







目录
1 目的和思想
tf-idf 模型的目的:用一个矩阵表示某词对文章的重要性
tf-idf 的整体思想:利用词在文章出现的频数进行计算得出值表示重要性大小
2 模型原理
模型实现:
- 统计每篇文章词频,形成矩阵
- 通过公式 t f ∗ i d f tf*idf tf∗idf 计算每个位置的值,norm正则化每个值,输出矩阵
TF-IDF = T F ∗ I D F TF*IDF TF∗IDF
- TF: 词的频率(Term Frequency)
- IDF(Inverse Document Frequency): 逆文档频率,所有文章的总数除以含有该词的文章数,再取对数
- TF = 该词语在当前文档出现的次数
- IDF= log_e(文档总数 +1/ 出现该词语的文档总数+1)+1
3 tf-idf 总结
只用了简单的统计和计算便表示出了词在文章中的重要性权重
4 tf-idf 函数使用
TfidfVectorizer = CountVectorizer + TfidfTransformer
- CountVectorizer: 利用文本计算词频,生成词频矩阵
- TfidfTransformer: 将词频矩阵计算tf-idf值
- TfidfVectorizer: 利用文本生成词频矩阵,再计算tf-idf值
4.1 CountVectorizer
4.1.1 输入
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
4.1.2 函数及参数
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
# 将文本数据转换为计数的稀疏矩阵
X = vectorizer.fit_transform(corpus)
4.1.3 输出及应用
# 查看每个单词的位置
print(vectorizer.get_feature_names())
print(X.data)
# 由于 X 存储为稀疏矩阵,转换为 array方便查看
print(X.toarray())

4.2 TfidfTransformer
4.2.1 输入
稀疏矩阵 X 或 X.toarray() 都可作为输入
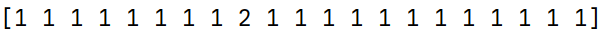

4.2.2 函数及参数
from sklearn.feature_extraction.text import TfidfTransformer
transformer = TfidfTransformer()
#将词频矩阵 X统计成TF-IDF值
tfidf = transformer.fit_transform(X)
4.2.3 输出及应用
print(tfidf.data)
#查看数据结构 tfidf[i][j]表示i类文本中的tf-idf权重
print(tfidf.toarray())
未加参数 norm=None的结果(norm作用为正则化)


4.3 TfidfVectorizer
4.3.1 输入
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
4.3.2 函数及参数
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_v = TfidfVectorizer(ngram_range=(1,2), # N-gram统计词可以按n来分词
max_features=3000) # 不同词的数量最大为3000
# 直接统计成 TF-IDF值
X = tfidf_v.fit_transform(corpus)
4.3.3 输出及应用
# 查看每个单词的位置
print(tfidf_v.get_feature_names())
# 未转换的数据
print(X.data)
#查看数据结构 tfidf[i][j]表示i类文本中的tf-idf权重
print(X.toarray())
















 2050
2050











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









