









Joint Bilateral Learning for Real-time Universal Photorealistic Style Transfer
基于联合双边学习的通用写实风格转换
from Boston University &PixeShift.ai&Google Research
Paper
Abstract
照片写实风格的风格迁移是将具有任意艺术风格的内容图像,生成接近照片这种写实风格的图像。近年来基于深度学习的多种方法在此方面取得进展,但其速度无法满足实际应用中的实施需求,或者存在一些变形扭曲等伪影。本文提出一种新的端到端的风格迁移模型,既满足实时性要求又可以生成写实的迁移图像。本文网络的核心是在前馈神经网络中学习边缘敏感的仿射变换,可以自动遵循写实风格的迁移。并且本文这种方法在多种数据集任意风格的图像上进行了训练,可以鲁邦的岁不同数据集、具有任意风格的图像进行迁移。与目前SOTA的方法对比,本文进行迁移时速度提升了3个数量级,可以达到在移动端的4K实时推断。
Section I Introduction
在计算机视觉领域图像风格迁移备受关注,在风格迁移领域的一个核心问题就是如何将任意风格的图像生成接近真实的图像。Gatys等人的工作奠定了风格迁移类任务的工作基础,将其定义为内容损失函数和风格损失函数的优化问题;Luan等人通过增加真实性约束(photorealism constraint) 使得输入和输出局部对其从而抑制变形的产生,但是由于该方法问题需要对每个图像在深层次网络中都进行优化,因此限制了网络性能的发挥;近期Yoo等人提出了一种基于小波变换的校正方法可以稳定风格化过程但是速度方面不尽人意无法用于实际应用。 另一条研究思路是预训练一个深度前馈网络,这样在测试时只需要经过网络一次就可获得风格化图像。虽然这种“通用”的方式看似比前面基于优化的方法更快,但是对于没见过的图像其泛化能力差强人意,而且在移动端运行依旧很慢。
因此,本文提出了一种快速的端到端的进行写实风格图像迁移的方法,这种模型一旦在合适的数据集上完成了训练就可以在手机端完成全像素(4K)的实时风格迁移。
本文关键的一点在于通过Luan的photorealism constraint可以确保写实效果的迁移,输入与输出的相关边界其局部区域和颜色必须匹配。因此本文设计了一个在双向空间(bilateral space)中的算法,可以紧凑的表示各种局部仿射变换。
本文的工作总结如下:
(1)提出了一种学习局部仿射变换的写实风格迁移网络,对于未见过的或对抗性的输入,效果依然鲁棒性很强;
(2)在4K手机端进行了实时推断;
(3)使用双边空间的拉普拉斯正则化有效消除了空间网络伪影。
Part A Related Work
早期的研究主要基于图像的统计信息或者根据滤波相应直方图进行风格迁移,因为只是基于低层次的统计信息所以无法捕获语义信息。但是要强调的一点是这些方法确实产生了写实性的图像,虽然他们并不总是忠实于风格或者姿态那么良好。
而Gatys通过深度神经网络有效根据每一层激活的统计信息补货到了风格特征,但是由于其泛化性能的限制使得其输出对象经常不那么写实,存在变形情况。为了移除这些变形,He等人利用图像中语义相关密集区域获得更加准确的颜色迁移效果。也有一系列工作通过对损失函数施加额外的约束来改善变形问题,比如Luan等人通过对色彩空间的局部对齐获得更加写实的效果。
PhotoWCT则将相似的约束作为后处理的一步,而LST则是在风格迁移主网络外增加了一个额外的空间传播网络来保留空间依赖关系;Puy等人也采取类似的思路,提出了一个灵活的网络进行风格迁移,并在每次学习更新后对图像的内容进行后处理。与这种添加额外结构的方法相比,前面增加写实性约束更像是软惩罚。本文的模型则是直接预测局部仿射变换,确保满足这一约束条件。

在风格迁移方面还有一种研究思路,就是借助自编码器学图像的数据分布从而进行风格迁移。相关研究显示通过unpooling或者小波变换残差可以有效减少变形。
本文的工作将这两种思路结合,基于HDRNet建立基础网络,因为输入大规模的输出-输出对吼HDRNet可以快速学习算子的局部放射变换;由于网络规模很小,需要学习的变换又被施加了约束,因此不会引入像噪声或者错误的一些边等这些变形。因此这些特性是我们确实想要的,但是当我们把HDRNet用于不同的数据集上时,我们发现产生了许多伪影(参见Fig2)。这主要是因为HDRNet没办法显式模拟风格迁移,只是通过记住它所看到的东西来学习将函数投射到局部仿射变换上。
因此HDRNet需要大量的训练数据但是泛化性能却很差。
既然HDRNet是从低层次图像特征来学习局部仿射变换,那我们的策略就是从统计特征匹配开始,使用自适应归一化AdaIN来构建联合分布,这样可以显式的将风格迁移建模为一个分部的匹配过程,从而可以推广到其他没见过的或者对抗性的输入上。

Section II Method
本文的方法是基于单一的前馈神经网络,输入两张图片分别作为content photoIc和任意风格图像style imageIs,生成兼具前者内容和后者风格的迁移图像。并且这种方法是可泛化的,因为在不同数据集上训练过后对于新的没见过的组合也可以进行迁移。本方法的核心围绕着如何学习局部仿射变换。
Part A Background
首先回顾一下关于风格迁移的背景知识。
Content and Style.
在Neural Style Transfer中将风格迁移问题定义为优化输出图像中的内容误差和风格误差问题,而图像的内容和风格信息都是基于VGG-19提取的,比如对于中间层的特征图Fi其风格特征由Gram矩阵表示Gi。
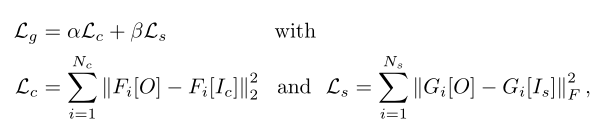
Statistical Feature Matching
后面的研究有的不再直接优化上面提到的损失函数,而是通过统计特征匹配的方式,比如通过自编码器的bottleneck部分获取特征的统计信息,比如有通过SVD进行颜色变换,以及AdaIN提出了一种简单的归一化方案,使用每个通道的均值和方差进行归一化:
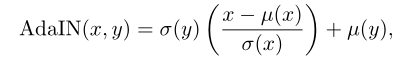
其中x和y分别代表内容和风格的不同特征。鉴于AdaIN的简洁、成本低廉本文也在网络结构中加入了AdaIN来减少风格损失:
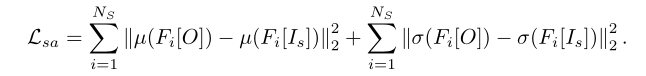
Bilateral Space:
双边空间的概念首次由Paris & Durandti在进行图像快速边界滤波时提出。主要将2D灰度图映射到双边空间中(比如一系列稀疏的3D点集),滤波后再映射回pixel space。因此分为splat->blur->slice三步,虽然看到双边空间中使用的是三维信息,但数据量(也就是计算的数据点)却大幅减少,因此可以加速滤波过程。
而Bilateral Guided Upsampling将bilateral grid扩展到了图详见的转换,通过存储每个单元的仿射变换,放射双边变换的编码能力有足够的分辨率进行图图之间的变换,主要就是计算每个像素的仿射矩阵乘以每一点的像素信息。而放射双边网格可以限制输出变化平稳、对边缘敏感以及具有局部仿射变换的能力,从而不会引入噪声、假边等问题,因此更符合写实风格的约束。
Part B Network Architecture
本文这一端到端的差分网络包含两路,一路系数预测(coefficient prediction)流负责根据输入图像的内容及风格学习二者浅层特征的联合分布,预测这一双边仿射变换网格(affine bilateral grid);另一路是渲染流(rendering)负责将输入图像的每一点像素值根据一个查找表计算出其luma值,用于分割和切片。
整个网络通过将系数预测和渲染分开可以很好的权衡最终图像的风格化效果以及网络的性能。


Fig 3展示了网络的整体结构,其中绿色部分是低分辨率系数预测主要学习输入图像其内容/风格图像对之间的联合分布,随后得到的分布会馈送到双边学习模块L和G中进行affine lateral grid的预测;
红色部分是渲染流,是基于整个图像分辨率进行的,主要负责从3x4矩阵中采样计算渲染值然后与每一像素点相乘。
Style-based Splatting
首先本文的目标是如何学习内容特征和风格特征之间多层次的联合分布。这方面本文没有直接使用步进卷积,而是使用一个预训练过的VGG19网络来提取图像不同尺度的特征(分别是conv1_1,conv2_1,conv3_1和conv4_1);随后受StyleGAN的启发将提取到的中间特征汇编成splatting block序列,从最精细的尺度开始每一个splatting block都使用步长为2的共享权重卷积层,这样使得空间分辨率减半,channel数翻倍;随后跟着AdaIN学习内容/风格的联合分布。因为内容的特征图谱被缩放,因此本文将其添加到相同分辨率的VGG-19中的层,进行AdaIN对齐。这样内容的特征图谱中就包含更过通道,本文还用步长为1的卷积层选择相关的通道。
本文一共使用了3个splatting block,对应VGG-19中提取的最精细的特征层;虽然可以使用额外的splatting block但是他们过于粗粒度,和使用步长为2的卷积操作没什么区别。
由于这一结构有效的学习了相变的双边空间的内容特征,因此可以认为它是一种基于风格学习的拆分(style_based splatting).
Table I展示了网络的整体结构,S系列代表第j个splatting block中的第i层,以及在每一次提取局部特征、全局特征、特征融合时都使用了AdaIN。以及全局特征和局部特征在融合前都在各自通道上级联了。
Part C Joint Bilateral Learning
为了在双边空间中对齐内容/风格特征,因此本文力求找到一种局部变换的编码方式可以有效捕获风格信息且是带有语义含义的。因此本文参照HDRNet将网络超分成两个不对称的路径,一条全卷积的局部路径(local path)负责学习局部的颜色变换,同时决定着最终网格的分辨率 ;一条全局路径包含卷积层和全连接层,主要用来总结语义信息以及帮助进行变换的空间归一化。这样就使得仿射变换的学习既包含语义和局部信息感受野还不会太大。
以及在学习全局场景类别的时候采用的是小型网络,仅包含2层卷积来降低分辨率。
本文在局部路径输出每一像素点糊附加一个summary,并最终使用1x1卷积降低到96个通道;这96个通道可以分为7个luma bin,用来分离边缘,每个通道存储了一个3x4的仿射变换。
Part D Losses
因为本文的网络结构完全可微,因此可以直接定义损失函数。损失函数中增加了[8]中负责内容和风格保真的部分以及双边空间拉普拉斯正则化的部分,因此损失函数表述为:
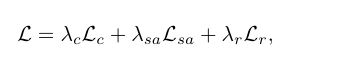
其中Lc内容损失和Lsa风格损失前文提到过,分别是:
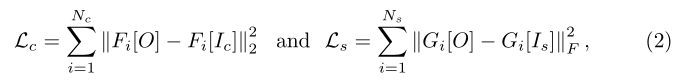
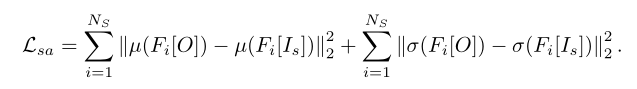
而Lr:
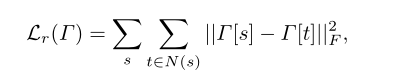
系数分别设置为0.5,1,0.15
Part E Training
训练部分细节:
框架Tensorflow
Adam Optimizer
training resolution:256x256
在一块16GB V100上训练时间为2天
一旦训练好了就可以在任意分辨率图像上进行测试。
Section III Results
为了验证本文方法的有效性,从网络上搜集了400张高质量图像做测试,与其他SOTA算法进行了风格迁移效果的对比,还进行了网络结构的消融实验。
Part A 消融实验
基于风格的Splatting设计
与去掉splatting block S的结构进行对比:AdaIN和WCT,网络其他部分不变。
Fig 4(b)©显示虽然图像的内容被保留了下来但是整体颜色映射的一致性不佳,这种低分辨率的特征不足以具有足够的信息密度对全局颜色进行修正。
而Fig4(f-j)分别可视化了不同splatting block的效果,可以看到比较精细的block主要学习纹理和局部对比度信息,而越往后的额block则负责捕获全局风格,比如整体的主色调等,因此通过将不同分辨率的splatting block借个起来可以有效的学习多级特征变换成联合分布。

网络结构的消融实验
Fig5展示不同网络结构变体的效果,主要由3种变体:
不使用双边拉普拉斯正则化;
不使用全局场景summary(Fig 3中黄色框);
不使用top path输入(Fig 3上方深绿色)。

Fig 5展示了没有Lr后图像出现了一些深色区域,主要就是针对未见过的图像数据bilateral grid处理成了0;而通过slice可使得黑色区域通过适当的变换进行过渡。
(c)的效果显示出没有summary迁移生成的图像缺少全局一致性,比如天空部分的色调就不一致。
(d)的效果显示出top path也很重要,如果网络局部过拟合对于一些特征明显的patch会展现出不正确的颜色特征,而通过学习和预训练提取不同尺度的特征就可以消除这种不一致。
(e)显示出风格化不仅仅是简单的对边缘敏感的插值更需要学习的是局部仿射变换。与Fig 4(d)AdaIN效果相比本文的视觉效果更好。

Grid Spatial Resolution
Fig 6展示了网格的分辨率时如何影响风格化效果的,1x1还是一条单一的全局曲线,对色彩的映射还不到位,直到2x2网络试图在空间上的映射发生了转换,不同的区域开始展现不同的颜色,但节骨仍然差强人意;而8x8时候风格化效果就具有足够的空间分辨率了。
Fig6下方则是luma 分辨率对风格效果的影响。
Part B 定性分析

视觉效果
Fig 10展示了与不同算法的视觉效果对比,可以看到photoWCT依赖于unpooling以及后处理,因此图像迁移效果包含很多伪影;LST主要关注任意风格转换,增加了一个额外的空间传播网络做后处理来减少失真,但还是能看到有的图片中存在明显的扭曲。WCT2当内容和分割语义相似时表现比较好,当二者差异较大时就会显得很朦胧;而本文的算法在很多具有挑战性的图像中表现的也很好,因为对输出空间进行了限制,总是能产生尖锐的边缘,而对于训练集之外的图像(如树叶、人脸)强度又会明显退化。
鲁棒性:
得益于其变换模型的限制,本文在遇到对抗性输入时比基线模型具有更棒的鲁棒性。尽管本文的模型主要基于景观图像训练但是当遇到从未遇到过的图像甚至单色的风格也可以进行优雅的“退化”。
参见Fig 7

Part C定性分析
运行时间和分辨率
Fig 8展示了在常用摄像头分辨率的风格迁移效果,可以看到基本没插,主要是由于网络较深层次都是基于256x256分辨率训练的,而全分辨率在网络中仅占很小一部分;Fig 8(b)进一步展示了运行时间<5ms.
用户调查
为了更加实际的评估本文算法,本文招募了20名与论文无关的用户对本文的风格化、写实性效果进行评估,比如:
图像明显的失真有多显著?
输出图像的风格与参考图有多相近?
对生成图像如何评分?
最终评估结果参见Fig8©。

视频风格化
虽然本文的算法专注于图像,但是也可以泛化到视频内容上,Fig9展示了如何将单一图像的风格迁移到一整个视频序列上,可以看在未使用额外正则化或数据增强的情况下其风格还是连续的。

Section IV Conclusion
本文提出了一种通用的用于写实风格迁移的前馈神经网络,本算法的关键之处在于通过深度学习预测放射双边变换网格,从而为图像在变换过程中添加约束。
实验结果显示本文这种方法明显比当前其它算法更快,可以实时运行在手机端进行风格迁移。
未来本文将进一步在减少网络规模上进行优化,以及研究如何如何生成写实风格和抽象艺术风格之间的连续变换。















 627
627











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









