可以识别局部特征,而不受图像之间微小区别的影响。
我们将这种在图像上移动并汇总新的网格的过程称为卷积(convolution)。该词汇来自一个数学过程,用于计算两个函数或信号形状的相似度。这里我们要计算的是放大镜的图案与它所覆盖区域的相似度。
这个过程可以更加复杂。比如,如果放大镜有偏差,对一些像素的赋值较高,对另一些像素的赋值较低,就可以用来识别特定的图案。
例如,下图中的放大镜的作用是只考虑图像中上面的两个像素,同时忽略下面的两个像素。它通过将顶部像素值乘以1、底部像素值乘以0来实现这个效果。这样一来,它就能在图像中识别出水平线了。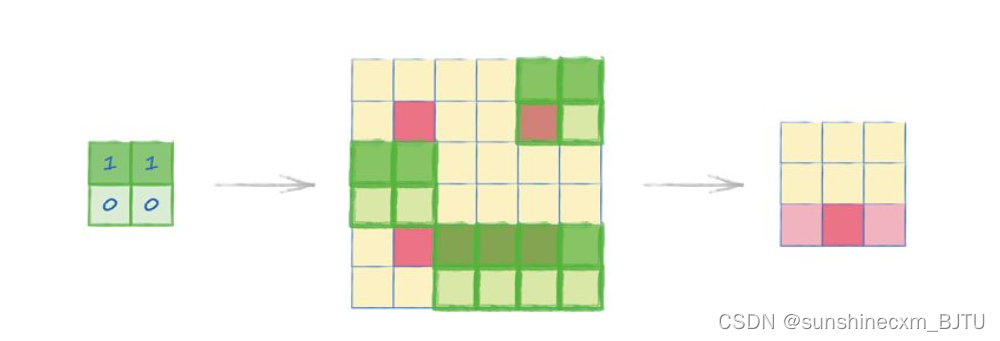
在所得到的汇总网格中,只有底部中间的像素值较高。这对应了图像中确实存在的一条深色水平线。
该放大镜的标准名称是卷积核(convolution kernel)。下图显示将两个稍有不同的卷积核应用在同一幅图像上。这两个卷积核的偏差在不同的对角线方向。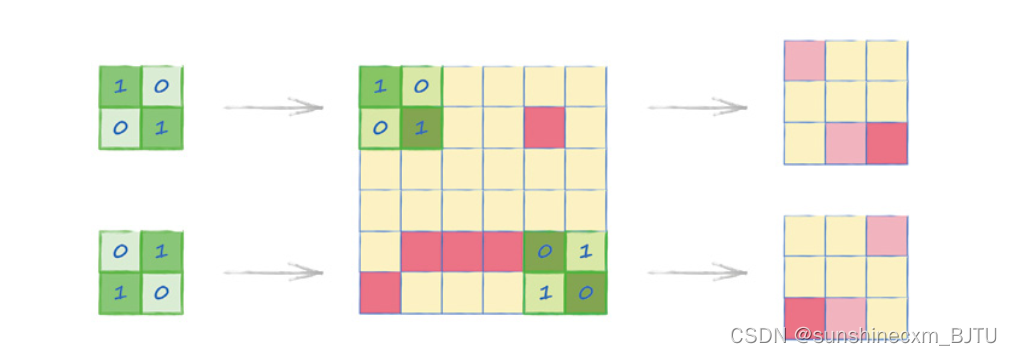
我们看到,卷积核可以识别出图像中具有相应对角线特征的区域。
更多关于卷积的例子,可以在附录C中找到。
3.1.4 学习卷积核权重
一个值得思考的问题是,当我们试图训练一个分类器时,这些卷积核有什么作用?我们已经看到,不同的卷积核可以从同一幅图像中识别出不同的图案,这些信息对图像分类很有帮助。例如,底部中间的水平深色特征,加上左上角和右上角附近的深色特征,就表明这是一张人脸图像。
我们可以选择不同的卷积核,然后学习每个卷积核的重要性,有点像从图像到卷积核的链接权重。
一种更好的方案是,不用提前设计卷积核,而是通过学习获得卷积核中的最佳赋值或权重。这正是包括PyTorch在内的许多机器学习框架所采取的方法。
基本上,我们只需要决定使用几个卷积核,比如20个。 在训练过程中,我们会对每个卷积核内部的权重进行调整。如果训练成功,最终得到的卷积核会从图像中挑出最有代表性的细节。神经网络的其余部分将结合这些信息对图像进行分类。不是所有的卷积核都会有用,较低的链接权重会降低这些卷积核的影响。
3.1.5 特征的层次结构
我们刚才讲了一层卷积核如何识别出低层次特征(如边缘或斑点),并将这些信息汇总在网格中。这些网格的正式名称是特征图(feature map)。
如果将另一层卷积核应用到这些特征图上,我们可以得到中层次的特征。这些特征是低层次特征的组合。比如说,斑点和边缘的正确组合可能是一只眼睛或一个鼻子。
我们可以再应用一层卷积核,得到更高层次的特征。这些特征是中层次特征的组合。眼睛和鼻子特征的正确组合,加上方向,很可能代表一张人脸。
下图中,具有层次结构的卷积层可以发现低层次、中层次和高层次特征。其中,卷积核和特征图的内容只用于说明。
关于大脑如何理解眼睛所看到的东西,在科学界仍有很大争议。不过,很多人认为它的原理与这种层次分析类似。
无论如何,这种从相邻像素图案构建中层次特征,再从中构建高层次内容的方法,可以提高图像分类的效率。事实上,卷积神经网络,即CNN,长期以来一直是图像分类领域的前沿技术。
CNN的关键在于,网络可以自己学习卷积核的具体值。换句话说,我们让网络自己找到最有用的低层次、中层次和高层次图像特征。
3.1.6 MNIST CNN
为了加深理解,我们先构建一个使用卷积神经网络的MNIST分类器。
我们可以从以下链接复制在第1章使用的MNIST分类器代码。
我们只需要修改分类器神经网络的定义。其余的代码,如加载数据、查看图像、训练网络和检查分类性能等部分,不需要太多改变。
上面这个全连接神经网络的输入层有784个节点,与中间层的200个节点完全连接。中间层再与输出层的10个节点完全连接。中间层使用LeakyReLU激活函数,再应用标准化。在输出层,我们只用一个S型激活函数。该网络在MNIST测试数据集可达到97%的准确率。
现在,我们需要思考如何用卷积过滤器来替代现有模型。要解决的第一个问题是,卷积过滤器需要在二维图像上工作,而现在输入网络的是一个简单的一维像素值列表。一个简单而快捷的解决方案是,将image_data_tensor变形为(28,28)。
实际上,我们要使用四维张量,因为PyTorch的卷积过滤器的输入张量有4个元素**(批处理大小、通道、高度、宽度)。我们使用的批处理大小为1,而MNIST图像是单色的,只有1个通道,所以我们的MNIST数据需要被塑造为(1,1,28,28)的形式。我们可以使用View()函数**很容易地实现这一步。

该神经网络的第1个元素是卷积层nn.Conv2d。其中,第1个参数是输入通道数,对于单色图像是1;第2个参数是输出通道的数量。在上面的代码中,我们创建了10个卷积核,从而生成10个特征图。
第3个参数kernel_size是卷积核的大小。在3.1.3节的讨论中,我们使用了一个2×2的正方形卷积核。在本节中,我们将卷积核设置为5×5的正方形。
最后一个参数stride设置了卷积核沿图像移动时的步长大小。在上面的讨论中,我们让2×2的卷积核以2像素的步长移动。这里我们同样将步长设置为2。
下图中,通过分别展示步长等于2和等于1的例子,解释步长的工作原理。注意,在步长为1的情况下,卷积核所覆盖的区域有重叠。这并没有问题。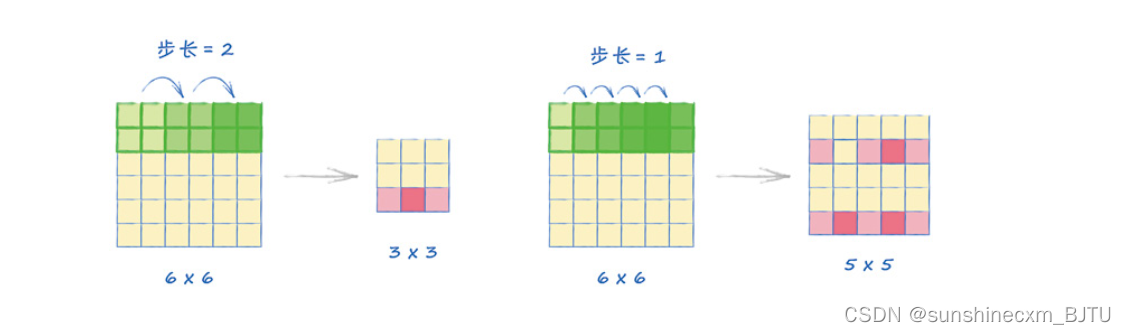
一个MNIST图像的大小为28像素× 28像素,一个卷积核的大小为5×5,步长为2,输出的特征图的大小为12像素× 12像素。
与之前一样,对于每一层的输出,我们仍需要一个非线性激活函数。我们可以继续使用LeakyReLU(0.02),之前使用它的效果很好。
接着,我们对这些特征图进行标准化处理。在这里,我们没有使用LayerNorm(),而是使用BatchNorm2d()对图层中的每个通道进行标准化。
接下来的代码也类似。另一个卷积层加上标准化和非线性激活函数。这次,我们对前一层输出的10个特征图分别应用一个卷积核,从而得到10个新的特征图。这里,卷积核比之前的小,长宽均为3个像素。同样在步长为2的情况下,我们得到的输出特征图大小为5×5。
网络的最后一个部分包括10个大小为5×5的特征图。我们将总共10×5×5=250个值转换成一个包含250个值的一维列表。这时,我们需要在Sequential列表中使用之前定义的View()类。最后,一个全连接层把这250个值映射到10个输出节点,每个节点都用一个S型激活函数。之所以需要10个输出节点,是因为我们需要将图像分类为10个数字中的一类。
下面是我们的架构图。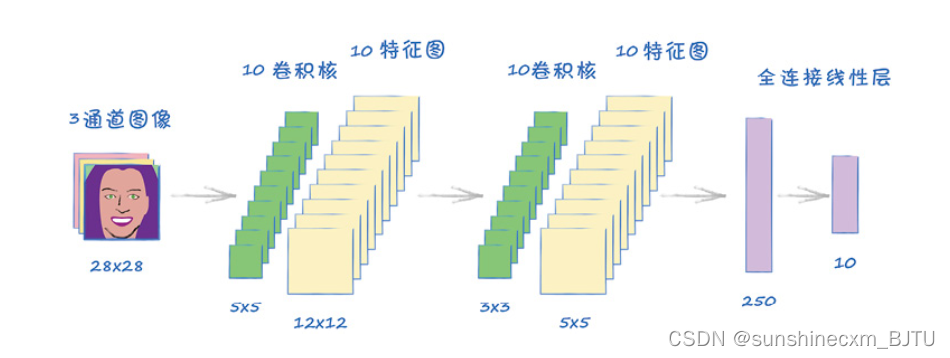
让我们训练这个CNN,并用之前测试全连接MNIST分类器的方法测试它的性能。
我们注意到的第一个区别是,训练这个CNN的速度比较快。之前的全连接网络需要13.5分钟,现在的CNN只需要约9.5分钟。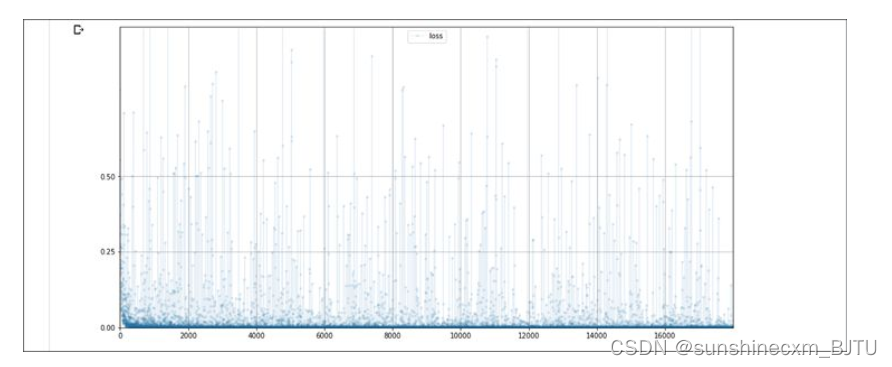
CNN的损失图与全连接网络损失图非常相似。损失值迅速下降并接近0,大部分损失值保持在0附近。

新模型的准确率为98%,高于之前全连接网络的97%。虽然看起来提升不是很大,但是对于任意MNIST分类器来说,达到高于98%的准确率都相当困难。该卷积分类器只用简单的设计和少量代码,便取得了98%的准确率!














 4853
4853











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









