







PARSING MAP GUIDED MULTI-SCALE ATTENTION NETWORK FOR FACE HALLUCINATION 2020 ICASSP
题目:面向人脸幻觉的解析图引导多尺度注意网络

1、引言
人脸幻觉是一个特定领域的图像超分辨率问题,其目的是将低分辨率的人脸图像转换成高分辨率的人脸图像。现有方法的性能通常不能令人满意,特别是当提升因子较大时,如8×。本文提出了一种基于具有多尺度通道和空间注意机制的深度神经网络的两步人脸幻觉方法。具体地说,我们开发了一个ParsingNet来提取输入LR人脸的先验知识,然后将其输入到精心设计的FishSRNet中来恢复目标HR人脸。实验结果表明,我们的方法在量化指标和视觉质量方面都优于最先进的方法。
虽然现存的人脸图像的超分辨率方法已经取得了令人印象深刻的效果,但仍然需要认真考虑以下问题:i)从中间结果得到的先验知识直接受到中间结果质量的影响,而中间结果的质量通常是有限的,导致学习到的先验知识很差,甚至是错误的。ii)在一般的图像超分辨率方法中,已经证明通道和空间注意信息对于提高图像重建的性能是有用的。然而,作为一种特定的图像超分辨率方法,现有的人脸幻觉方法大多忽略了注意机制。iii)目前的深部人脸图像超分辨率网络多为预上采样或后上采样。然而,低分辨率的特征不适合于像素级任务,直接使用高分辨率浅层特征进行像素级任务效果不佳。
针对上述不足,本文提出了一种面向人脸幻觉的解析图引导的多尺度注意网络。该方法的主要贡献如下:
- 提出了一种由ParsingNet和FishSRNet组成的两步深度人脸幻觉。
- FishSRNet是由渔网改进而成的鱼形网络,能够生成各种分辨率的要素,并利用不同层次的信息。
- 提出了一种新的MSAB算法,该算法能够提取多尺度信息,并利用特征的通道相关性和空间相关性。
背景:现有的人脸幻觉方法大多忽略了注意机制,并且性能通常不能令人满意,特别是当提升因子较大时;
方法:提出了一种基于具有多尺度通道和空间注意机制的深度神经网络的两步人脸幻觉方法;
结论:实验结果表明,我们的方法在量化指标和视觉质量方面都优于最先进的方法。
2、网络结构
如图1所示,提出的方法由两个子网络组成,i)ParsingNet从LR人脸学习解析映射,ii)FishSRNet利用LR人脸和相应的解析映射恢复HR人脸。
我们选择一个面部解析图作为我们的方法中的side information,并设计名为Parsingnet的子网,以了解来自输入LR面的面部解析映射。特别地,我们将人脸图像分为六个部分:眼睛、眉毛、鼻子、嘴巴、皮肤和其他。我们的ParsingNet是一个由顺序Resblock组成的常见卷积神经网络。
受FishNet的启发,我们提出了一种改进的版本,称为FishSRNet。如图2所示,FishSRNet是一个鱼形网络,由特征提取层、鱼头、鱼体、鱼尾和重构层组成。为了从LR人脸图像中恢复出HR人脸图像,我们的FishSRNet首先对输入进行上采样,然后再对输入进行下采样和上采样。在FishSRNet中相邻的上采样模块(convolution and pixelshuffle,UM)或下采样模块(inv-pixelshuffle and convolution和卷积,DM)之间,有两个级联的MSAB。

图1 提出方法的总体框架

图2 FishSRNet体系结构
将输入的人脸ILR和解析图p连接起来作为FishSRNet的输入
然后鱼头部分对特征图进行三次采样,以增加特征的接受范围和分辨率
在此基础上,对鱼体特征图进行下采样,提高分辨率的多样性。同时,鱼体利用鱼头保留的特征生成新的特征
然后我们将F10和p连接为新的F10。使用F5、F7、F9和F10鱼尾向上采样,特征映射到与HR相同的分辨率
最后,通过重建层生成最终输出的HR人脸图像ISR
我们在两个地方连接p,每个连接都有它自己的意义。p和ILR的连接(作为FishSRNet的输入)的目的是更加关注面部成分,并在p的引导下生成更清晰的HR人脸。在鱼尾之前的F10和p的连接是为了进一步增强p的作用。
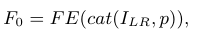
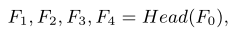
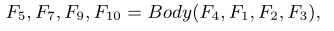
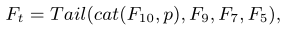
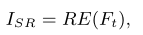

图3 MSAB。包括三个主要模块:Convolution-ReLU,多尺度卷积,注意块(通道注意机制和空间注意机制)
通道和空间注意机制分别用于通过通道和空间相乘来重新缩放特征。然后,MSAB沿着通道维度连接两个重新缩放的特征以生成Fcs。最后,MSAB将Fin和Fcs相加,产生MSAB的输出。
3、实验结果
与最新方法的比较


不同人脸超分方法的定性和定量比较。从左到右:输入LR图像、双三次、SRCNN、VDSR、URDGN、[16]、FSRNet、我们的方法和GT。
消融实验

Model-1:去除鱼头和鱼体中的um和dm,然后将该网络变成一个通用的上采样后网络。
Model-2:使用Resblock的FishSRNet作为基线。
Model-3:配备MSAB而不是Resblock。
Model-4:将ParsingNet添加到Model-3。
Model-4的人脸比其他的人脸更清晰、更逼真。因此,我们的ParsingNet有助于提高视觉质量。要在量化指标和视觉质量之间进行权衡,Model-4是最好的模型。















 1535
1535











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









