







特征提取函数库: sklearn.feature_extraction
所谓字典特征就是特征数据以键值对的形式存放在字典里
from sklearn.feature_extraction import DictVectorizer
def dict_demo():
#字典特征提取
data = [{'city':'南京','province':'江苏','temperature':31},{'city':'苏州','province':'江苏','temperature':32}
,{'city':'西安','province':'陕西','temperature':35}]
#字典特征提取
#1.实例化
transfer = DictVectorizer(sparse=False)
#2.调用fit_transform
trans_data = transfer.fit_transform(data)
print(trans_data)
print("特征名字:\n", transfer.get_feature_names())
if __name__=='__main__':
dict_demo()运行上面的程序我们可以看到:
 我们把这个处理数据的技巧叫做”one-hot“编码
我们把这个处理数据的技巧叫做”one-hot“编码
我们为每个类别设置布尔列。这些列中只有一列可以为每个样本取值为1。术语一个热编码
具体啥意思呢? 就是把所有不同的属性都看成一列,南京,苏州,西安,江苏,陕西,温度数值这些都是不同的属性,它们都是一列。
transfer = DictVectorizer()
#()内不写 默认为true 则不会显示成矩阵
不显示矩阵,会显示有数值的位置,以及布尔值和数值。
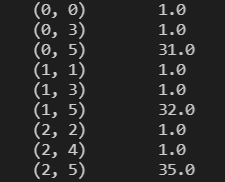
这样做的好处,节省内存,读取效率高。试想一个数千行*数千行的稀疏矩阵你看着不头大?















 1686
1686











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









