









 本文探讨了如何使用纯Transformer结构解决视觉领域的挑战,提出ViT方法,通过划分小patch并应用Transformer编码器,实现了与CNN相当的性能,且在大规模数据集上节省训练资源。实验展示了ViT在预训练和Fine-tuning方面的优势,特别是在处理高分辨率图像和小样本学习上的表现。
本文探讨了如何使用纯Transformer结构解决视觉领域的挑战,提出ViT方法,通过划分小patch并应用Transformer编码器,实现了与CNN相当的性能,且在大规模数据集上节省训练资源。实验展示了ViT在预训练和Fine-tuning方面的优势,特别是在处理高分辨率图像和小样本学习上的表现。
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
1. Motivation
- 在视觉领域,自注意力机制也只是部分替代卷积网络或者和卷积网络一起用,还是保持总体结构不变的。
- Transformer用于图像数据往往存在计算复杂度大或者不能兼顾全局信息等问题。
2. Contribution
- 提出使用纯Transformer结构用于视觉领域, 可以取得和CNN相媲美的结果,而且对于大规模数据集,需要更少的训练资源。
- 将图片分为若干个patch,将patch作为一些序列传入Transformer。降低复杂度。
3. Method
3.1 Vision Transformer
Structure:
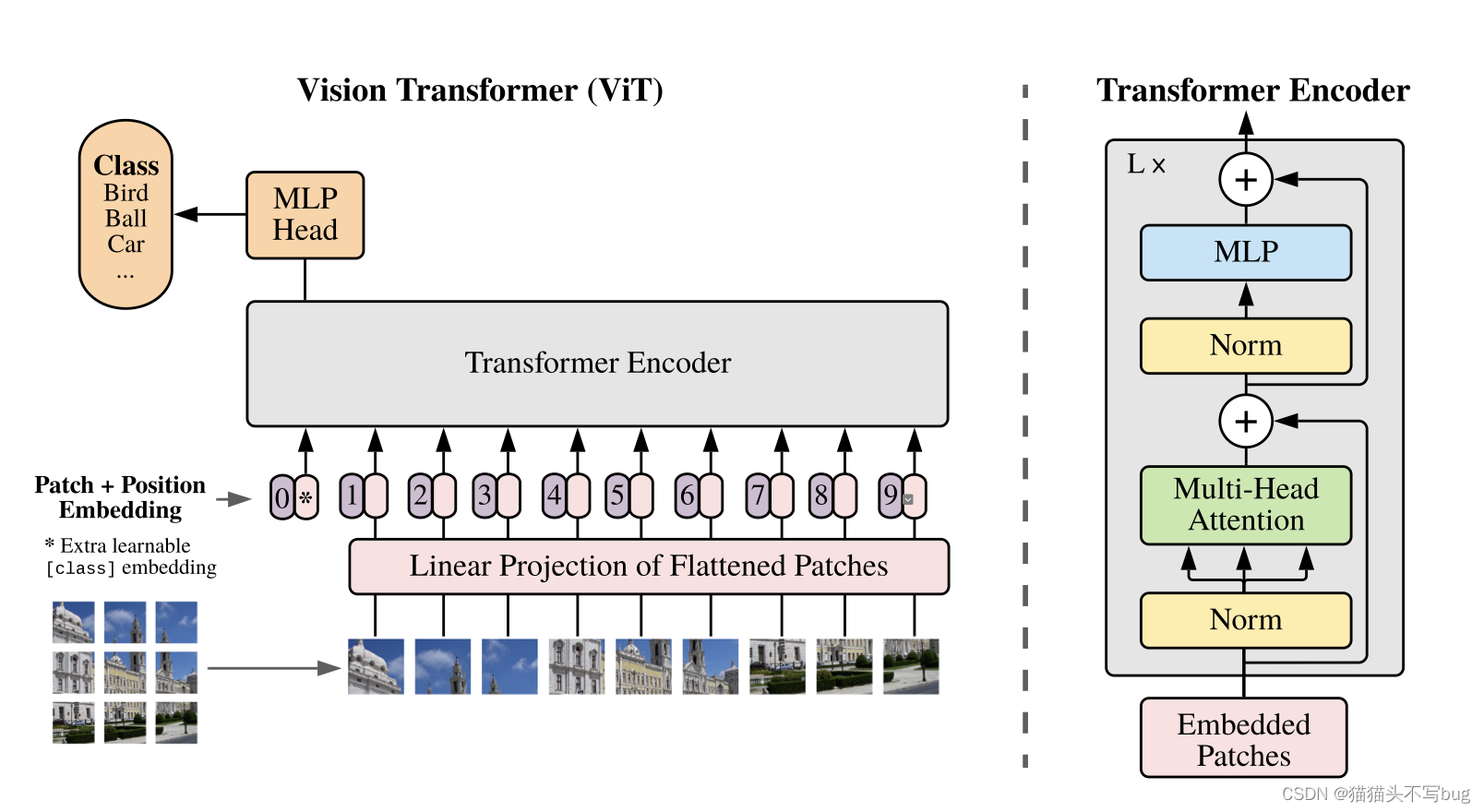
- 输入一张图(2242243),划分patch(16 × \times × 16 × \times × 3 = 768,一共196个patch);
- 每个patch经过线性投射层(FC层,维度768 × \times × 768)的操作得到一个特征(Patch Embedding,输出196 × \times × 768);
- 于此同时对于patch的顺序信息,增加一个Position Embedding(1 × \times × 768,对于位置编码信息是直接加到patch embedding上的);
- 传入Transformer Encoder,得到一个输出;
- 为了表示类别信息,增加了额外的class embedding(1 × \times × 768),用于最后的图像分类。
输入输出维度解释:
- 整体输入到Transformer的长度:(196+1) × \times × 768
- 传入到Transformer后因为是多头注意力,一共分为12个头所以传入的K,Q,V维度是197 × \times ×(768/12)
- MLP会先把维度放大成197 × \times × 3072,再变成197 × \times × 768,最后输出
关于class embedding:使用ResNet做特征提取得到一个特征图,再在这个特征图上做GAP(Globally Average Pooling)
关于归纳偏置: ViT比CNN少了许多归纳偏置,CNN的locality(局部像素之间的语义连续性)和translation equivalence(平移等变性)在每一层都有体现而ViT只有在MLP层。自注意力层是全局的,关于图像patch的距离以及场景信息都需要重头学习。这就解释了为什么ViT在中小数据集上效果不如CNN。
**混合网络:**不再进行划分patch操作而是将图像传入CNN得到一个特征图,再将特征图拉直成一维向量传入Transformer
3.2 Fine-tuning and Higher Resolution
对于处理大尺寸图片,patch数量增多所以输入序列长度更长。Transformer其实是可以处理任意长度的,但是这样的话预训练的位置编码就没意义了。针对这种情况对预训练的位置编码简单做个2D插值。
4. Experiment
在不同大小数据集上做预训练,然后在许多数据集上做测试。在预训练的计算代价方面,ViT表现的很好。
DataSet:ImageNet-1K,JFT。下游任务都是分类,使用的都是 CIFAR-10/100,Oxford-IIIT Pets等。
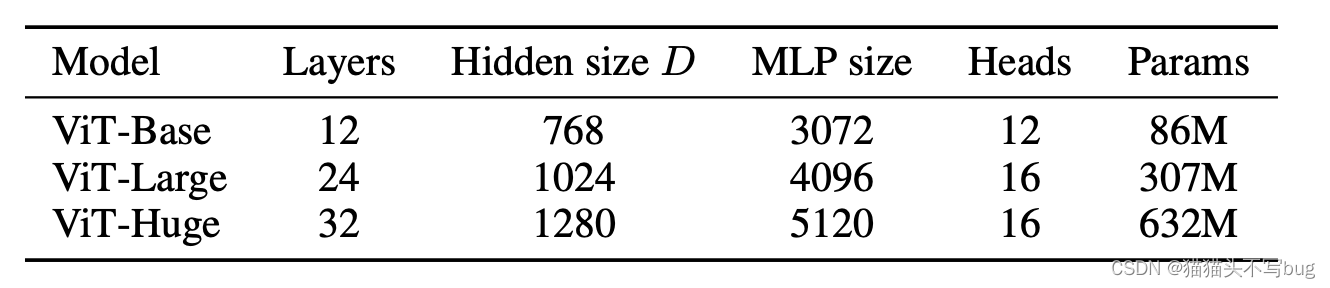
模型规模:
实验结果:
1.和CNN做对比
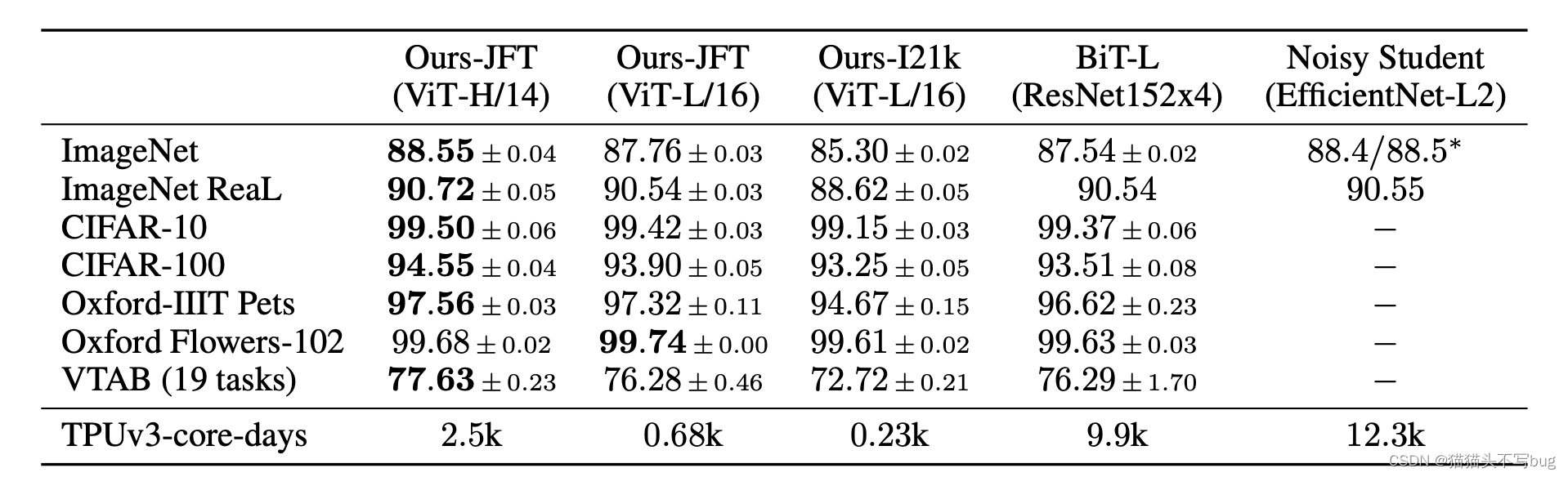
注: ViT-H/14表示使用ViT- Huge模型patch size是14*14。
上表是已经在大规模数据集上进行预训练了,在其他数据集上做Fine- Tune。和CNN主要是和BiT和Nosiy Student做对比。
2. ViT需要多少张图做预训练可以达到比较好的效果:
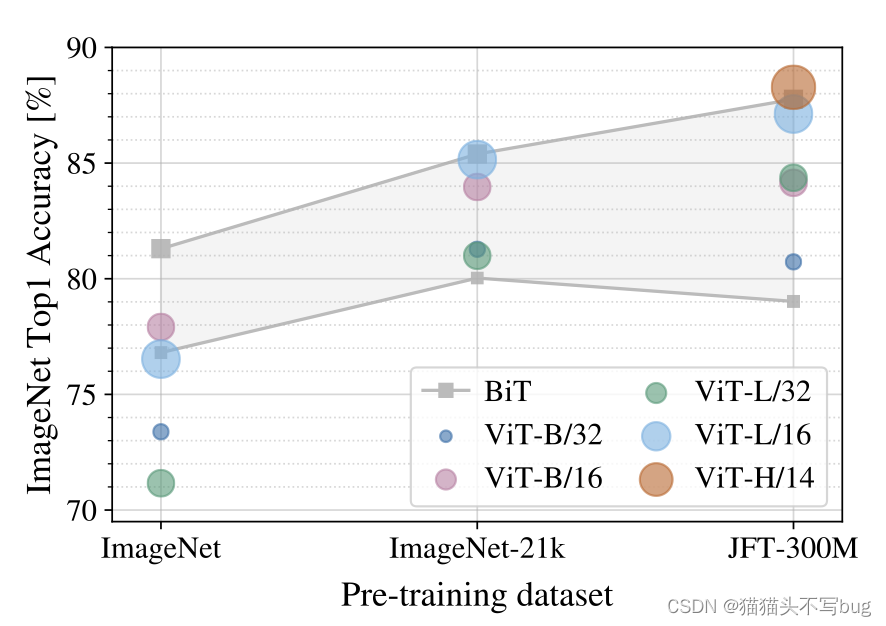
灰色区域是resent可以达到的效果范围。在中小型数据集上预训练,ViT是不如resent的,只有在大型数据集上预训练,ViT表现要比resent好。
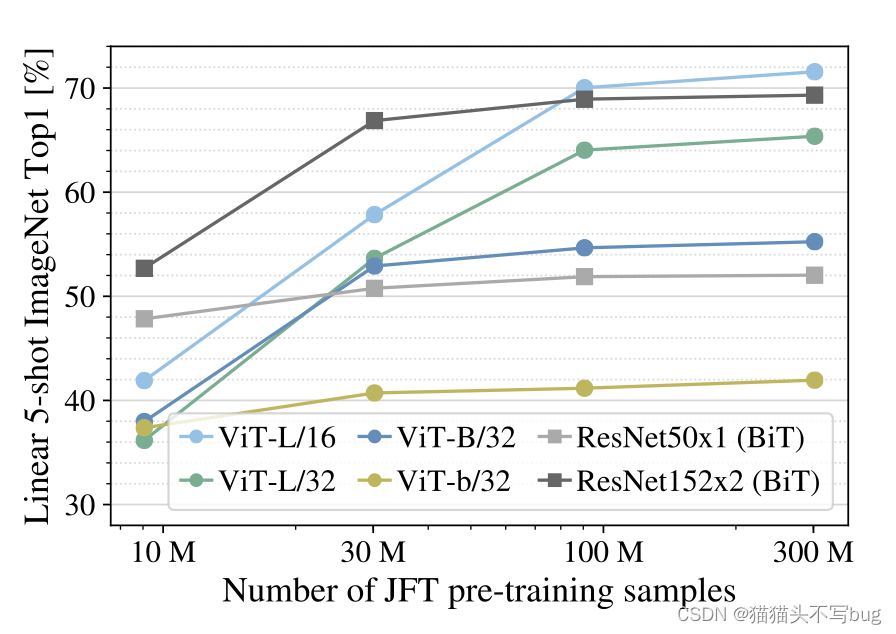
3. Linear few shot evaluation
将预训练的模型直接作为一个特征提取器。然后在其他数据集上选取5个样本做evaluation。(ViT小样本学习)
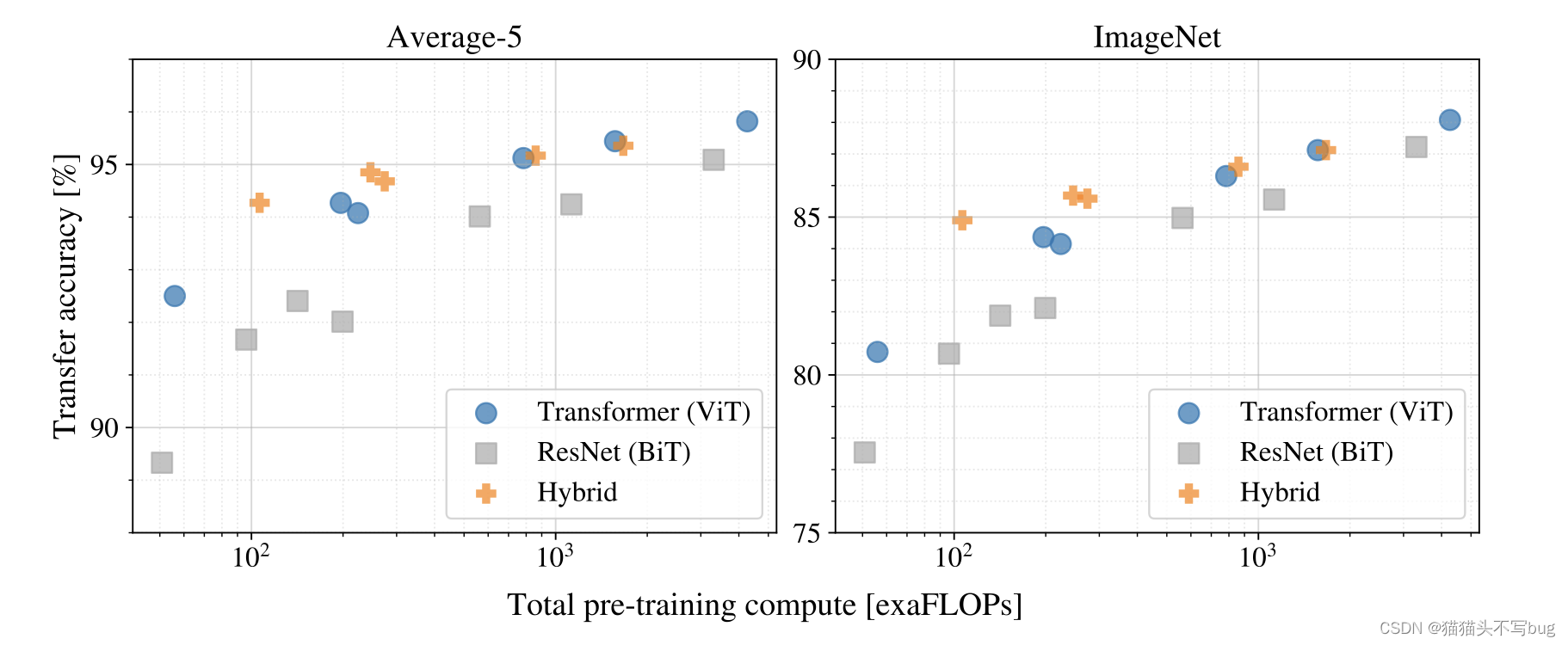
4. 预训练比卷积便宜
average-5是五个数据集平均;所有模型都在大规模数据集上预训练。在同等的训练预算下,各个模型在测试数据集上的表现。在相同的计算预算下,视觉变形器的性能通常优于ResNets。混合体在较小的模型规模下比纯粹的变形器更胜一筹,但在较大的模型中差距消失了。
5.一些可视化
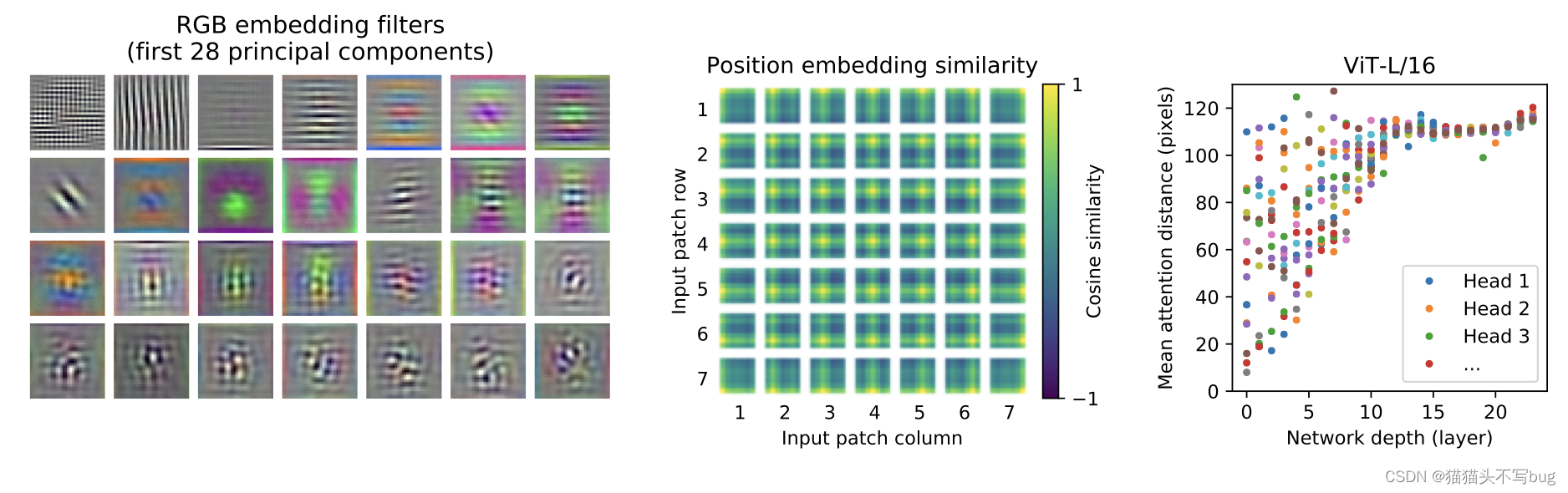
- 左边的表示ViT-L/32的RGB值的初始线性嵌入的过滤器可以学到一些颜色已经纹理特征。
- 中间是1D位置编码相似性,显示了具有指定行和列的patch的位置嵌入与所有其他patch的位置嵌入之间的余弦相似度。可以看到学到了距离信息以及一些行列信息。
- 右边是按头部和网络深度(ViT-L一共24层)计算的注意区域的大小。每个点表示一个层的16个头中的一个的平均注意距离(像素点ab之间的距离*ab之间注意力权重)。可以看到一开始注意力模型就可以关注到全局信息。
自监督:通过mask掉一些patch实现自监督。对比学习也是未来一个研究方向。

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









