









分布式训练就是指在很多台机器上(每台机器有多个GPU)进行训练,之所以使用分布式训练的原因有两种:第一、模型在一块GPU上放不下;第二、使用多块GPU进行并行计算能够加速训练。但需要注意的是随着使用的GPU数量增加,各个设备之间的通讯会越复杂,导致训练速度下降。
分布式训练主要分为两种类型:数据并行(Data Parallel)和模型并行(Model Parallel)。
1.数据并行(Data Parallel)
当数据量非常大,并且模型架构能够放置在单个GPU上时候,就可以采用数据并行化的方式进行分工合作。
做法是依照一些规则将数据分配到不同的GPU上,并且每个GPU都有相同的模型架构,也就是在每个GPU上复制一份相同的模型,各自进行训练后,将计算结果合并,再进行参数更新。
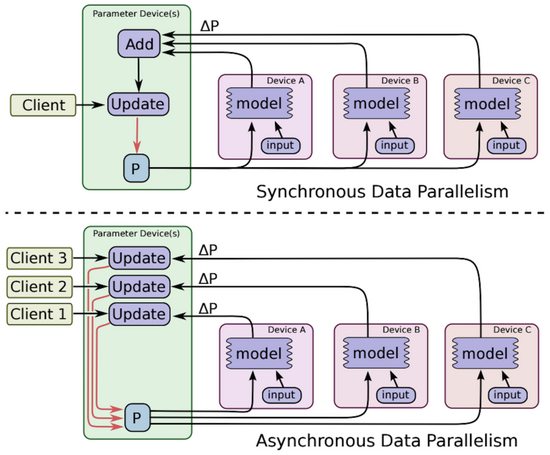
参数更新的方式又分为同步及异步:
- 同步(synchronous): 所有的GPU在训练时会等待其他GPU计算完毕后,才会进行一次参数更新,因此训练速度上会比使用异步的方式来得慢。但因为在更新参数时会合并其他计算结果,相当于增加batch size的大小,对于训练结果有一定的提升。
- 异步(asynchronous): 每个GPU各自进行训练和参数更新,不需等待其他GPU计算完毕。能够提升训练速度,但可能会产生Slow and Stale Gradients(梯度消失、梯度过期)问题,收敛过程较不稳定,训练结果会比使用同步的差。
2.模型并行化(Model Parallel)
当模型架构太大以至于在一个GPU上放不下时候,可以采用模型并行化的方式来将模型拆分到不同的GPU上。
由于模型层与层之间通常有依赖性,也就是指在进行前向传播、反向传播时候,前面及后面的层会作为彼此的输入和输出,在训练速度上会有一定的限制,因此若非使用较大的模型不建议采用模型并行化。若想提升训练速度,可以选择较为容易并行运算的Module,例如Inception。
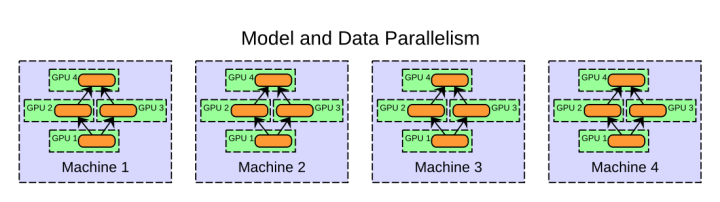
3.数据并行化+模型并行化
当然也可以采用结合数据并行化和模型并行化的方式,如下图所示,做法是将模型拆解并分配到单个机器中的不同GPU上,并且在其他机器中的每个GPU都复制一份相同的模型架构(拆解后的部分模型),而数据也会按照一些规则分配到不同的GPU上。
4.分布式训练系统架构
这些并行化运算的方式是如何进行加速的呢?各个设备又是如何将计算结果相互交换?分布式训练通过系统架构的设计来实现上述事情,目前的系统架构主要分成Parameter Server (PS)、Ring-All-Reduce。
4.1 参数服务器 (PS)
Parameter Server 架构分为sever group 和多个worker group 两大部分以及resource manager,其中resource manager 负责整体的资源分配。
sever group 用于初始化及维护所有的模型参数,由sever manager 和多个sever node (master node) 组成,其中sever manager 负责分配资源并维护各个sever node 的状态;sever node 则是负责维护被分配的一部分参数。
worker group 用于维护从training data 分配到的数据及对应的sever node 所分配到的部分参数,每个worker group 由task scheduler 和多个worker node 组成,其中task scheduler 负责分配各个worker node 的任务并进行监控;worker node 则是负责进行训练和更新各自分配到的参数。此外,worker node 只与对应的sever node 进行通讯,不论是worker group 和worker group、worker group 内部的每个worker node 之间都不会互相交流。
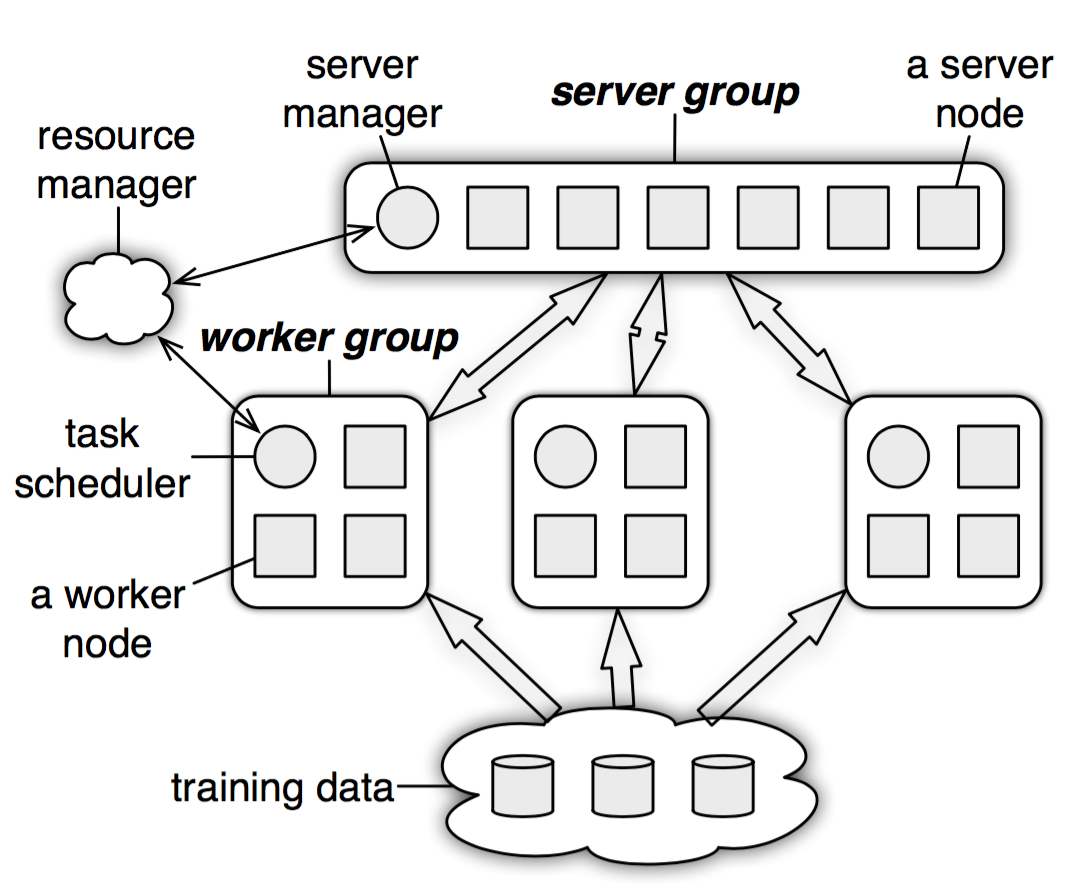
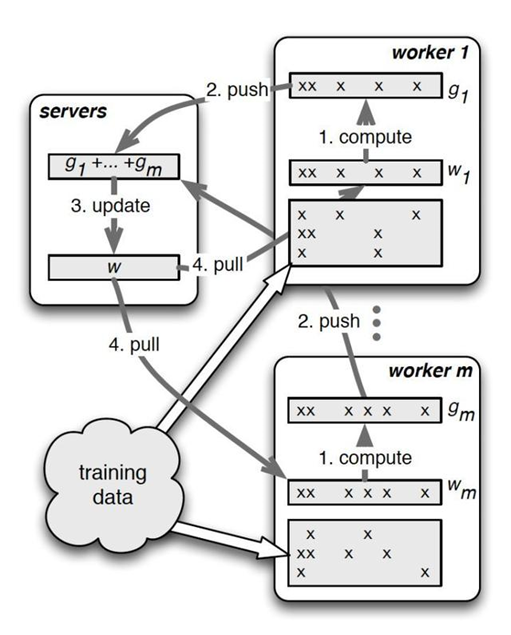
整体流程如下图所示,每个worker group 会各自进行训练、计算梯度、更新分配到的部分参数,再将结果传送给server node。接着server node 把收到的参数汇总并进行全局更新(ex: 平均参数),再传回给worker node。
由于server node 需要跟所有对应的worker node 进行沟通,容易导致sever node 的计算过重以及网路阻塞的状况,从而使得训练速度下降。
4.2 Ring-All-Reduce
Ring-All-Reduce 架构是将所有GPU (假设为N 个) 的通讯方式呈现环状的形式,并且每个GPU 中的数据会分为N 份,GPU 之间会根据环状的方式来传送数据。这样的架构所产生的通讯量与设备的多寡无关,因此能够大幅地减少通讯的开销、更好地平衡设备间通讯的使用程度。另外,在训练过程中,可以利用Backpropagation 的特性(后面层的梯度会先于前面层计算),在计算前面层梯度的同时,进行后面层梯度的传送,以提升训练效率。
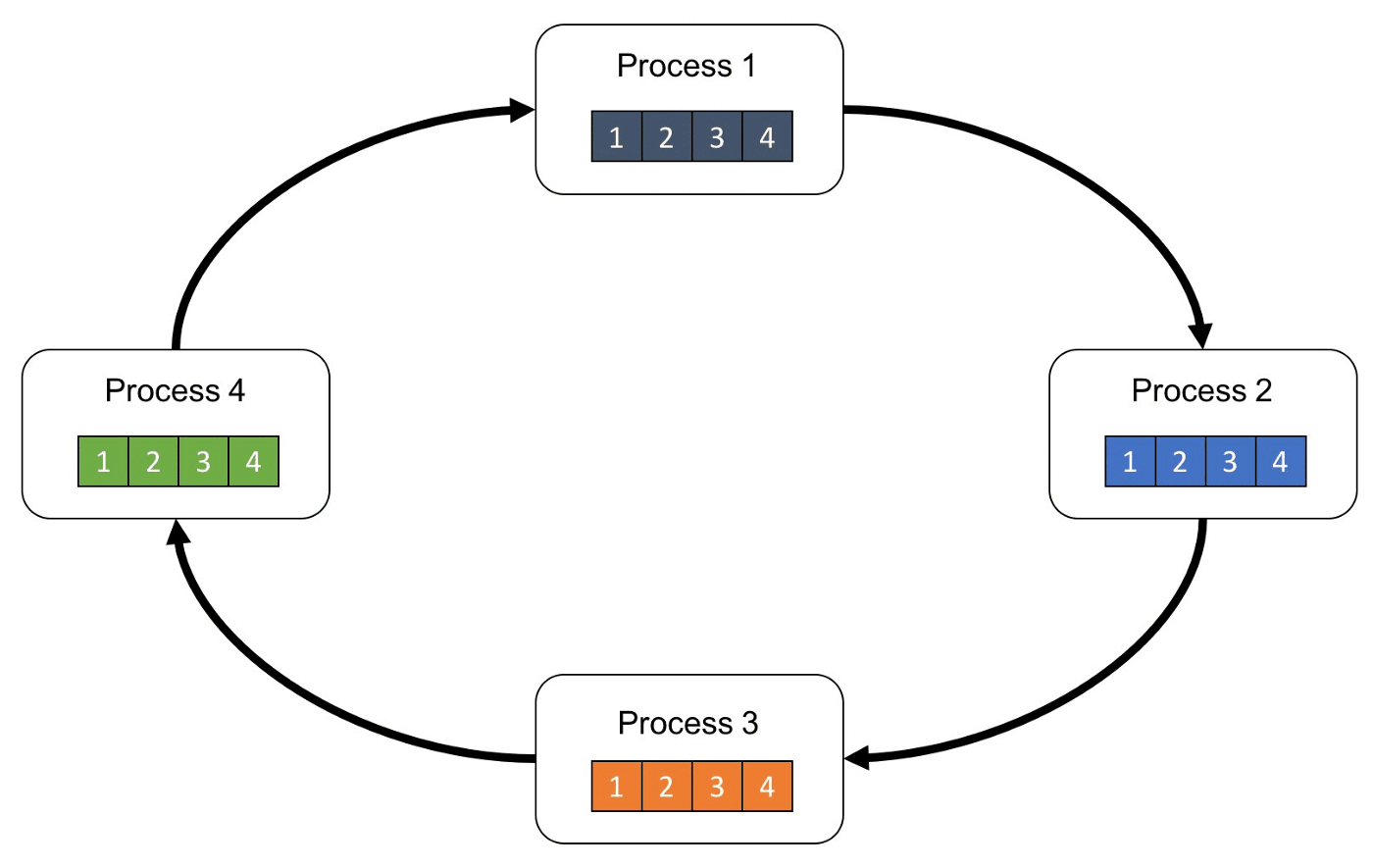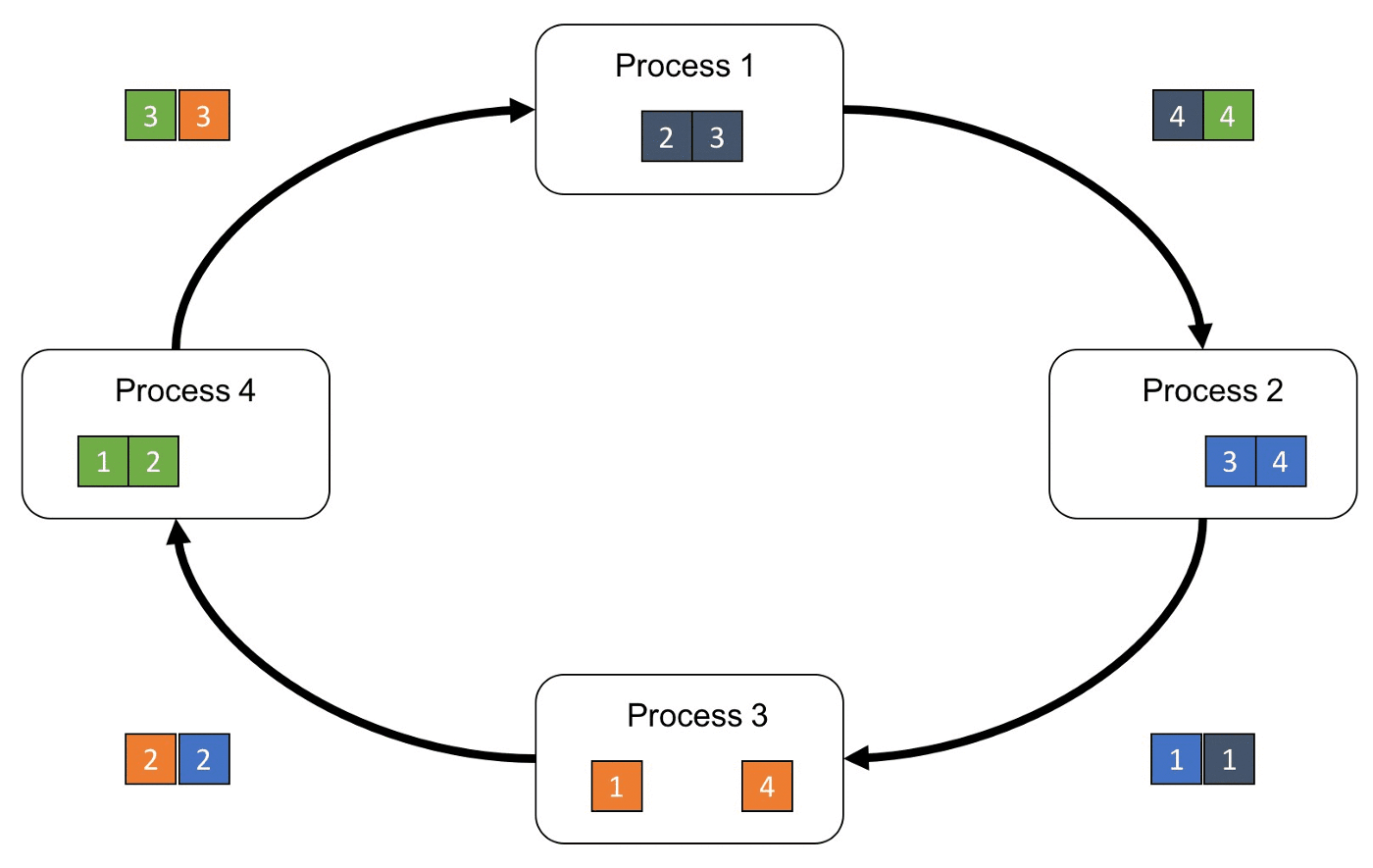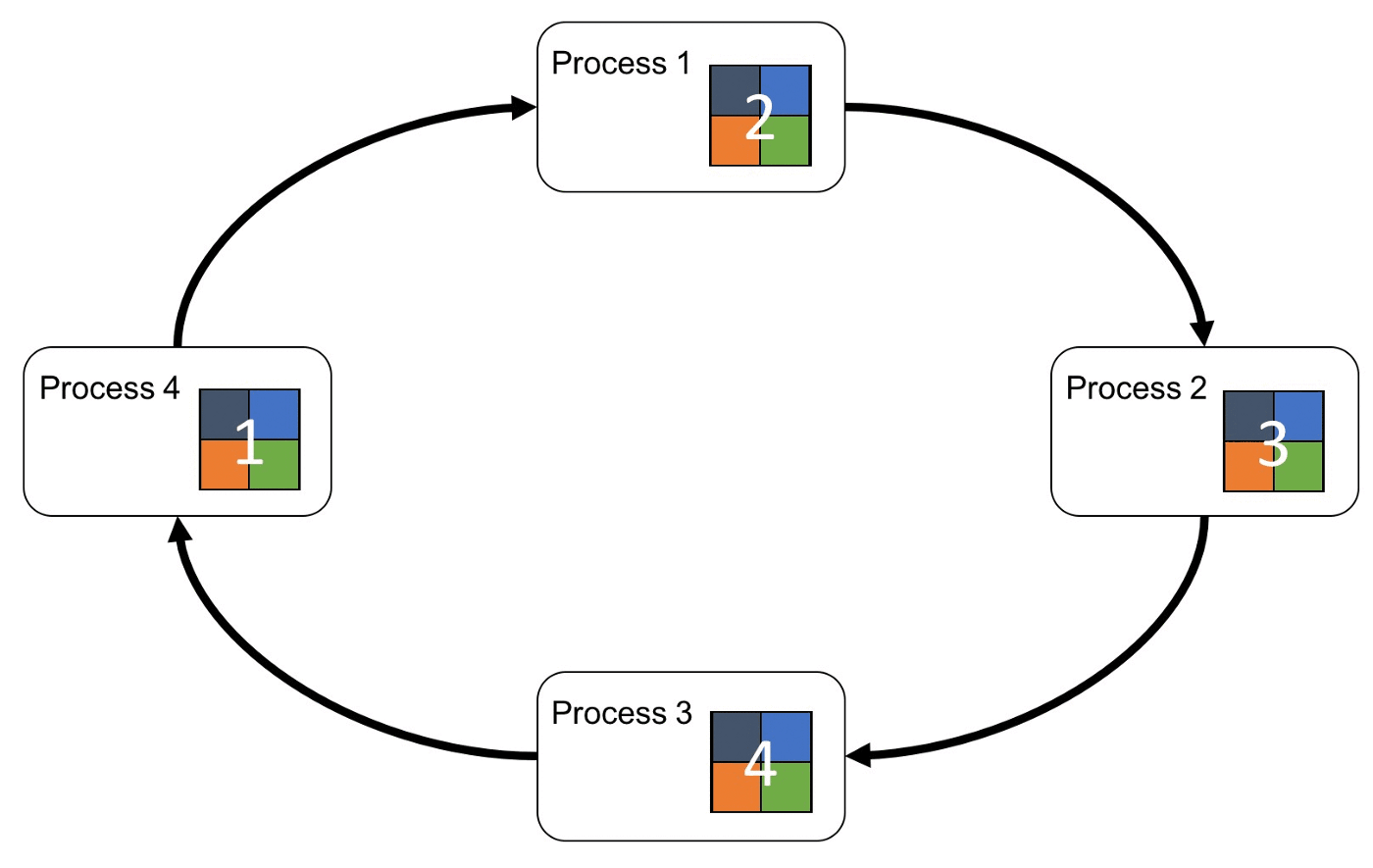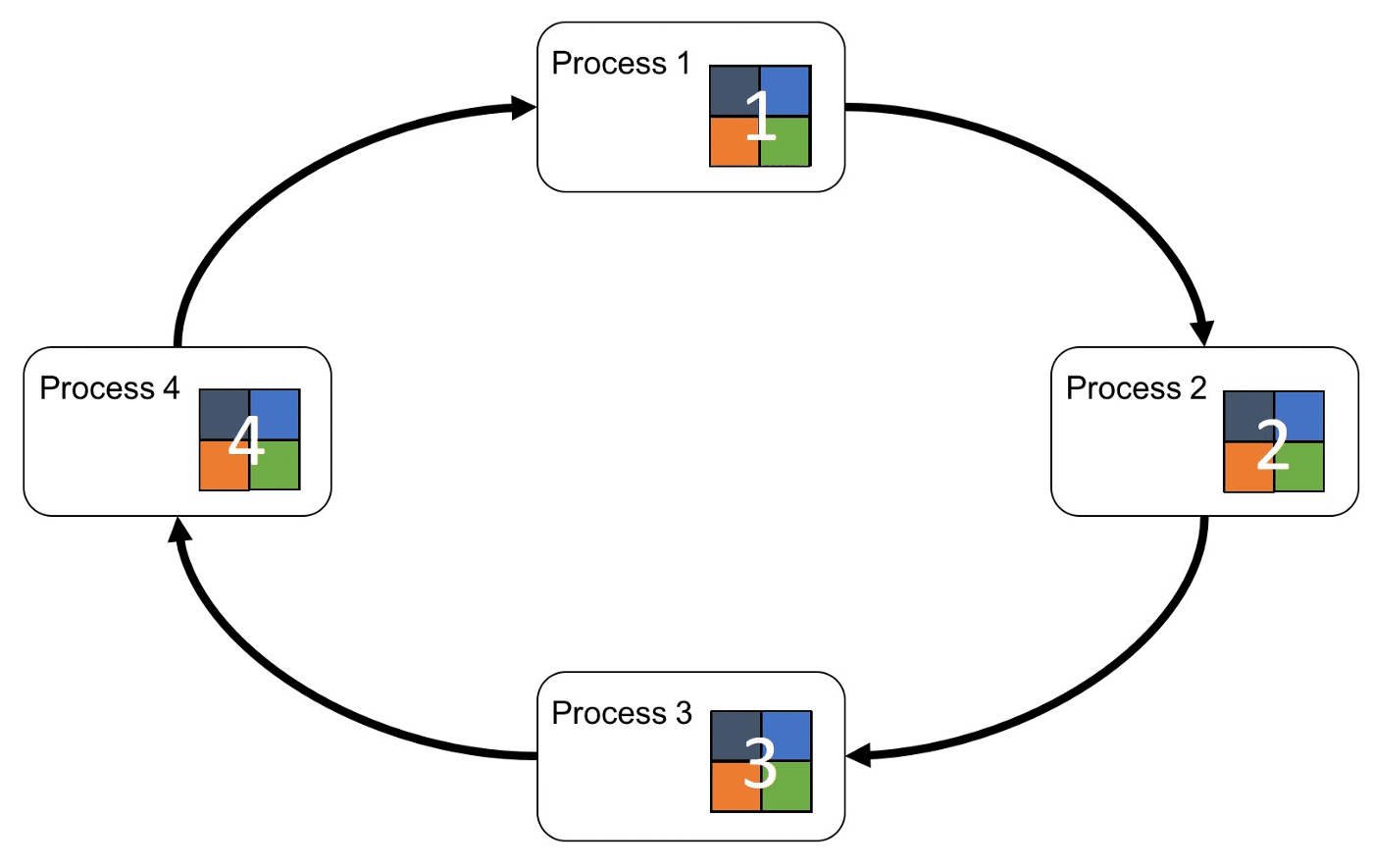
整体流程如下图所示,首先第k 个GPU 把第k 份的数据传给下一个GPU,接着下一个GPU 会将收到的第k 份数据与自己的第k 份数据进行加总整合后,再传送给下一个GPU。经过N 次的迭代循环后,第k 个GPU 会收到所有第k 份的最终整合数据,再以这份数据来更新各自的参数。
5. Pytorch分布式训练方法
Pytorch 提供了两种分散式训练方法— DataParallel (DP)、DistributedDataParallel (DDP)。
- DP 采用Parameter Server (PS) 架构,并且仅支援单台机器多GPU,任务中只会有一个进程
- DDP 则是采用Ring-All-Reduce 架构,可支援多台机器多GPU,能够使用多进程。
DP 的code 写法较为简单,但由于DDP 的执行速度更快,官方更推荐使用DDP。
















 713
713











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









