







Hadoop基础
了解hadoop
我们生活在一个数据大爆炸的时代,数据飞速的增长,急需解决海量数据的存储和计算问题
Hadoop适合海量数据 分布式存储 和 分布式计算
Hadoop的作者是Doug Cutting, Hadoop这个名字是他的孩子给他的毛绒象玩具起的名字
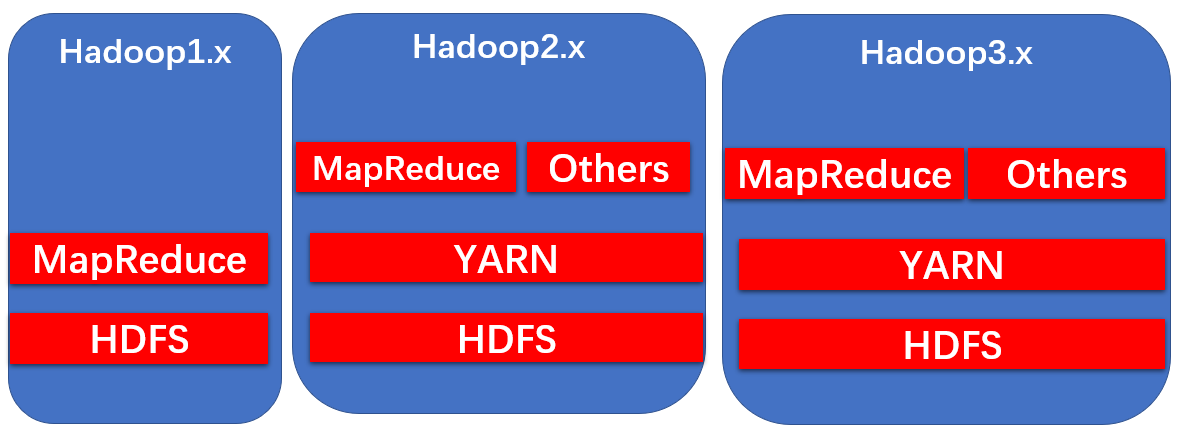
Hadoop3.x的细节优化

Hadoop三大核心组件介绍
Hadoop主要包含三大组件:HDFS + MapReduce+YARN

HDFS负责海量数据的份布式存储
MapReduce是一个计算模型,负责海量数据的 分布式计算
YARN主要负责 集群资源的管理和调试
伪分布集群
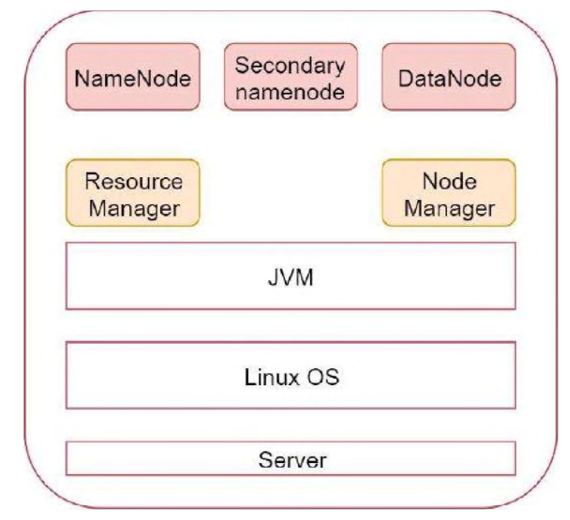
分布式集群
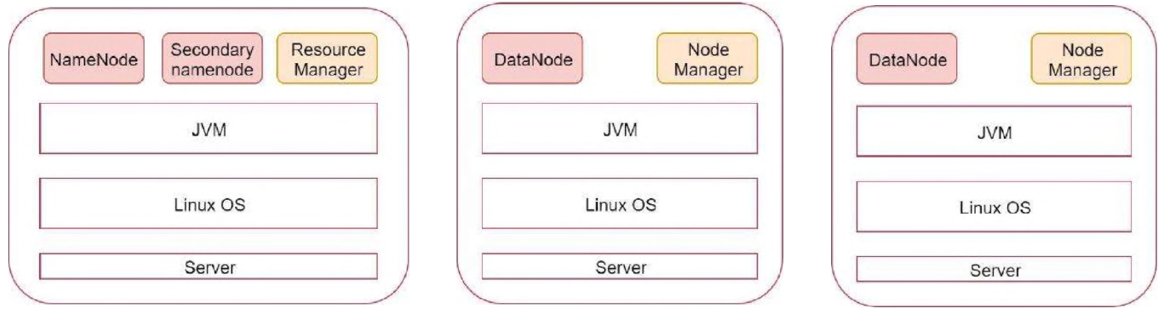
Hadoop安装
配置文件修改
需使用notepad++配合插件nppftp修改
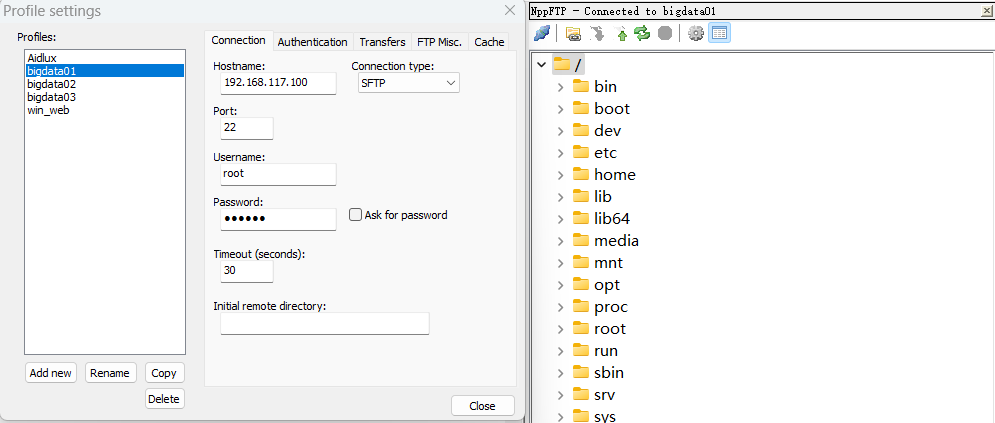
hadoop-env.sh
需要自行创建目录:/home/data/logs
export JAVA_HOME=/home/softwares/jdk
export HADOOP_LOG_DIR=/home/data/logs
hdfs-site
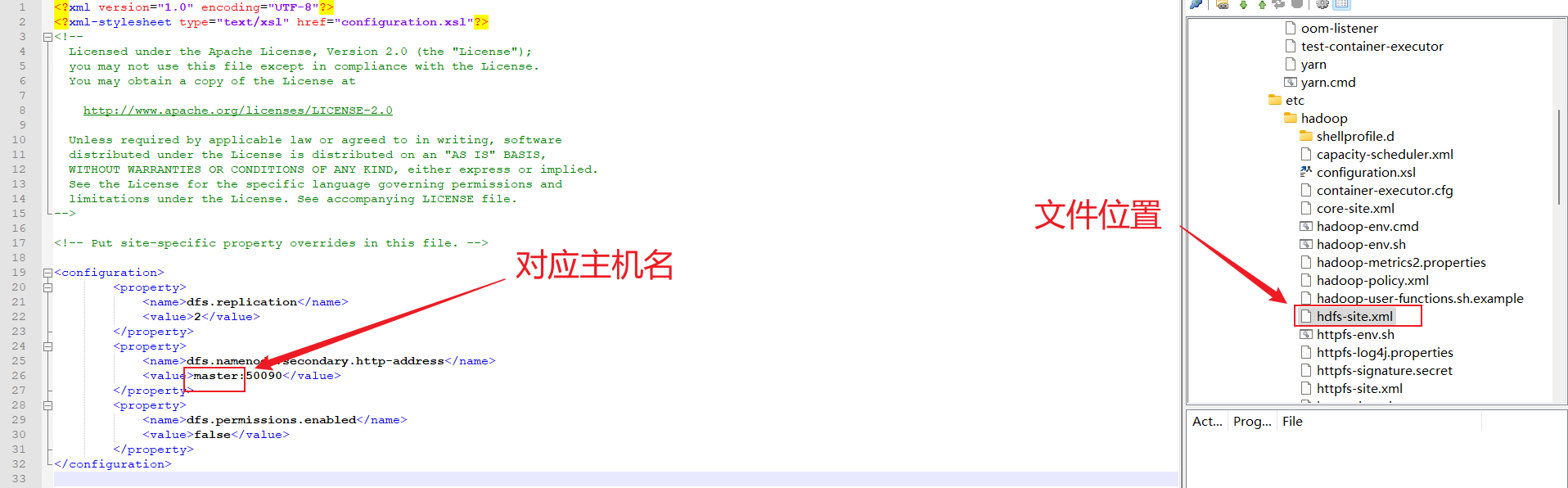
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>bigdata01:50090</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
mapred-site
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!--
<property>
<name>mapreduce.job.tracker</name>
<value>hdfs://bigdata01:8001</value>
<final>true</final>
</property>
-->
</configuration>
yarn-site
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>bigdata01</value>
</property>
<!--new add config-->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistory/logs</value>
</property>
</configuration>
etcprofile
export JAVA_HOME=/home/softwares/jdk
export HADOOP_HOME=/home/softwares/hadoop
export ZOOKEEPER_HOME=/home/softwares/zookeeper
export HIVE_HOME=/home/softwares/hive
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin
export PATH=$PATH:/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://bigdata01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/softwares/hadoop/data/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
workers
bigdata02
bigdata03
备注:此处为workers,不是workers.sh !!
修改启动脚本
修改 start-dfs.sh , stop-dfs.sh 这两个脚本文件,在文件前面增加如下内容
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
修改 start-yarn.sh , stop-yarn.sh 这两个脚本文件,在文件前面增加如下内容
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
把bigdata01节点上将修改好配置的安装包拷贝到其他两个从节点
cd /home/softwares/
scp -rq hadoop bigdata02:/home/softwares/
scp -rq hadoop bigdata03:/home/softwares/
Hadoop操作
格式化hdfs
hdfs namenode -format
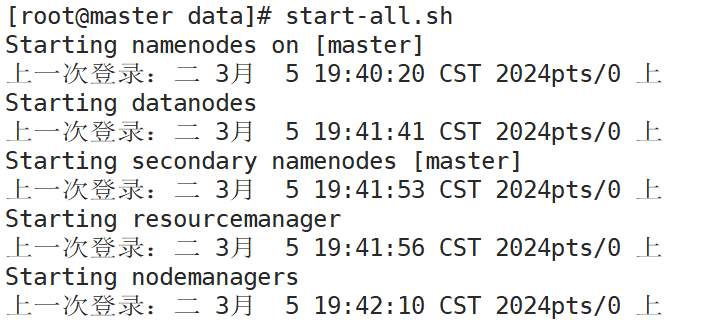
启动集群
start-all.sh
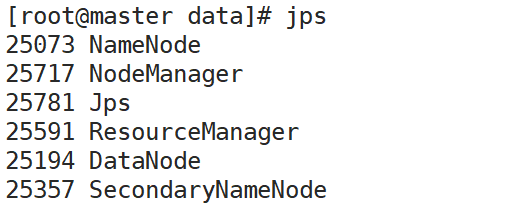
验证
jps
停止
stop-all.sh

















 3231
3231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











