









End-to-End Object Detection with Transformers
1. Motivation
- 现有的目标检测器往往通过间接的方式来完成检测任务——anchor、proposals、window center等。这些检测器的性能受后处理影响大。
2.Contribution
- 提出将目标检测视为一个直接集合预测问题(end-to-end Object Detection)。
- 基于Transformer编码器-解码器架构,其自注意力机制可以有效去除重复检测。
- 基于集合的全局损失函数,通过二分匹配以及transformer编码器-解码器体系结构强制进行唯一预测。

3. Related Work
3.1 Set Prediction
集合预测:输入一副图像,网络的输出就是最终的预测的集合(也不需要任何后处理)能够直接得到预测的集合就已经达到了检测的目的了。
在目标检测任务上,集合预测往往存在一定困难,比如:近乎相似的box。传统的目标检测器依赖于后处理,比如NMS。但是集合预测是不需要后处理的。它需要全局推理方案,对所有预测的元素之间的相互作用进行建模,以避免冗余。对于恒定大小的集合预测,密集的全连接网络是足够的,但成本很高。
一般的做法就是在匈牙利算法的基础上设计一个损失函数,用来match ground-truth和预测值。
3.2 Transformers and Parallel Decoding
Transformer:引入自注意力机制,对整个序列进行信息聚合。其主要优势在于它的全局计算以及记忆能力。十分适合处理长序列数据。
具体可以阅读论文:https://arxiv.org/abs/1706.03762
参考博客:论文阅读——Attention is all you need
4. Method
4.1 Object detection set prediction loss
step1. 预测值和GT值之间产生一个最佳匹配,然后优化特定对象的bbox的损失。
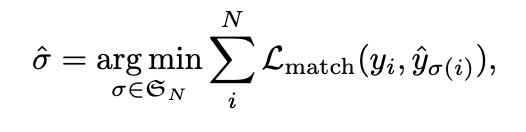
- L m a t c h ( y i , y ^ σ ( i ) ) L_{match}(y_i,\hat{y}_{\sigma(i)}) Lmatch(yi,y^σ(i)):表示的是GT值 y i y_i yi和预测值 y ^ σ ( i ) \hat{y}_{\sigma(i)} y^σ(i)之间的匹配损失。 σ \sigma σ是N个预测值的排列组合。N远大于真实目标数量,GT值集合y的size也是N,用 ϕ \phi ϕ(no object)填充。
- 上式是为了找出一组排列组合使得损失值最小。
-
L
m
a
t
c
h
(
y
i
,
y
^
σ
(
i
)
)
L_{match}(y_i,\hat{y}_{\sigma(i)})
Lmatch(yi,y^σ(i))可以定义成:
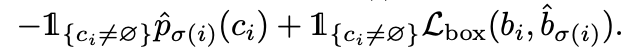
GT值 y i = ( c i , b i ) y_i = (c_i,b_i) yi=(ci,bi),其中 c i c_i ci是目标类别信息, b i b_i bi是bbox信息(x, y, w, h)。我们用 p ^ σ ( i ) ( c i ) \hat{p}_{\sigma(i)}(c_i) p^σ(i)(ci)来表示预测类别为 c i c_i ci的概率。 σ ( i ) \sigma(i) σ(i)是某个排列组合中ground truth的第i个元素对应的predictions的index。 1{}是花括号内为真时取1
step2. 计算损失(优化),即上一步中匹配的所有配对的匈牙利损失。
损失函数可以定义为:
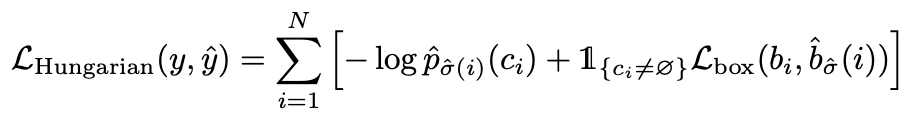
σ ^ \hat{\sigma} σ^是第一步中的最佳分配。
关于bbox损失:
常用的L1loss,对于不同尺寸的bbox会有不同的尺度,尽管他们的相对误差相似。为了缓解这个问题,采取L1loss和IOU loss的线性组合:
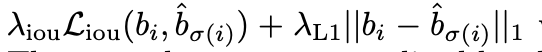
4.2 Structure

- CNN backbone:用于特征提取。输入 3 × H 0 × W 0 3 \times H_0 \times W_0 3×H0×W0输出特征图 f ∈ R C × W 0 32 × H 0 32 , C = 2048 f \in R^{C \times \frac{W_0}{32} \times \frac{H_0}{32}}, C = 2048 f∈RC×32W0×32H0,C=2048
- Transformer Encoder:首先,一个1x1的卷积将高层激活图f的通道维度从C减少到一个较小的维度d,输入一个 d × H W d \times HW d×HW的特征图。并且额外增加一个positional encoding,将其加入到注意力层输入中。
- Transformer Decoder:输入embedding是学习到的位置编码,这里称之为object query。N个object query被转化为一个输出embedding然后它们被独立解码为bbox坐标和类别标签。模型在每个解码层平行解码N个对象。最终产生N个预测结果。
- FFN(Feed Forward Network):预测的是一个固定大小的N个边界框(中心坐标以及高度宽度),其中N通常比图像中感兴趣的物体的实际数量大得多,因此,一个额外的特殊类label ϕ \phi ϕ被用来表示在一个slot内没有检测到物体。
- 辅助损失:在解码层后面添加FFN和匈牙利损失,使用一个额外的共享层规范来规范来自不同解码层的预测FFN的输入
5. Experiment
- 在COCO数据集上和Faster RCNN做比较:

- backbone使用的是ResNet50(DETR)和ResNet100(DETR-R101)
- 在backbone的最后一个阶stage增加一个扩张,并从这个stage的第一个卷积中去除一个stride=2来提高特征分辨率。相应的模型被称为DETR-DC5和DETR-DC5-R101(扩张C5 stage)。输出分辨率提高了2倍,提升小目标检测。但是也增加了计算代价。
- 第一个session是Faster RCNN在Detectron2上的结果,训练策略是3x schedule(1x 策略表示:在总batch size为16时,初始学习率为0.02,在6万轮和8万轮后学习率分别下降10倍,最终训练9万轮。3x 策略为1x策略的三倍,同时学习率调整位置也为1x的三倍。)。
- 第二个session是Faster RCNN使用GIoU并且增加了训练epoch的结果。
- 第三个session,展示了多个DETR模型结果(一个具有6个transformer和6个解码器层的模型,宽度为256,有8个注意头。以保证参数量上有可比性)。
- AP:AP在变量为IoU的threshold∈(0.50:0.95:0.05)时的积分;AP50,AP75:IoU的threshold为0.5和0.75时的AP;APS,M,L:小对象的AP,中等大小的AP,大对象AP。
- DETR for panoptic segmentation
DETR也可以用于实例全景分割。可以通过在解码器输出上添加mask头,从而实现全景分割。全局分割头说明:

实验结果(on COCO val Dataset):

- RQ(recognition quality)识别质量
- SQ(segmentation quality)分割质量
- PQ(Panoptic quality)全景质量
- 上标th和st分别表示thing和stuff的分类
- 人,车等有固定形状的物体属于 things 类别,可数名词通常属于 thing
- 天空,草地等没有固定形状的物体属于 stuff 类别,不可数名词属于 stuff
为了预测最终的全景分割,我们只需在每个像素的掩码分数上使用argmax,并将相应的类别分配给得到的掩码。
报告了全景质量(PQ)和物品(PQth)和材料(PQst)的细分。















 1750
1750











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









