






pytorch(分布式)数据并行个人实践总结——DataParallel/DistributedDataParallel - fnangle - 博客园 (cnblogs.com)
model = nn.DataParallel(model)测试结果相差特别多(如下图所示),加了这句mIoU是第一个结果0.8847,没加是0.4929(以mIoU为例,可以看到其他各项指标也都掉的严重),所以决定花点心思把nn.DataParallel(model)搞清楚。
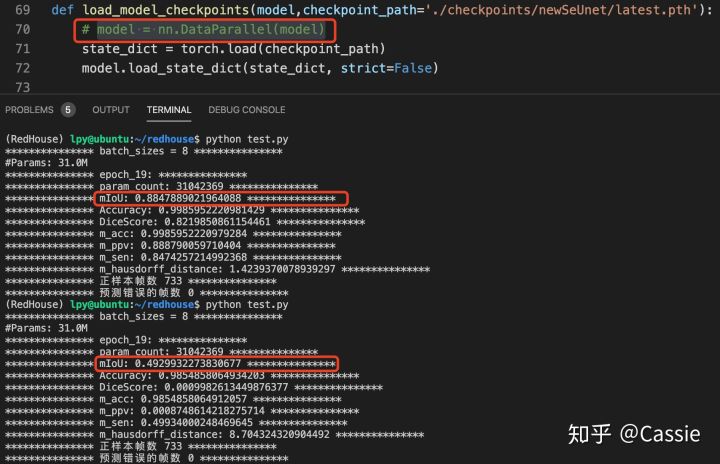
指标结果掉的严重
这里需要注意一下:多卡训练要考虑通信开销的, 是个trade-off的过程,不见得四块卡一定比两块卡快多少,训练到四块卡的时候可能io通信开销已经占了大头。
nn.DataParallel()
(我是单机多卡训练,首先送上官网nn.DataParallel()链接)
CLASS torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)- 参数定义
module是要放到多卡训练的模型;
device_ids数据类型是一个列表, 表示可用的gpu卡号;
output_devices数据类型也是列表,表示模型输出结果存放的卡号(如果不指定的话,默认放在0卡,这也是为什么多gpu训练并不是负载均衡的,一般0卡会占用的多,这里还涉及到一个小知识点——如果程序开始加os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3", 那么0卡(逻辑卡号)指的是2卡(物理卡号))。
- 如何多卡加速训练
讲原理:
网络在前向传播的时候会将model从主卡(默认是逻辑0卡)复制一份到所有的device上,input_data会在batch这个维度被分组后upload到不同的device上计算。在反向传播时,每个卡上的梯度会汇总到主卡上,求得梯度的均值后,再用反向传播更新单个GPU上的模型参数,最后将更新后的模型参数复制到剩余指定的GPU中进行下一轮的前向传播,以此来实现并行。有多少个gpu参与计算就有多少个gradient求平均,关于gradient求平均是否合理以及如何改进可以参考:
除了model和data,其他数据的分配规则如下:允许将Arbitrary positional和keyword添加到所有gpu上并行计算, 但有些数据类型是专门处理的。tensor将分配到指定的卡上,默认为0(这个地方我可能理解的不对,原话是“tensors will be scatteredon dim specified (default 0)”如果有人有其他正确的理解,望不吝赐教)。对元组、列表和字典类型的数据浅拷贝后复制到其他卡上。
举例子:
import torch
import torch.nn as nn
os.environ['CUDA_VISIBLE_DEVICES']='1, 2' # 指定逻辑卡号。比如这样写的话,第0块卡指的是物理上的第2块
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
input = torch.randn(8, 4, 160, 160).to(device) # 将数据放到gpu上
model = nn.Conv2d(4, 3, kernel_size = 3, stride = 1, padding = 1)
model = model.to(device)# 将模型放到gpu上
output = model(input)
model = torch.nn.DataParallel(model, device_ids=[0, 1])补充DP的参数更新方式(ref:Gemfield:PyTorch的分布式)
- DataLoader把数据通过多个worker读到主进程的内存中;
- 通过tensor的split语义,将一个batch的数据切分成多个更小的batch,然后分别送往不同的cuda设备;
- 在不同的cuda设备上完成前向计算,网络的输出被gather到主cuda设备上(初始化时使用的设备),loss而后在这里被计算出来;
- loss然后被scatter到每个cuda设备上,每个cuda设备通过BP计算得到梯度;
- 然后每个cuda设备上的梯度被reduce到主cuda设备上,然后模型权重在主cuda设备上获得更新;
- 在下一次迭代之前,主cuda设备将模型参数broadcast到其它cuda设备上,完成权重参数值的同步。
(p.s. broadcast是主进程将相同的数据分发给组里的每一个其它进程;scatter是主进程将数据的每一小部分给组里的其它进程;gather是将其它进程的数据收集过来;reduce是将其它进程的数据收集过来并应用某种操作(比如SUM)在gather和reduce概念前面还可以加上all,如all_gather,all_reduce,那就是多对多的关系了.)
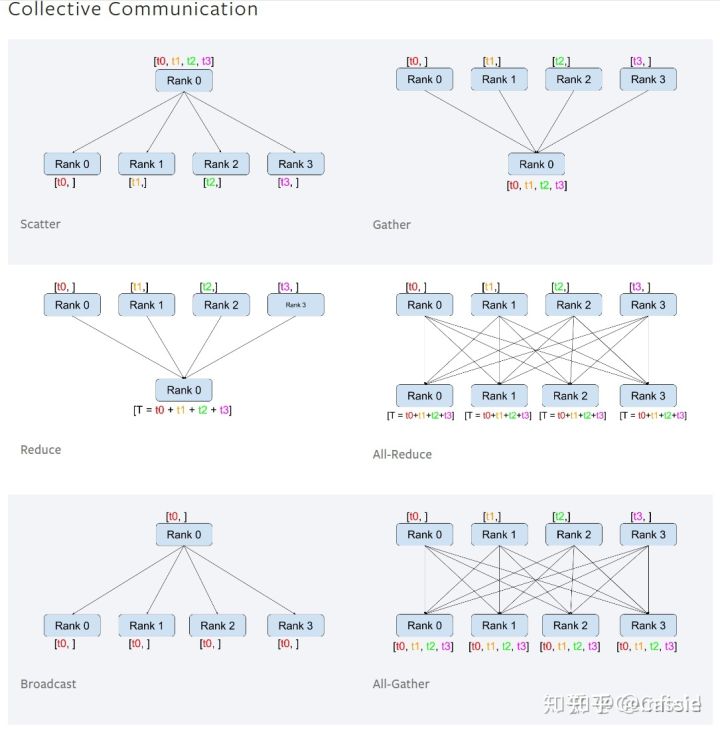
来源 @Gemfield
(分割线⬆️)
如果写到这就戛然而止,就和CSDN上那些小笔记的就没什么区别了...当时用多卡训练,我选择nn.DataParallel(model)纯属因为它简单,只要两三行代码就能实现,今天再看官网,人家白底黑字写着warning和recommended:

nn.DataParallel的warning
关于nn.DataParallel(以下简称DP)和DistributedDataParallel(以下简称DDP)的区别:
- DDP通过多进程实现的。也就是说操作系统会为每个GPU创建一个进程,从而避免了Python解释器GIL带来的性能开销。而DataParallel()是通过单进程控制多线程来实现的。还有一点,DDP也不存在前面DP提到的负载不均衡问题。
- 参数更新的方式不同。DDP在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由
rank=0的进程,将其broadcast到所有进程后,各进程用该梯度来独立的更新参数而 DP是梯度汇总到GPU0,反向传播更新参数,再广播参数给其他剩余的GPU。由于DDP各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个 optimizer,对各个GPU上梯度进行求平均,而在主卡进行参数更新,之后再将模型参数 broadcast 到其他GPU.相较于DP, DDP传输的数据量更少,因此速度更快,效率更高。 - DDP支持 all-reduce(指汇总不同 GPU 计算所得的梯度,并同步计算结果),broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信,缓解了“写在前面“提到的进程间通信有大的开销问题。
唯一不好的地方是DDP相对后者来说,使用起来会有些麻烦(不然当时我也不会两三行就能实现的DP了),下面我们一起借助官网教程,看看它具体怎么用的吧~
(recommended to use)DistributedDataParallel (既可单机多卡又可多机多卡)
先奉上官网nn.DistributedDataParallel(model)链接
CLASS torch.nn.parallel.DistributedDataParallel(module, device_ids=None, output_device=None,
dim=0, broadcast_buffers=True, process_group=None, bucket_cap_mb=25,
find_unused_parameters=False, check_reduction=False)- 参数定义
module是要放到多卡训练的模型;
device_ids数据类型是一个列表, 表示可用的gpu卡号;
output_devices数据类型也是列表,表示模型输出结果存放的卡号(如果不指定的话,默认放在0卡,这也是为什么多gpu训练并不是负载均衡的,一般0卡会占用的多,这里还涉及到一个小知识点——如果程序开始加os.environ["CUDA_VISIBLE_DEVICES"] = "2, 3", 那么0卡(逻辑卡号)指的是2卡(物理卡号))。
dim指按哪个维度进行数据的划分,默认是输入数据的第一个维度,即按batchsize划分(设数据数据的格式是B, C, H, W)
其他参数可以康康官网的解释(我没太看懂,就用默认的好了)
- 分布式的几个概念
1.group:即进程组。默认情况下,只有一个组,一个 job 即为一个组,也即一个 world。 当需要进行更加精细的通信时,可以通过 new_group 接口,使用 word 的子集,创建新组,用于集体通信等;
2.world size:表示全局进程个数;
3.rank:表示进程序号,用于进程间通讯,表征进程优先级。rank = 0 的GPU为主卡;
4.local_rank:进程内,GPU 编号,非显式参数,由torch.distributed.run(torch.distributed.launch已在21年6月份被废弃)内部指定。比方说, rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU.
- 如何多卡加速训练
讲原理:
DDP在各进程梯度计算完成之,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将其 broadcast 到所有进程后,各进程用该梯度来独立的更新参数而 DP是梯度汇总到GPU0,反向传播更新参数,再广播参数给其他剩余的GPU。由于DDP各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。而在DP中,全程维护一个 optimizer,对各个GPU上梯度进行求,而在主卡进行参数更新,之后再将模型参数 broadcast 到其他GPU.相较于DP, DDP传输的数据量更少,因此速度更快,效率更高。
举例子(踩坑无数后,亲测成功!!):
先介绍各个过程,最后总结代码段
1.init_process_group初始化进程组(如果需要进行前面提到的小组内集体通信,用new_group创建子分组);
# 初始化使用nccl后端,官网还提供了‘gloo’作为backend,俺觉得知道nccl是用来GPU之间进行通信的就可以
torch.distributed.init_process_group(backend="nccl")2.使用DistributedSampler(改dataloader中sampler=train_sampler)
# train_dataset就是自己的数据集
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle = (train_sampler is None), sampler=train_sampler, pin_memory=False)p.s.pin_memory(固定内存)设为True会加速训练(但官网给到但参数设置是False)。
3.创建DDP模型进行分布式训练
# DDP是all-reduce的,即汇总不同 GPU 计算所得的梯度,并同步计算结果。all-reduce 后不同 GPU 中模型的梯度均为 all-reduce 之前各GPU梯度的均值。
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)4.最后一步,执行python train.py时需加参数
python -m torch.distributed.run --nnodes=1 --nproc_per_node=2 --node_rank=0 --master_port=6005 train.py代码段总结
###DDP
# 引入包
import argparse
import torch.distributed as dist
# 设置可选参数
parser = argparse.ArgumentParser()
parser.add_argument('--local_rank', default=0, type=int,
help='node rank for distributed training')
args = parser.parse_args()
# print(args.local_rank)
dist.init_process_group(backend='nccl')
# 1.上面讲到的初始化进程组
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
# 2.使用DistributedSampler
train_sampler = torch.utils.data.distributed.DistributedSampler(train_dataset)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle = (train_sampler is None), sampler=train_sampler, pin_memory=False)
# 3.创建DDP模型进行分布式训练
model = nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)
# 4.命令行开始训练 --nproc_per_node参数指定为当前主机创建的进程数(比如我当前可用但卡数是2 那就为这个主机创建两个进程,每个进程独立执行训练脚本)
# 我是单机多卡, 所以nnode=1, 就是一台主机, 一台主机上--nproc_per_node个进程
python -m torch.distributed.run --nnodes=1 --nproc_per_node=2 --node_rank=0 --master_port=6005 train.py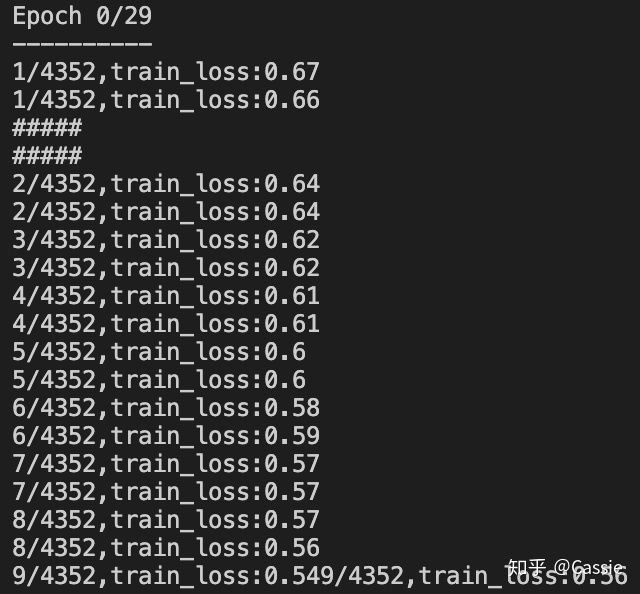
两块卡分别在两个进程跑起来啦
补充DDP的参数更新方式(ref:Gemfield:PyTorch的分布式)
- process group中的训练进程都起来后,rank为0的进程会将网络初始化参数broadcast到其它每个进程中,确保每个进程中的网络都是一样的初始化的值(默认行为,你也可以通过参数禁止);
- 每个进程各自读取各自的训练数据,DistributedSampler确保了进程两两之间读到的是不一样的数据;
- 前向和loss的计算如今都是在每个进程上(也就是每个cuda设备上)独立计算完成的;网络的输出不再需要gather到master进程上了,这和DP显著不一样;
- 反向阶段,梯度信息通过all-reduce的MPI原语,将每个进程中计算到的梯度reduce到每个进程;也就是backward调用结束后,每个进程中的param.grad都是一样的值;注意,为了提高all-reduce的效率,梯度信息被划分成了多个buckets;
- 更新模型参数阶段,因为刚开始模型的参数是一样的,而梯度又是all reduced的,这样更新完模型参数后,每个进程/设备上的权重参数也是一样的。因此,就无需DP那样每次迭代后需要同步一次网络参数,这个阶段的broadcast操作就不存在了!注意,Network中的Buffers (比如BatchNorm数据) 需要在每次迭代中从rank为0的进程broadcast到进程组的其它进程上。
踩坑记录
关于程序执行的命令行,我被困扰最久的一个点在args这个可变参数上,凭借着我对args贫瘠的认知, 不知道该把起始时我们定义的local_rank设置成多少。这里要记录一下,pytorch 为我们提供了 torch.distributed.run 启动器,用于在命令行分布式地执行 python 文件,所以我们只要给它留出这个位置来就可以,其他的这个启动器会帮我们搞定。也就是说在
torch.cuda.set_device(args.local_rank)
model = nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)这些代码段中(涉及到args.local_rank的地方)都是不需要改动的,我之前一直致力于改这些点,调试花费了很长时间。
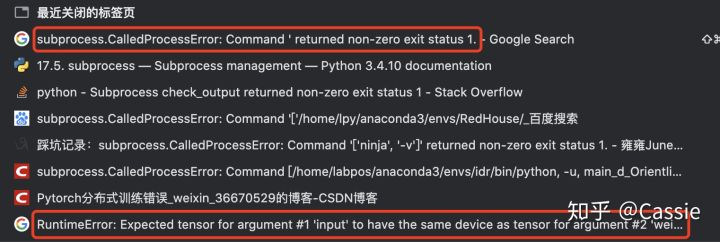
可能遇到的报错
还要注意:在DataParallel中,batch_size设置必须为单卡的n倍, 但是在DistributedDataParallel内,batch_size设置于单卡一样即可(不然就要OOM啦) .
写在后面
文章写到这里好像也并没有解决我最开始抛出的问题,但在解决问题但过程中蹭蹭蹭涨了好多知识,我怀疑问题出现的原因是我训练是在两块卡上,但是测试的时候是一块卡,这个我再试试。另外分布式训练还涉及了好多好多知识点,同学今天在研究apex,这是Nividia提供的分布式方法,好像要比DP和DDP还要快,不仅如此apex还能进行四种精度的训练(DDP只能双精度混合训练,float16和float32),在看文档的时候还涉及了hook(又是我的知识盲区)。
以及下面加载模型的函数,需要研究一下strict这个参数,有时候不加会报错
def load_model_checkpoints(model,checkpoint_path='./checkpoints/newSeUnet/latest.pth'):
# model = nn.DataParallel(model)
state_dict = torch.load(checkpoint_path)
model.load_state_dict(state_dict, strict=False)今天先讲到这啦~
本周的配图来自特别好看的江之岛~















 2284
2284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









