







Face Super-Resolution Reconstruction Based on Self-Attention Residual Network 2020
on Self-Attention Residual Network 2020)

题目:基于自注意残差网络的人脸超分辨率重建
1、引言
主要内容
针对基于卷积神经网络的人脸图像超分辨率重建方法存在的特征提取规模单一、特征利用率低、人脸图像纹理模糊等问题,提出了一种将卷积神经网络与自注意机制相结合的人脸图像超分辨率重建模型。首先利用级联的3×3卷积核提取图像的浅层特征,然后将自注意机制与深度残差网络中的残差块相结合,提取人脸的深层细节特征。最后,利用跳跃连接对提取的特征进行全局融合,为人脸重建提供更多高频细节。在Helen、CelebA人脸数据集和真实图像上的实验表明,该方法能充分利用人脸特征信息,峰值信噪比(PSNR)和结构相似度(SSIM)均高于对比方法,主观视觉效果较好。
本文贡献
DCSCN网络提出后,它通过级联多个3×3卷积核并使用跳跃连接来增强特征提取能力。然而DCSCN网络的特征提取能力有限,人脸重建效果较差。所以本文将自我注意机制引入到DCSCN中,并适当去除卷积层以增强网络的特征提取能力。这样网络就可以有目的地学习,更有利于人脸细节的准确重建,重建效果明显提高。
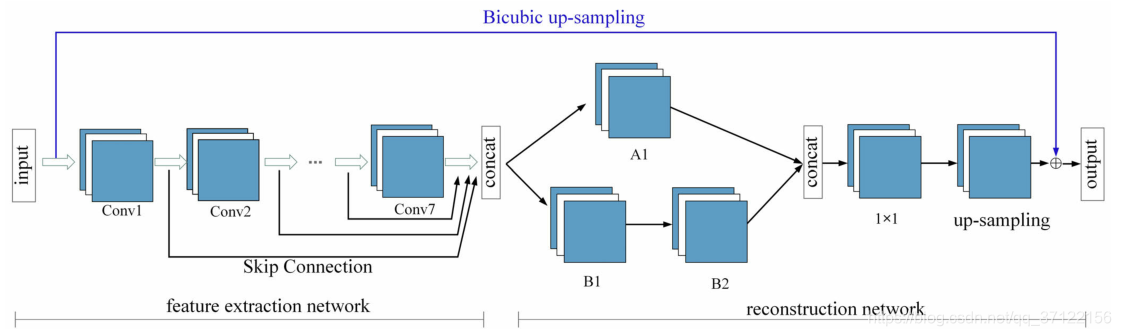
DCSCN网络结构
DCSCN是级联卷积的深层网络结构,由特征提取网络和重构网络组成。利用跳跃连接提高了特征图的利用率,有效缓解了网络的梯度消失现象,使网络训练变得更容易。此外,还利用并行卷积层(Network In Network)对图像细节进行重建,提高了网络的重建性能。
背景:基于卷积神经网络的人脸图像超分辨率重建方法存在的特征提取规模单一、特征利用率低、人脸图像纹理模糊;
方法:将卷积神经网络与自注意机制结合的模型,通过级联的3×3卷积核提取图像的浅层特征,然后将自注意机制与深度残差网络中的残差块相结合,以提取人脸的深层细节特征。最后,提取的特征通过跳过连接进行全局融合,从而为面部重建提供更多高频细节;
结论:能充分利用人脸特征信息,峰值信噪比(PSNR)和结构相似度(SSIM)均高于对比方法,主观视觉效果较好。
2、网络结构
DCSCN的重点是学习LR图像和原始HR图像的双三次插值之间的残差。由于网络的特征提取部分采用7层级联层次结构,参数庞大,不能对特征丰富、集中的人脸图像进行特征提取。因此,我们将卷积层与自我注意机制结合在一起以提取特征,并且为了减少网络冗余,对特征提取网络的后四层进行了删除,并对损失函数进行了有针对性的改进,最后提出了本文的网络称为SARCN。网络结构如图所示。

SARCN网络模型结构。将DCSCN的特征提取进一步细分为浅层特征提取和深层特征提取,后半部分是重建模块和上采样层。
本文改进的网络由三部分组成:浅层特征提取模块、深层特征提取模块和重构模块。
- 浅层特征提取模块由级联的3 × 3卷积核组成,用于提取浅层特征。以原始的LR图像作为输入可以减少计算量。
- 然后,为了获得更多的全局特征以进一步细化得到的特征图,在深度特征提取模块中设计了一种自我注意机制。它可以探索任意两个特征之间的全局相关性,有助于增强特征的表达能力,恢复图像的纹理细节。
- 最后,将特征图输入重建模块进行上采样(引入亚像素卷积层来实现上采样),并与LR图像的双三次插值结果相加,得到HR人脸图像。

自我注意残差网络。在每一行上执行Softmax操作。H×W×C表示高度为H、宽度为W的C特征。⊗表示矩阵乘法,⊕表示元素加法。

亚像素卷积图,包括卷积和重排两个步骤。亚像素卷积的实质是在传统的卷积层基础上增加一个相移层来改变图像的大小,在上采样过程中利用相移层来改变图像的大小。插值函数隐含在前面的卷积层中,可以自动学习。
3、损失函数
针对人脸图像的复杂特征和高频信息集中的特点,将损失函数转化为平均绝对误差(MAE)函数来估计重建的HR图像与地面真实HR图像之间的误差
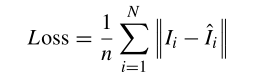
4、实验结果
本文使用海伦数据集、CelebA数据集、CMU+MIT人脸数据集和WHU-SCF(武汉大学监控摄像机人脸)数据对改进的模型进行了训练和评估。Test1是从Helen数据集中随机选择的35个测试图像;Test2和Test3是从CelebA数据集中随机选择的20和50个测试图像。

不同方法和建议模型在比例因子为3的Test1-man上的可视化结果比较。(a)双三次插值;(b)SRCNN;©FSRCNN;(d)ESPCN;(e)VDSR;(f)DCSCN;(g)我们的;(h)地面真实HR。

不同方法和建议模型在比例因子为4的Test3-woman的可视化结果比较。(A)双三次插值;(B)SRCNN;©FSRCNN;(D)ESPCN;(E)VDSR;(F)DCSCN;(G)我们的;(H)地面真实HR。

Test1, Test2 和 Test3的平均PSNR(db)/SSIM与不同SR方法的比较。

对CMU+MIT真实世界图像数据库中提取的6张LR人脸,用不同的方法和所提出的模型进行了视觉效果比较,比例因子为3。

在WHU-SCF数据集中提取的LR人脸上的实验结果表明,该方法的比例因子为2。














 120
120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









