







一、什么是 NLTK 包
NLTK 全称是 Natural Language Toolkit,自然语言处理工具包,是 NLP 领域中常用的 python 库
NLTK 的作用:
- 语料库
- 文本预处理:文本清洗、文本标准化
- 分词:将一段连续的文本划分为单独的词语或符号
- …
二、如何使用
NLTK 如何使用:
# pip install nltk
import nltk
nltk.download(xxx)
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
但一般下载不下来,会出现如下报错:
nltk.download('punkt')
[nltk_data] Error loading punkt: <urlopen error [Errno 101] Network is
[nltk_data] unreachable>
False
可以去官网下载,并注释掉代码中 nltk.download() 代码
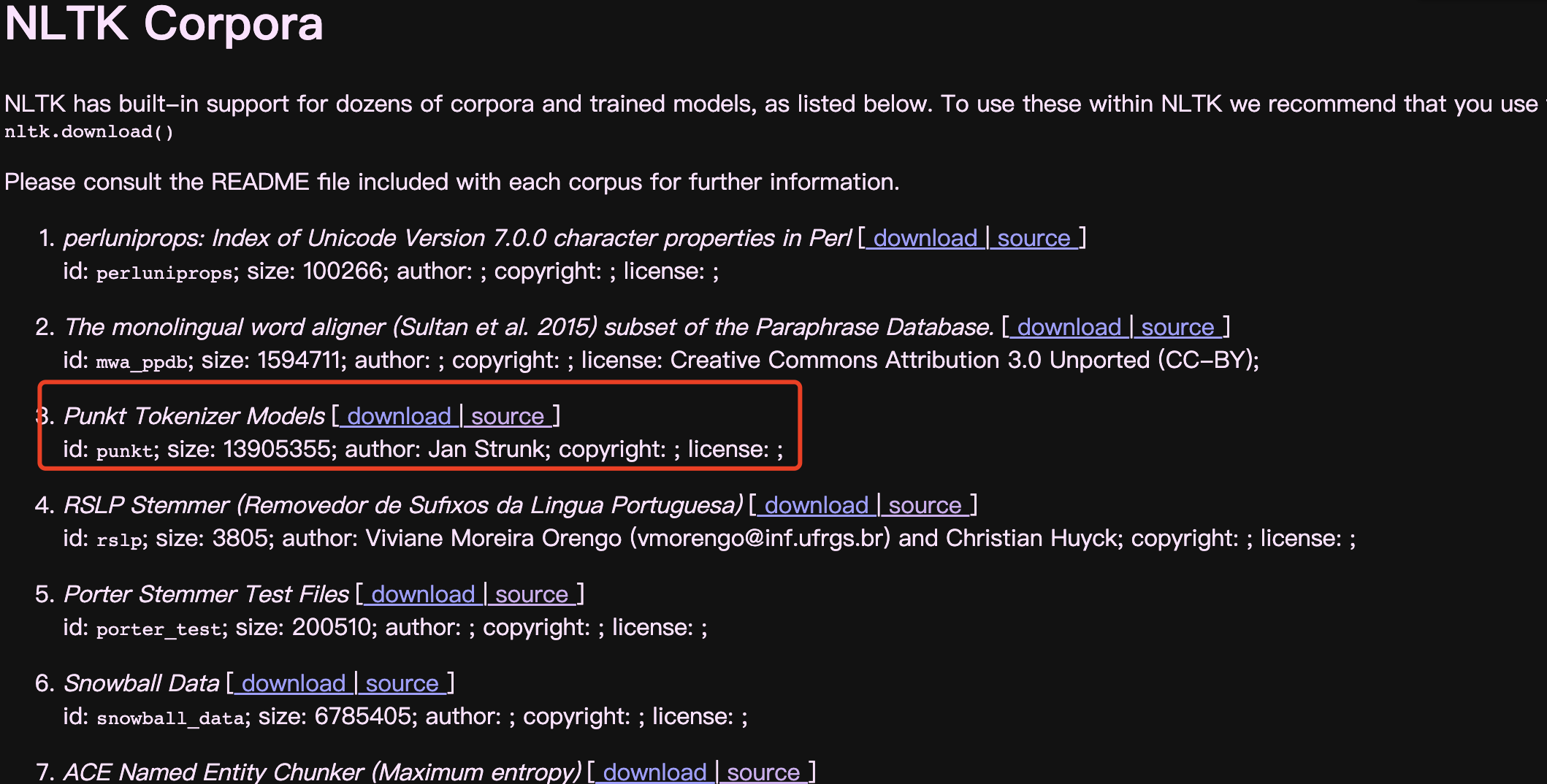
下下来了然后放到哪里呢?
方法一:可以使用如下命令将压缩包放入对应路径
import nltk
nltk.word_tokenize('dog')
然后会提示如下:
For more information see: https://www.nltk.org/data.html
Attempted to load tokenizers/punkt/PY3/english.pickle
Searched in:
- '/home/xxx/nltk_data'
- '/home/xxx/anaconda3/nltk_data'
- '/home/xxx/anaconda3/share/nltk_data'
- '/home/xxx/anaconda3/lib/nltk_data'
- '/usr/share/nltk_data'
- '/usr/local/share/nltk_data'
- '/usr/lib/nltk_data'
- '/usr/local/lib/nltk_data'
- ''
也就是说会在这些路径下去找,那我们在这些路径下找一个合适的路径放进去并解压,按这样的格式放即可:
- nltk_data
- tokenizers
- punkt
- punkt.pickle
- tagger
- averaged_perceptron_tagger
- averaged_perceptron_tagger.pickle
方法二:添加可以寻找的路径,并将压缩包放到对应路径下即可
import nltk
nltk.data.path.append('/xxx/xxx/glip/nltk_data/')
三、phrase grounding 使用 NLTK 示例
推理的时候会用到 nltk 库,可以从一个文本描述中抽取到有用的名词,作为需要检测的目标
# 示例:
caption = 'There is two cat and a remote in the picture'
find_noun_phrases(caption) # ['cat', 'a remote', 'the picture']



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











