









Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
1. Motivation
- 将Transformer应用到视觉领域有许多挑战,比如尺度问题——对于具有相同语义的物体有许多尺寸。
- 图像分辨率很大,将其像素拉成一个一维向量会大大增加计算复杂度(一般是输入特征图或者将图片分成几个patch)。
2. Contribution
基于移动窗口的分层Transformer
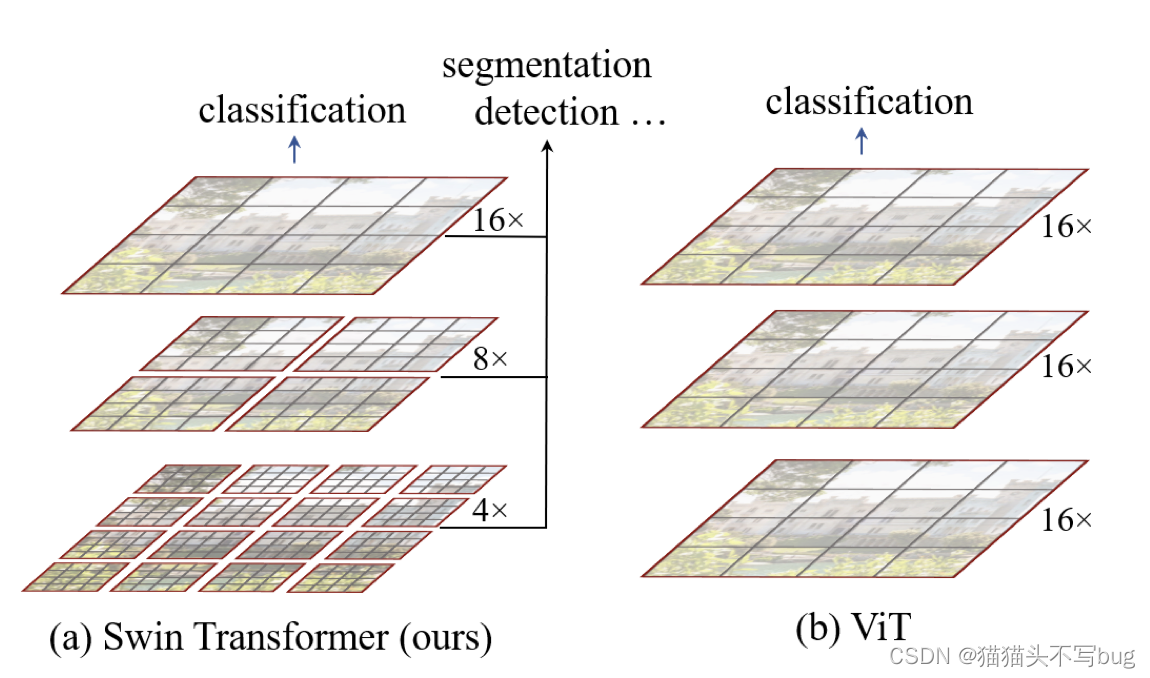
- 在小窗口内使用自注意力而不是像ViT一样在整张图片使用自注意力,这样自注意力的计算复杂度就是固定的——只和窗口大小有关。计算复杂度和图片尺寸成线性关系。
- 提出基于移动窗口的自注意力,提高模型全局建模的能力。
- 分层结构容易获得多尺度特征(patch merging)。
3. Method
3.1 Shifted Window
1、基本原理
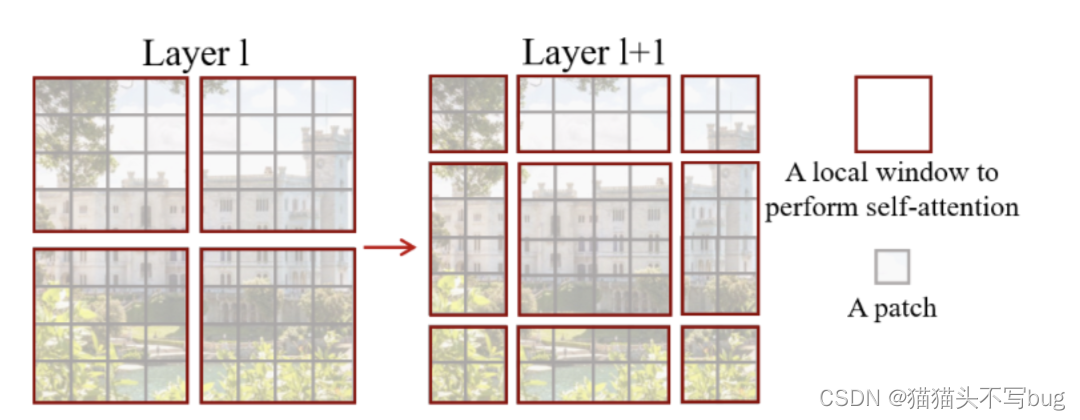
- 灰色是patch块,红色框为local window,在这个window里使用自注意力。
- 在Layer l中,采用规则窗口划分(一般每个窗口里面有7 * 7=49个patch)。在Layer l+1层里,窗口向下向右移动(一般是移动窗口大小的一半)。
- 新窗口中的自我注意计算跨越了Layer l中先前窗口的边界,提供了它们之间的联系。可以更好的全局建模。
- 假设一个patch在Layer l层只能和window内部其他patch做全局自注意力,经过shift后,可以和先前别的窗口内的patch做交互。
- 但是移动窗口的方式存在窗口内patch数量不一样且窗口数目增加(原来是4个移动后变成了9个)的问题。于是作者提出了一个掩码方。
2、Masked MSA:
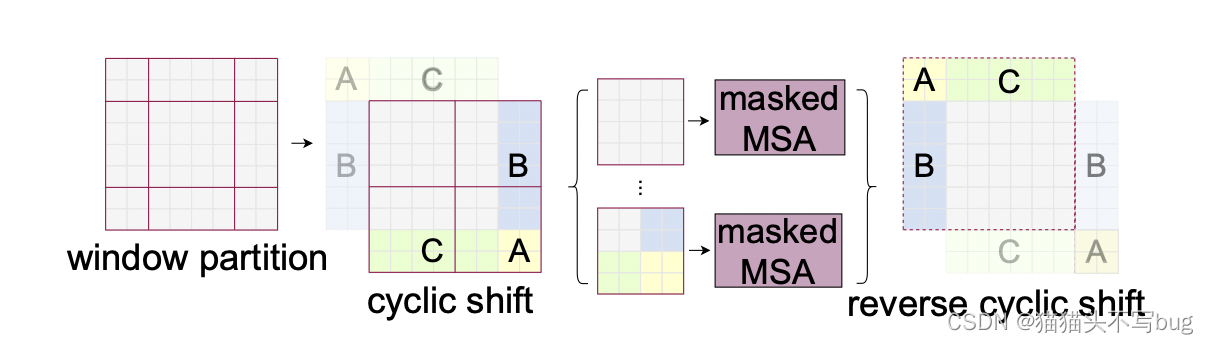
cycle shift通过拼贴的方式固定了窗口数目,计算复杂度也固定。但是原始部分和拼贴部分相互之间是不需要做交互的。这就提出了掩码操作。最后还原循环位移。
经过cycle shift后窗口如图所示:
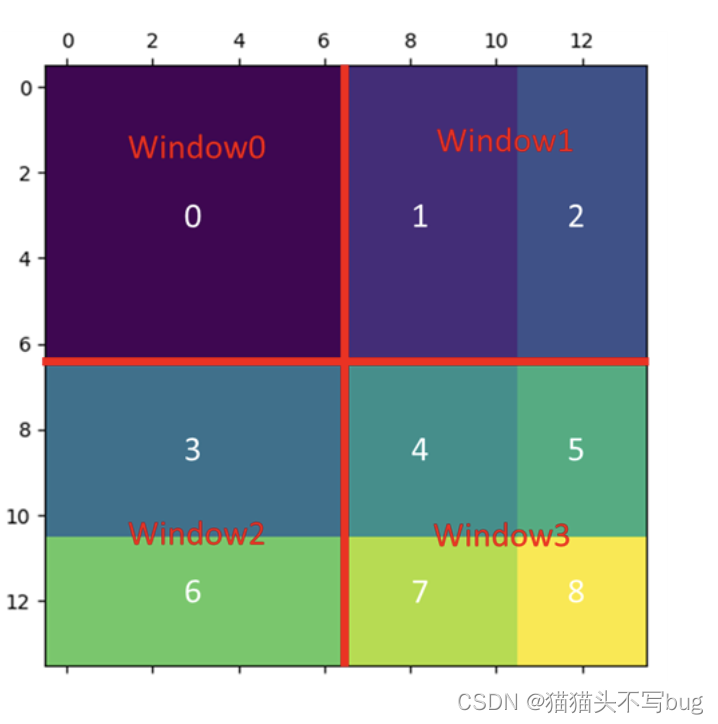
其中窗口内不同颜色表示来自原始区域不同区域的窗口,不同颜色之间是不需要做自注意力的。
以window2为例,将区域3和6的patch向量全部都展开,拼贴成向量,再转置相乘。最后得到的自注意力矩阵,右上和左下是不需要交互的。会使用一个 [ 0 − 100 − 100 0 ] \begin{bmatrix} 0 & -100\\-100 & 0\\ \end{bmatrix} [0−100−1000]的矩阵。和输出矩阵相乘。这样右上左下就会变成一个很小的负数经过softmax,权重就为0。
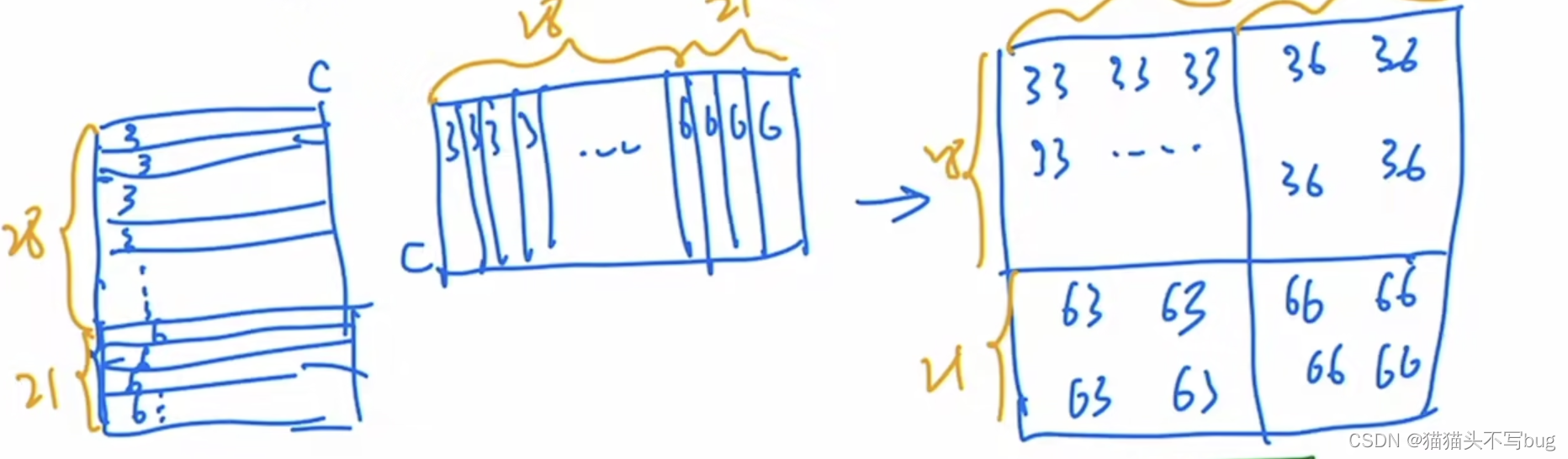
以window1为例,展平后向量是交替起来的。
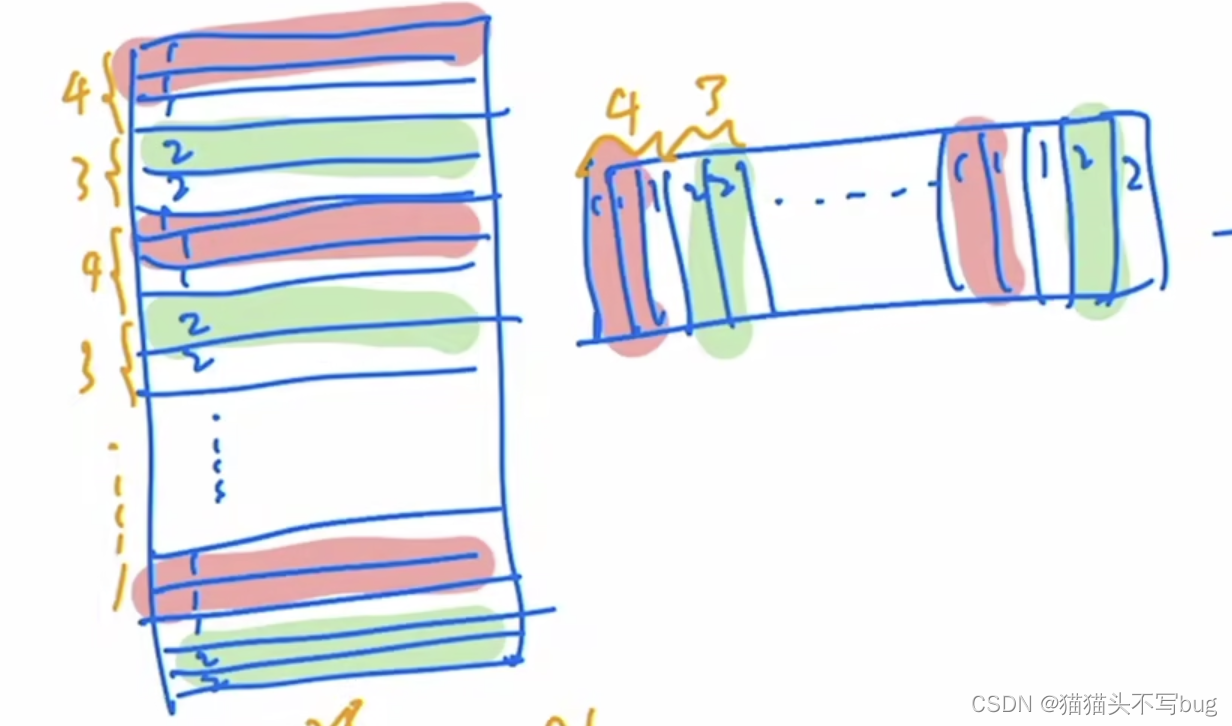
最终得到的输出是:

紫色为需要做自注意力的部分,黄色是需要mask的部分。
具体还是要看源码,这里作者有给一些解释:https://github.com/microsoft/Swin-Transformer/issues/52
3、关于滑动窗口的自注意力的计算复杂度
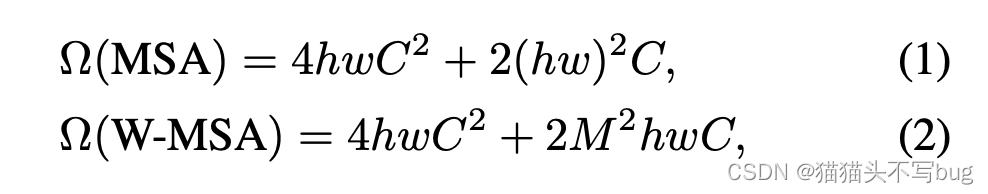
- (1)是普通的基于多头注意力的计算负责度;(2)是基于滑动窗口的。假设每个image有h * w个patch。
- M是一个窗口的某一条边上有多少patch。
- (1)的计算:
- 普通的多头注意力,一般是对于一个输入(hw * c)分别乘以一个系数矩阵(c * c),得到Q,K,V三个向量(维度是hw * c)。这里计算复杂度就是 3 h w c 2 3hwc^2 3hwc2
- 然后Q和K相乘得到自注意力矩阵A(hw * hw),然后A再和V做乘法,相对于一次加权。这里计算复杂度就是 2 ( h w ) 2 c 2(hw)^2c 2(hw)2c
- 最后经过project layer (c * c)得到特定维度的输出。这里计算复杂度就是 h w c 2 hwc^2 hwc2
- (2)的计算:
- 因为是在窗口内做自注意力,输入的序列长度变成M*M。带入公式(1)里面就是: 4 M 2 c 2 + 2 M 4 c 4M^2c^2+2M^4c 4M2c2+2M4c 。
- 一共有 h M × w M \frac{h}{M} \times \frac{w}{M} Mh×Mw个窗口。
3.2 Structure
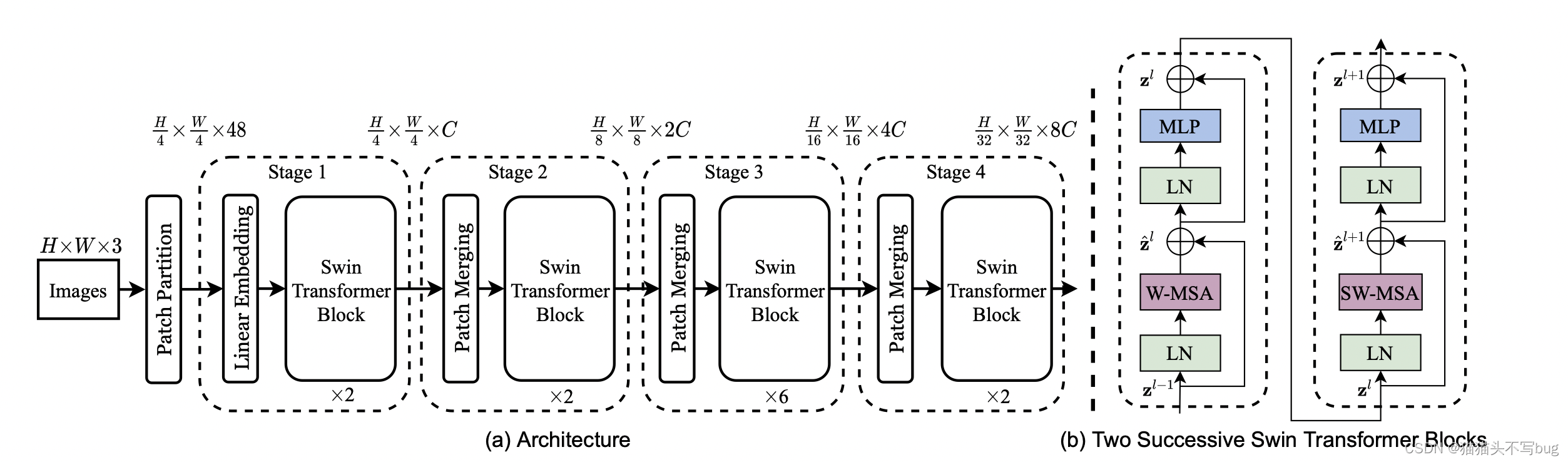
(a)architecture
- 先把图片打成patch(size=4*4),输入的维度变成 H 4 × W 4 × 48 \frac{H}{4}\times \frac{W}{4}\times48 4H×4W×48
- Linear Embedding,C是超参数。输入会变成: H 4 × W 4 × C \frac{H}{4}\times \frac{W}{4}\times C 4H×4W×C,然后被拉直变成: H W 16 × C \frac{H W}{16}\times C 16HW×C
- 引入基于移动窗口的Transformer block(只算窗口内部的自注意力),每个窗口内部只有49个patch,降低序列长度。Transformer不改变输入输出维度。
- Patch Merging,类似于pixel shuffle
- 对于一个H * W * C张量,每隔一个像素点采一次样,得到4个 H 2 × W 2 × C \frac{H}{2}\times \frac{W}{2}\times C 2H×2W×C的张量。
- 然后在C的维度上拼接起来得到: H 2 × W 2 × 4 C \frac{H}{2}\times \frac{W}{2}\times 4C 2H×2W×4C
- 然后在C这个维度上用1 * 1的卷积,将维度降到:
H
2
×
W
2
×
2
C
\frac{H}{2}\times \frac{W}{2}\times 2C
2H×2W×2C。空间大小减半,通道数*2。

- 经过patch merging,输出就变成: H 8 × W 8 × 2 C \frac{H}{8}\times \frac{W}{8}\times 2C 8H×8W×2C
- 和ViT不一样的是,没有使用cls token,而是像卷积神经网络一样在最后输出的特征图上面增加一个global average pooling。(如果是做分类任务的话)
(以上借鉴李沐老师团队的讲解)
(b) Swin Transformer block
- 对于输入,先做一次窗口的多头自注意力(W- MSA),然后再做一次基于移动窗口的多头自注意力(SW-MSA)。
- 所以一个block做了两次自注意力,两个Transformer block。
3.3 Swin Transformer变体
Swin-Tiny、Swin-Small、Swin-Base、Swin-Large。
Swin-T和Swin-S的复杂性分别与ResNet-50(Deit-S)和ResNet-101相似。
主要不同的是C和transformer block的数量。

4. Experiment
4.1 Image Classification on ImageNet-1K
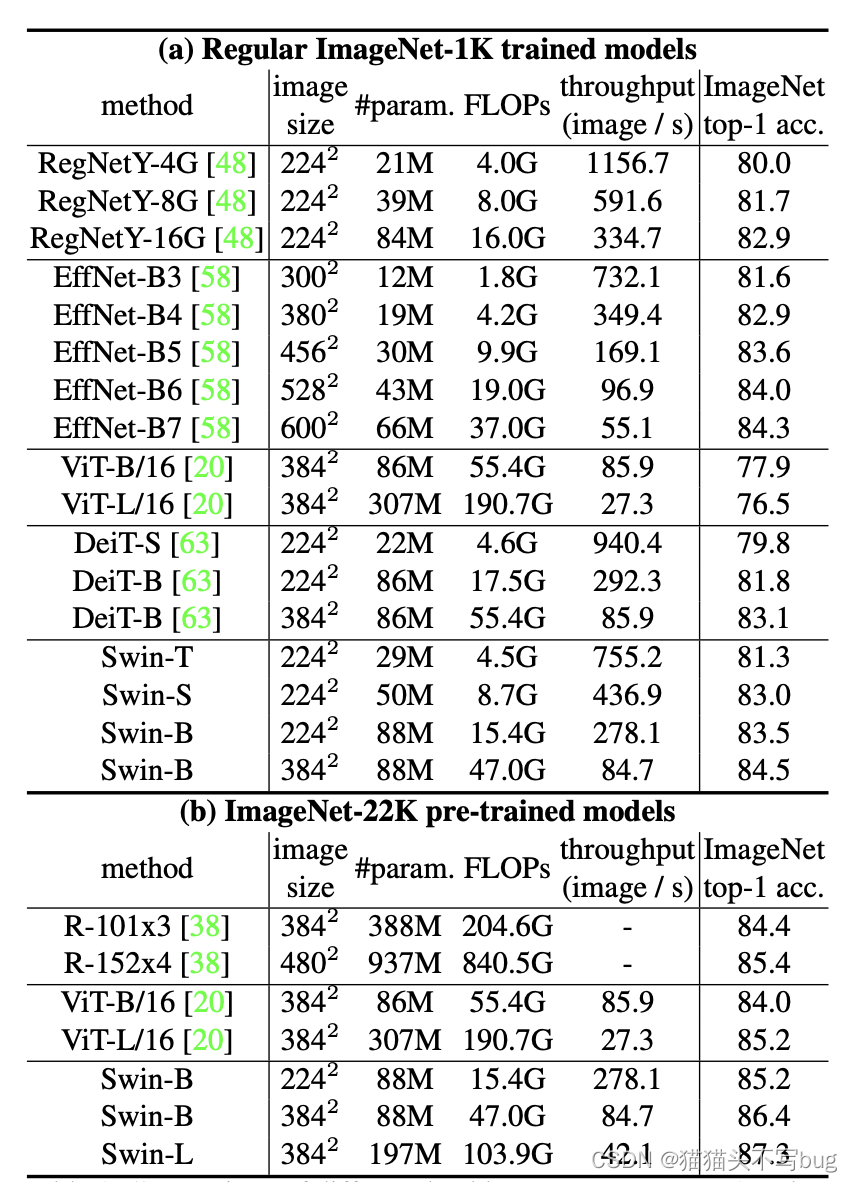
- 表a是在ImageNet1k上做训练和测试。可以看出Swin-B和EfficienNet可以说是伯仲之间。
- 表b是在ImageNet2K上做预训练,并在1k上做微调,可以看出,随着数据集增大,性能变好了。超过了ViT。
4.2 Object Detection on COCO
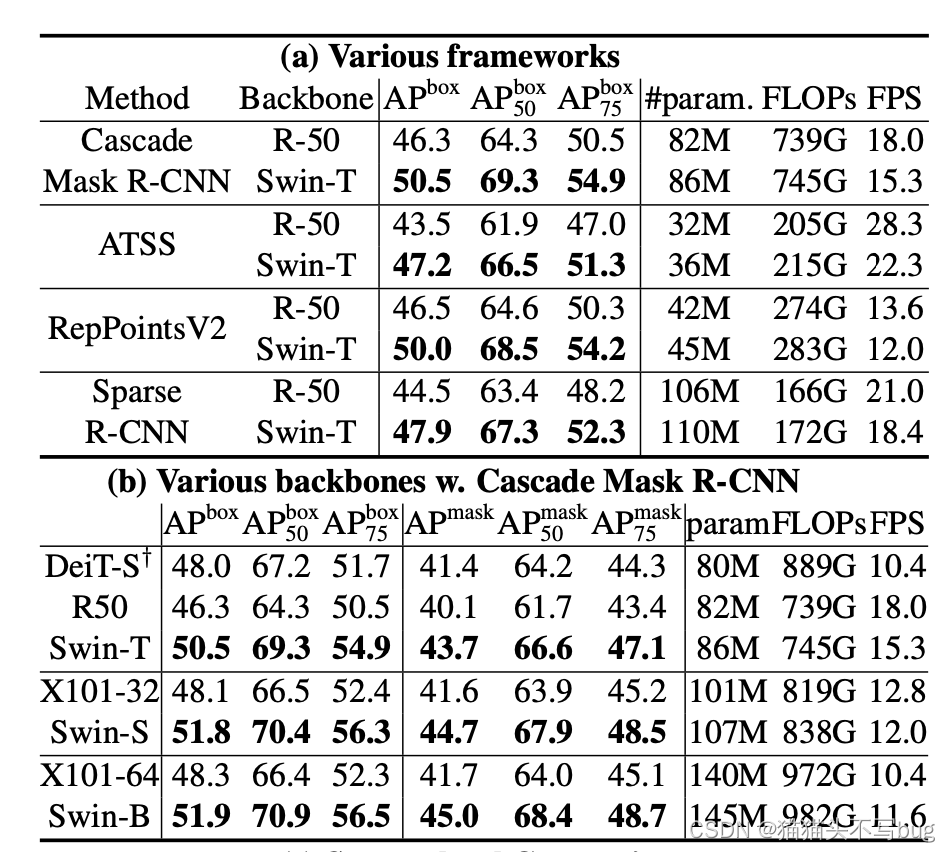
Swin-Transformer作为backbone大大提升了目标检测精度:
系统比较如下:
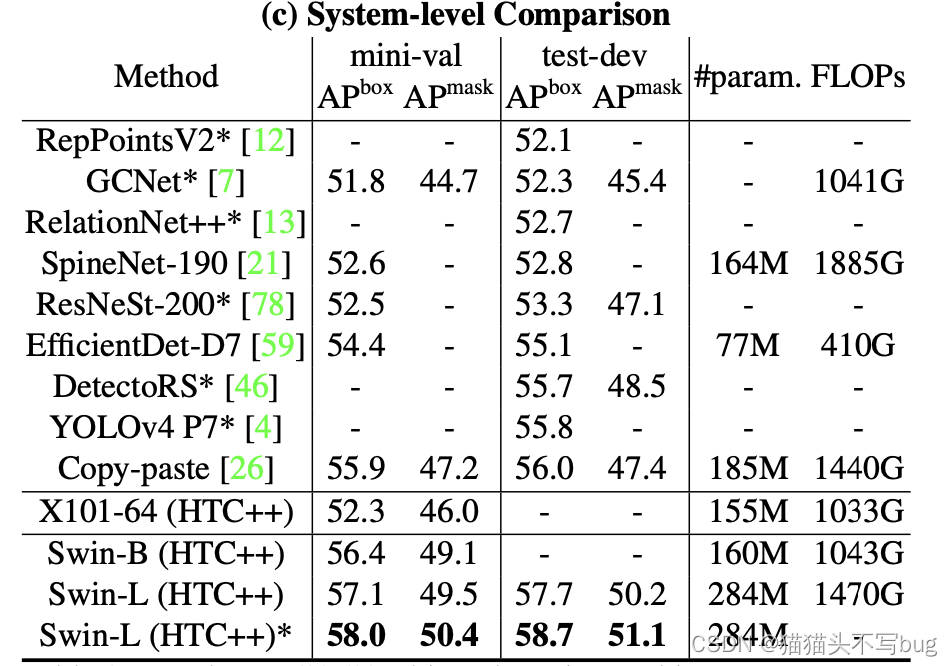
†表示使用额外的去卷积层来生成分层特征图。*表示多尺度测试。
4.3 Semantic Segmentation on ADE20K
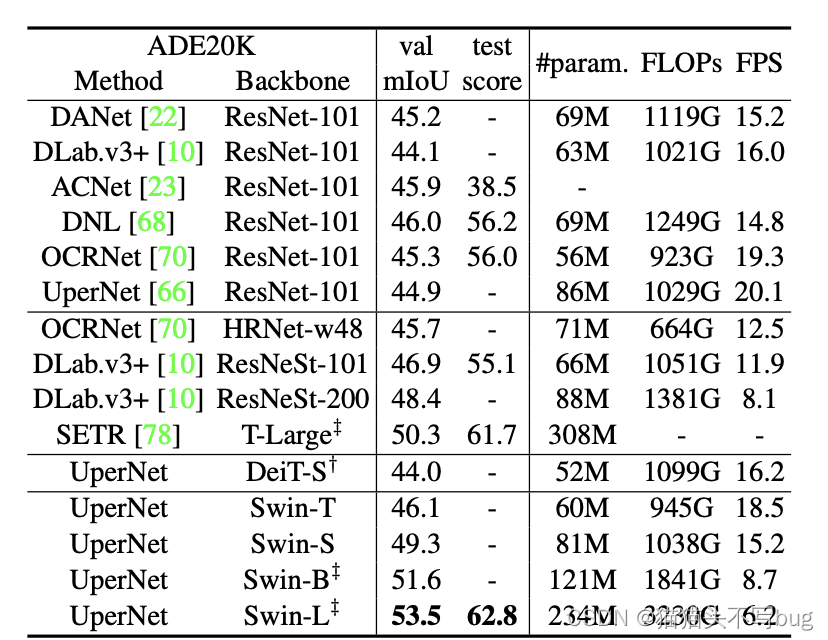
†表示使用额外的反卷积层来生成分层要素图。‡表示,该模型已在ImageNet-22K上进行了预训练。
4.4 Ablation Study
说明移动窗口和相对位置编码的有效性。主要作用于下游任务。进一步说明Swin-Transformer适合密集型预测。
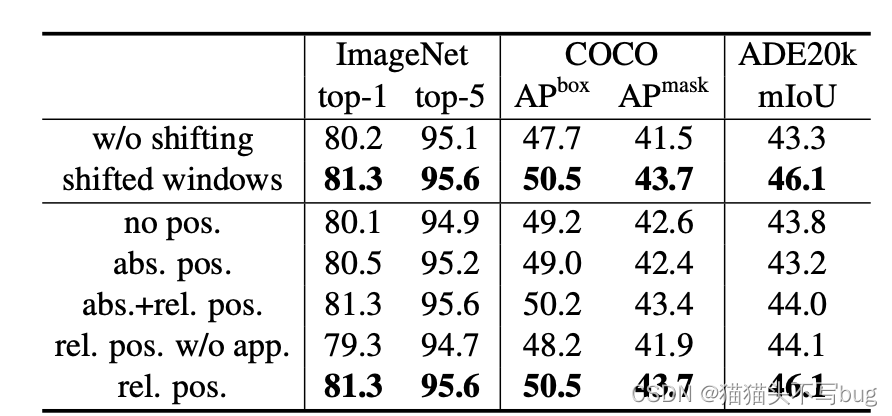
W/O移位:所有的自我注意模块都采用规则的窗口分区,没有移位;abs.pos:vit的绝对位置嵌入项;rel.pos:带有附加相对位置偏差项的默认设置

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









