







DARTS:Differentiable Architecture Search
DARTS:可微分神经架构搜索
from ICLR2019
Abstract
与常规使用进化算法或者不可微的方式进行搜索不同,本文通过将搜索空间弛豫为一个连续的空间结构,以可微的形式进行神经网络架构搜索,通过梯度下降可以提升搜索的效率。本文的方法在CIFAR-10,ImageNet,PTB以及WikiText-2数据集上进行了测试,在图像分类以及RNN进行语言建模任务中均取得了优异性能,并且比传统的不可微的方法在速度上提升了一个数量级。
目前本文的研究进展已开源,供进一步探索高效的神经架构搜索算法。
Paper
Code
Section I Introduction
设计具有SOTA性能的神经网络结构需要研究人员投入大量的时间和经历,近期越来越多的研究热情聚焦于自动进行神经网络结构设计,并且有的算法在图像分类和目标检测等任务取得了优异的性能。
但是虽然搜索出的结构具有优异的性能但却需要付出巨大的计算成本。比如在Zoph等人基于强化学习的搜索算法中需要2000 GPU/Days;因此也有研究聚焦于搜索算法的加速,比如搜索空间为特定的结构、使用权重共享、继承多个体系的结构等,但是搜索算法的可扩展性这一挑战依旧存在。
基于RL,进化算法、贝叶斯优化等搜索策略的搜索算法效率低下的原因在于,将网络架构的搜索视作一个离散空间优化的黑盒过程,需要对大量网络的性能进行验证。
本文从另一角度看待这一问题,提出基于梯度的可微的搜索算法(DARTS,Differentiable Architecture Search)。本文不再基于离散的搜索空间而是将搜索空间放宽为连续的,从而可以通过梯度下降对验证集的性能进行优化。与效率低下的黑盒搜索相比,基于梯度优化的搜索方式在达到同样SOTA性能的前提下搜索效率有数量级上的优化。此外还有值得注意的一点是,与其他一些搜索算法相比更加简洁,因为无需额外的控制器、超网络、性能预测器等的参与,并且在CNN和RNN上均有同样的泛化性。
在连续空间进行搜索的想法并不新鲜,但是用于神经架构搜索仍有一些独特之处。之前的工作主要优化网络结构的特定方面,比如filter或者网络的分支结构;而DARTS能够在丰富的搜索空间中学习高性的具有复杂图结构的网络模块;并且不局限于特定的网络架构,CNN和RNN均可。
本文第三节的实验显示出DARTS搜索出的卷积单元可以达到CIFAR-10数据集上做分类误差为2.76%,同时网络参量在3.3M,与目前达到的SOTA接近但是计算量降低了3个量级。迁移到ImageNet数据集分类误差为26.7%。
在语言建模任务中,DARTS搜索的recurrent cellzai PTB数据集上为55.7 test perplexity,超过了LSTM以及目前其他基于NAS的算法。
本文的研究内容主要有:
(1)提出了一种基于双层优化的可微的神经架构搜索算法,适用于卷积和递归神经网络。
(2)本文这种基于梯度优化的搜索算法在图像分类达到优异的性能,在语言建模方面更是取得了最优的性能。
(3)与基于不可微的搜索技术相比,本文可微的搜索算法显著提升了搜索效率。
(4)本文实验还显示DARTS基于CIFAR-10和PTB数据集上学习到的架构可进一步迁移到ImaheNet和WikiText-2数据集上。
Section II Differential Architecture Search
Part A介绍搜索空间,其中将网络结构描述为有向无环图;Part B介绍如何使得搜索空间连续可微;Part C介绍如何进行近似计算。
Part A Search Space
本文与Zoph等人思路一样,都是通过搜索网络结构单元搭建最终网络结构,搜索到的结构单元可以通过堆叠搭建CNN也可以通过递归搭建RNN。
每一个cell都是一个包含N节点有序组合的有向无环图。每一个结点(node)都代表一种隐式表征(如CNN中的一个featre map),每一条边(edge)则是某种操作对节点x进行变换。本文假定每个cell包含2个输入节点1个输出节点。
 (a)中每条边的操作是未知的;(b)在每条边上设置混合候选操作来放宽搜索空间;(c)通过bilevel optimization对混合概率和网络权重进行联合优化;(d)从学习到的混合概率中得到最终的网络结构。
(a)中每条边的操作是未知的;(b)在每条边上设置混合候选操作来放宽搜索空间;(c)通过bilevel optimization对混合概率和网络权重进行联合优化;(d)从学习到的混合概率中得到最终的网络结构。
对于卷积单元,输入节点则是前面两层的输出节点;对于循环单元,输入节点则是前两个时间步的输出。单元的输出则是通过如concatenate连接到所有中间结点。
因此每一个中间结点都是基于它所有前任计算的:
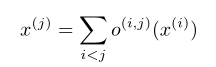
同时zero代表两个节点之间没有连接。这样将cell结构的学习简化为学习edge的操作。
Part B Continuous Relaxation Scheme
O表示候选操作的集合(比如卷积、最大池化、zero等),为了让搜索空间连续化,将对操作进行特定选择变为使用softmax。
成对节点(i,j)操作的混合权重通过向量α参数化,这样结构搜索就化简为一系列连续变量的学习。

最终的离散的网络结构可通过将混合操作替换为最大可能性的操作即可。搜索空间连续化后本文的目标就是联合学习网络体系结构α和权重w。
与基于强化学习、进化算法进行NAS不同,DARTS使用梯度下降来优化验证损失。
本文就是找到最优的α使得Lval最小,找到合适的w使得Ltrain最小。因此这是一个双层优化问题(Bilevel Optimization),上层优化变量为α底层优化变量为w。也可以将α看做是一种特殊类型的超参数,其纬度更高、更难优化。
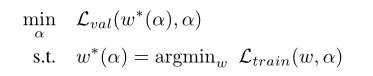
Part C Approximation Architecture Gradient
如何精确的评估架构梯度令人望而生畏,本文使用一种简单的近似算法:
其中为当前网络架构下的权重,ε为学习率,通过一次训练的结果来逼近w*,而不是直到训练收敛后再进行优化。

参考Alg 1列出的DARTS的流程,近似指的是循环优化α和w直至收敛。固定w更新α,固定α更新w。
比如α的优化展开为:
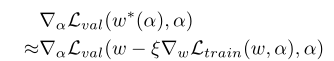
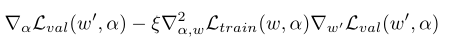
其中二阶项可以通过如下近似得到:
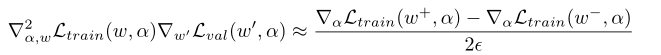
这样计算复杂度会从降为:
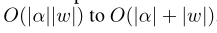
一阶近似:
当ε=0时为一阶近似,二阶导会消失,此时架构梯度退化为:
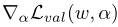 这样计算速度会更快但是性能会变差;
当ε>0时为二阶近似。
这样计算速度会更快但是性能会变差;
当ε>0时为二阶近似。

Part D Deriving Discrete Architectures
为了确定离散架构中每一个结点,保留每一个中间结点前k个最强的候选操作。操作的强度(strength)通过下式计算:
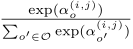
本文中为卷积单元设定k=2也就是保留两个候选操作,为循环单元设定k=1. 以及以上计算是将zero操作排除在外的,因为一是要确认每个节点保证k个非0传入,二是zero操作的强度不好计算。
Section III Experiments and Results
本文在CIFAR-10和PTB数据集上进行试验,包含两大步骤:架构搜索和架构评估。在架构搜索阶段使用DARTS确定每个cell的结构,基于val性能确定最佳的cell;在架构评估阶段,使用前一阶段确定的cell搭建更大的网络,然后从头训练,获得测试集上的性能。还测试了迁移到InageNet和WikiText-2上的性能。
Part A Architecture Search
1-conv cells on CIFAR-10
候选操作包括:3x3 conv,5x5 conv, 3x3x空洞卷积、5x5空洞卷积,3x3最大池化,3x3均值池化,identity,zero并且涉及到的步长为1,通过padding保持分辨率不变。每一次卷积操作包含-ReLU->Conv->BN,并且每一卷积重复两次。
在本节的cell包含7个节点,最后输出是所有中间结点深度上级联的结果(depth concatenation),前两个节点的cell是一样的,分别编号为k-1,k-2.以及在整个网络深度1/3和2/3处会插入reduction cell,因此设计两类结构(αnormal,αreduce)
2-recurrent cells on PTB
候选操作包括:线性变换、tanh,relu,sigmoid,identity,zero
每个cell包含12个节点,两个输入节点线性变换得到第一个中间结点,结果相加后送至tanh激活,剩下的cell需要学习。其余设置与ENAS类似。对于每个任务设置不同的种子重复四次,计算性能的中位数和最佳性能。 并且只学习一种cell然后进行recurrent。

Fig 5展示了学习到的conv cell和recurrent cell。
Part B Architeture Evaluation
为了确定最终用于val的网络架构,本文使用不同的随机种子重复四次,选取平均验证性能最佳的cell然后从头开始训练,其中cifar-10上训练100epoch,PTB训练300epochs。
并且网络权重是随机初始化的,测试集也从未用于架构搜索或架构选择。

Part C Results Analysis

Table 1展示了在CIFAR-10数据集上的搜索结果,可以看到基于DARTS的神经架构搜索算法与目前SOTA算法取得了接近的性能但是计算资源却降低了3个数量级,并且随着搜索时间的增加性能超过了ENAS,cell中参数量也更少。

Table 2展示了在PTB数据集上的搜索结果,发现比其他人工设计的架构性能都高,尤其是比tuned LSTM性能更好,说明了NAS在超参数搜索方面的优越性;在效率方面与ENAS相当,明前优于传统NAS。
有趣的一点是两种实验中随机搜索的性能搜不差,这也充分显示出搜索空间的重要性。


Table 3和Table 4分别展示了CIFAR-10迁移到ImageNet上和PTB迁移到WT2上的结果,均取得了近似性能的前提下大大减少计算资源的消耗,其中迁移到WT2的性能稍弱,一种可能的解释是与CIFAR-10相比,PTB数据集规模较小,因此迁移效果较差,可以通过直接优化在目标任务上的结构来规避这一问题。
Section 4 Conclusion
本文提出了一种高效的可微分的神经架构搜索方法——DARTS可用于卷积和循环单元的搜索。通过将搜索空间连续化,DARTS搜索的架构在图像分类和语言建模任务中可以达到与其他不可微搜索算法相媲美的精度,同时大大减少了计算资源的消耗。
并且DART有诸多优化方向值得进一步探索。比如目前基于连续搜索空间得到的网络架构离散化后可能会存在差距,可以通过调整softmax退火温度减轻这一问题;此外在搜索过程中基于参数共享来探究与网络架构性能的关系也是一个有意思的研究方向。















 3847
3847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









