







论文:https://arxiv.org/pdf/1806.09055.pdf
源码:https://github.com/quark0/darts
看过NAS的同学都知道,之前神经网络结构搜索使用的都是强化学习或者进化算法来搜索,当然PNAS是之后的事情,因为动作空间是离散的,在全局搜索神经网络架构十分耗费资源,而DARTS这篇文章用了数学方法,巧妙地将搜索空间用概率的方式转化为了连续可微形式,然后使用梯度的下降来搜索网络结构。
--------------------------------------------------------------------------------------看完之后感慨甚多,果然数学才是最强有力的杀器。
简介
现有的神经网络结构搜索的方法虽然有效但是需要大量的计算资源支撑,例如在CIFAR-10和ImageNet数据集上进行搜索,强化学习需要2000 GPU day 进化算法需要3150 GPU day。本文为了解决这个问题,从一个不同的角度出发,提出了一种有效的结构搜索办法叫做DARTS(Differentiable ARchitecture Search)。将原有从一个离散的候选结构搜索空间内搜索,替换成一个连续的搜索空间,在这种连续的空间就可以利用可微的性质,此时就可以将搜索任务变化成新的优化目标通过梯度下降的方式来进行优化,就相当于原来是强化学习在离散空间内反复试错,现在变成了网络中的一个优化目标可以直接把网络结构学出来。
DARTS适用于CNN也适用于RNN,并且相对于离散空间内搜索可微的方法速度快了几个量级
Contribution
1.本文提出了一种适用于卷积神经网络和循环神经网络的可微神经网络搜索方法
2.通过大量的实验证明了本文提出的方法在图片和语言处理模型上都远远优于不可微分的搜索方法
3.我们实现了高效的结构搜索,全都归功于使用了基于梯度的优化方法
4.DARTS具有可迁移的特点
方法
搜索空间
搜索cell作为最终神经网络结构的组成单元,然后学习将这些cell堆叠成卷积神经网络或者循环神经网络。
一个cell是一个有向无环图DAG由N个有序节点组成。
每个节点
x
(
i
)
x^{(i)}
x(i)都是一个特征映射,每条有向边
o
(
i
,
j
)
o^{(i,j)}
o(i,j)都代表了一种运算操作
如果有一个节点有两个输入的话就把两个输入做concatenation
每个节点都是通过他之前所有节点的运算得到的(按照tenorflow计算图理解),用公式表示成如下形式
x
(
j
)
=
∑
i
<
j
o
(
i
,
j
)
(
x
(
i
)
)
x^{(j)}=\sum_{i<j}o^{(i,j)}(x^{(i)})
x(j)=i<j∑o(i,j)(x(i))
其中还包含了一个零的操作,用来减少连接
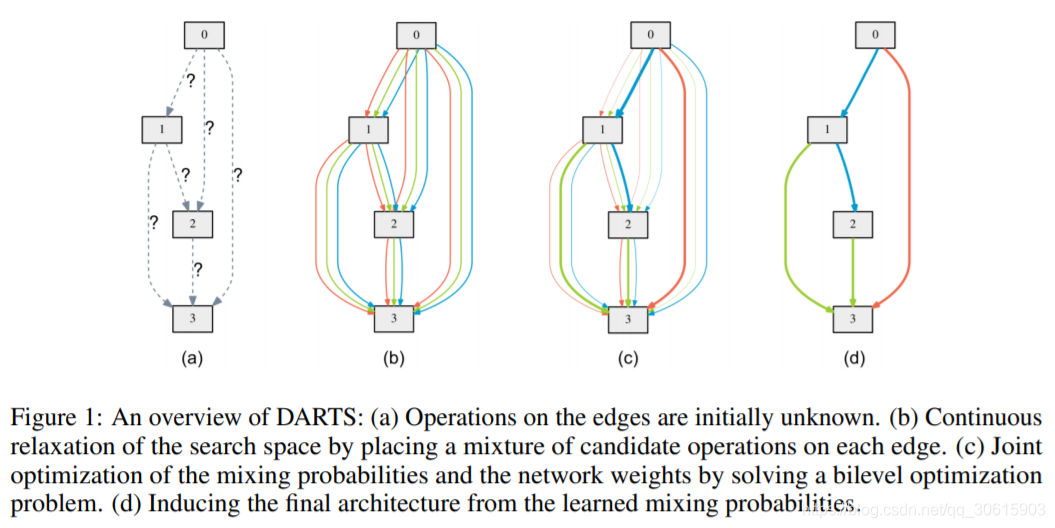
连续松弛优化
用
O
O
O表示候选离散的操作集合(卷积,池化,零)为了让空间连续,对所有的结构计算softmax
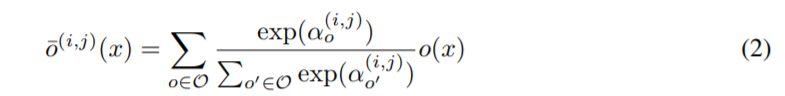
其中运算操作混合权重的一组节点可以表示为一个向量
α
(
i
,
j
)
\alpha^{(i,j)}
α(i,j),搜索完成后,使用最可能的操作替换每一个混合运算操作符就可以得到一个离散的结构。
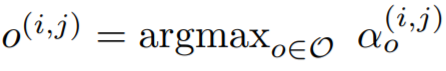
松弛完成后,我们的目标是学习结构
α
\alpha
α和权重
w
e
i
g
h
t
weight
weight w,类似于强化学习或者进化算法,将验证集上的性能看做最终的奖励或者拟合程度,DARTS 的目标就是优化验证集上的loss。
L
t
r
a
i
n
L_{train}
Ltrain 和
L
v
a
l
L_{val}
Lval分别表示训练和验证的loss。这两个loss不仅决定了结构
α
\alpha
α 而且也决定了网络中的权重w。结构的搜索目标是找到
α
∗
\alpha^*
α∗使
L
v
a
l
(
w
∗
,
α
∗
)
L_{val}(w^*,\alpha^*)
Lval(w∗,α∗)最小,其中
w
∗
w^*
w∗通过最小化训练loss得到
w
∗
=
a
r
g
m
a
x
w
L
t
r
a
i
n
(
w
,
α
∗
)
w^* = argmax_wL_{train}(w,\alpha^*)
w∗=argmaxwLtrain(w,α∗)公式表示如下
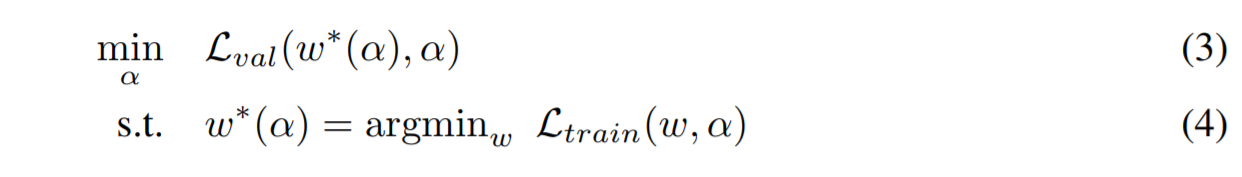
DARTS的伪代码

近似结构梯度
由于上述两层嵌套loss内部优化过程比较昂贵,导致无法求解出准确的结构梯度,为此我们提出了一种简单地近似方法
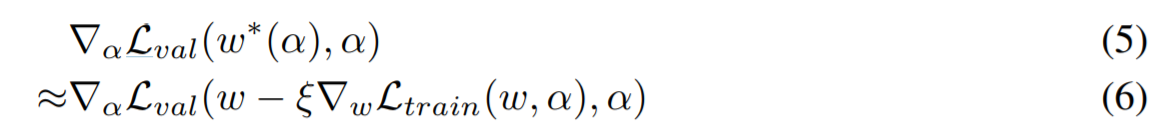
其中w表示算法的当前权重,
ξ
\xi
ξ是内部优化步骤的学习率,目的是通过仅使用单步训练来调整权重w, 来近似
ω
∗
(
α
)
\omega^*(\alpha)
ω∗(α)(这个想法真的秀)需要注意的是在公式(6),如果w已经是最优的情况下,此时
ξ
▽
w
L
t
r
a
i
n
(
w
,
α
)
=
0
\xi▽_wL_{train}(w,\alpha)=0
ξ▽wLtrain(w,α)=0,这个时候公式(6)就可以化简成
▽
α
L
v
a
l
(
w
,
α
)
▽_\alpha L_{val}(w,\alpha)
▽αLval(w,α)
链式法则应用到结构梯度上
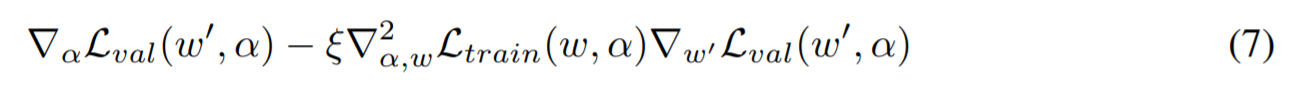
其中
w
′
=
w
−
ξ
▽
w
L
t
r
a
i
n
(
w
,
α
)
w'=w-\xi▽_w L_{train}(w,\alpha)
w′=w−ξ▽wLtrain(w,α) 表示一次步的前向传播的权重,上述表达式后面包含了一个计算复杂度很高的矩阵乘法,文中提出有限差分近似的方法解决
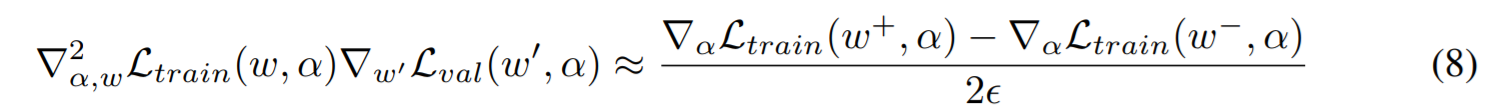
此时的时间复杂度就从
O
(
∣
α
∣
∣
w
∣
)
O(|\alpha||w|)
O(∣α∣∣w∣)降低成了
O
(
∣
α
∣
+
∣
w
∣
)
O(|\alpha|+|w|)
O(∣α∣+∣w∣)
(看到这真的惊到我了,真的是很把数学用的出神入化,学好数学是有多么重要)
推导离散结构
为了形成离散结构中的每个node,我们从之前的非零候选操作集中取出top-k重要的操作。这些操作的重要性是通过softmax计算得到的。k的取值,CNN中的cell时,k取2,RNN中的cell时 k取1。

实验
实验部分,主要在Cifar-10和PTB上进行实验,分别验证DARTS在CNN和RNN上的搜索能力
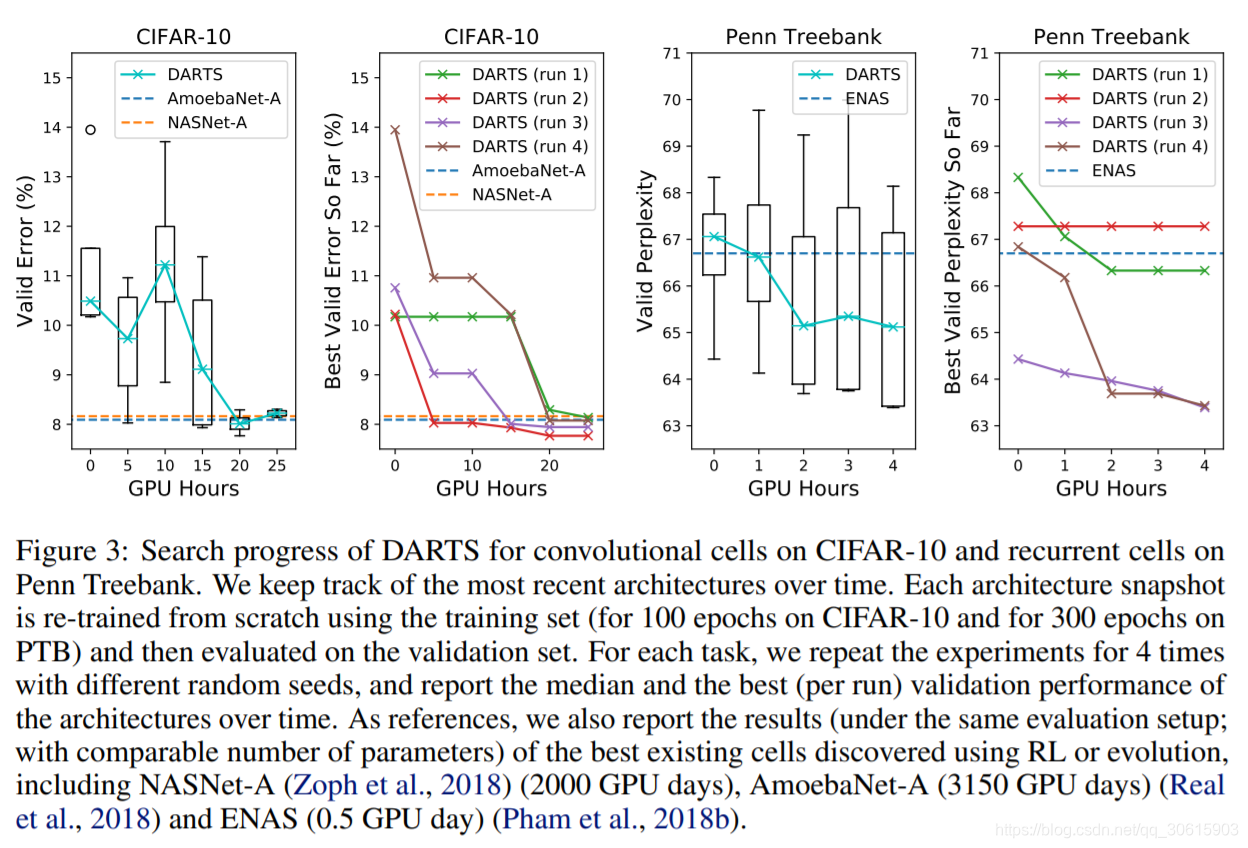
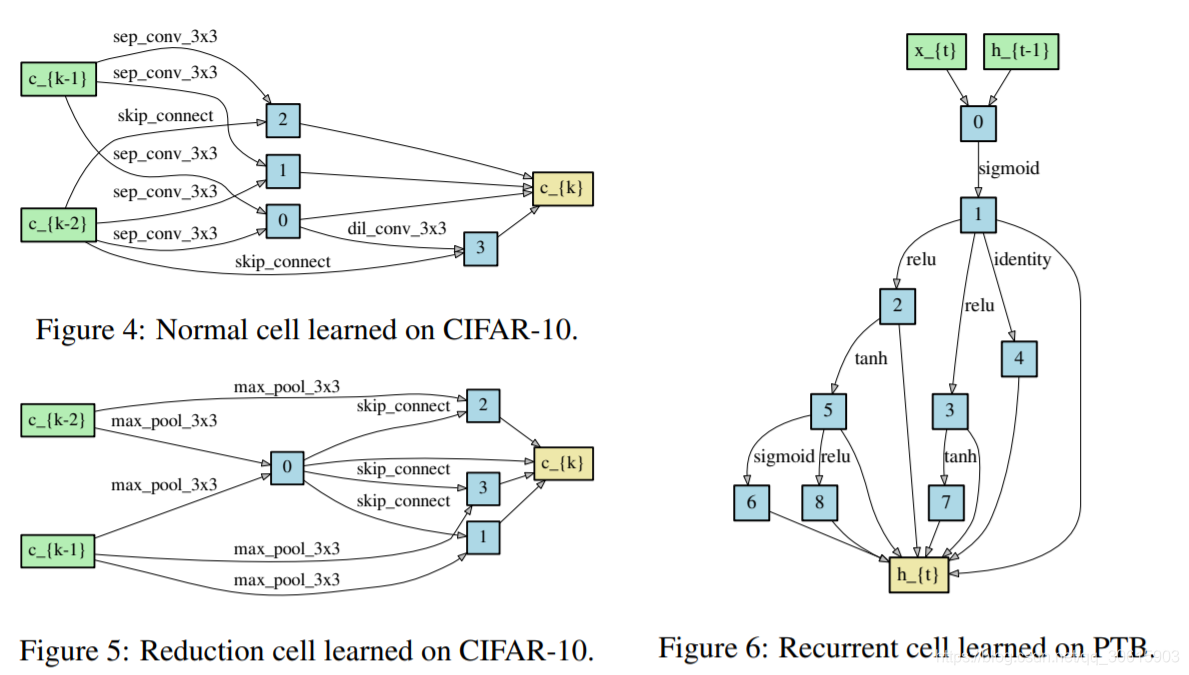
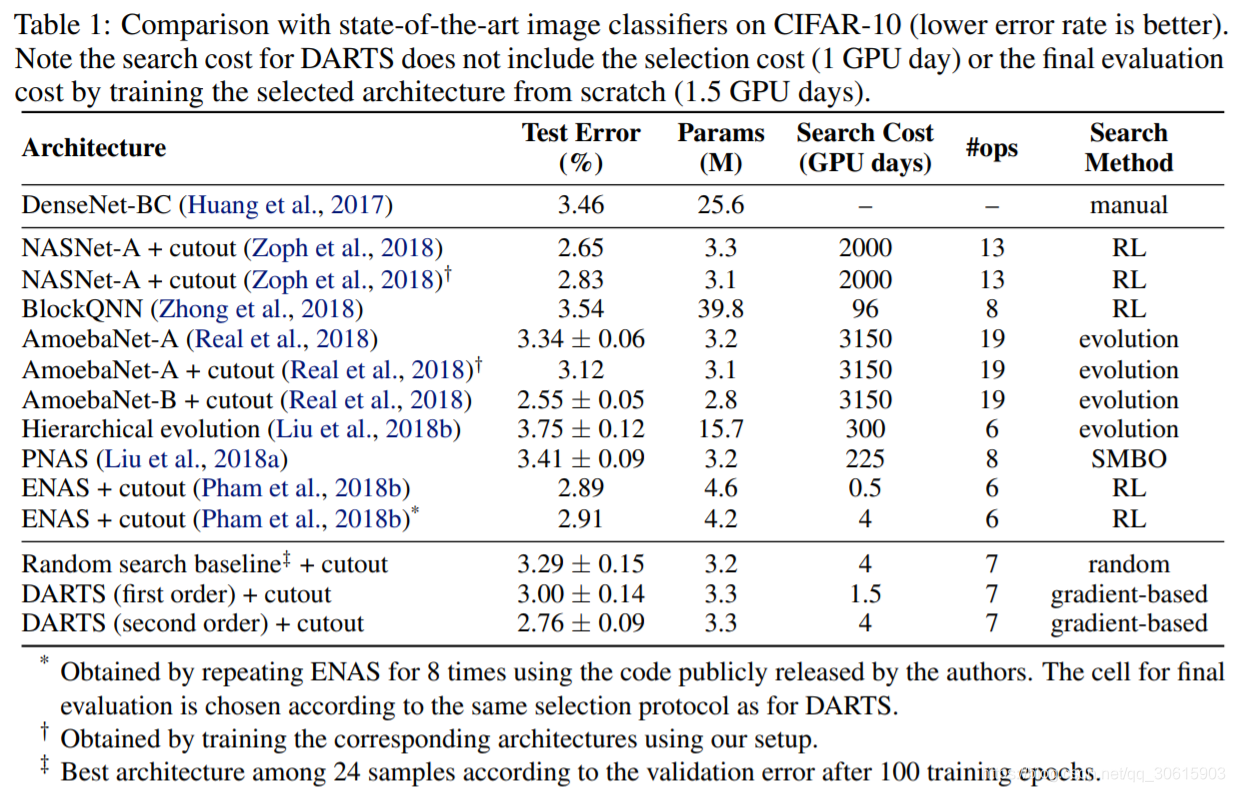
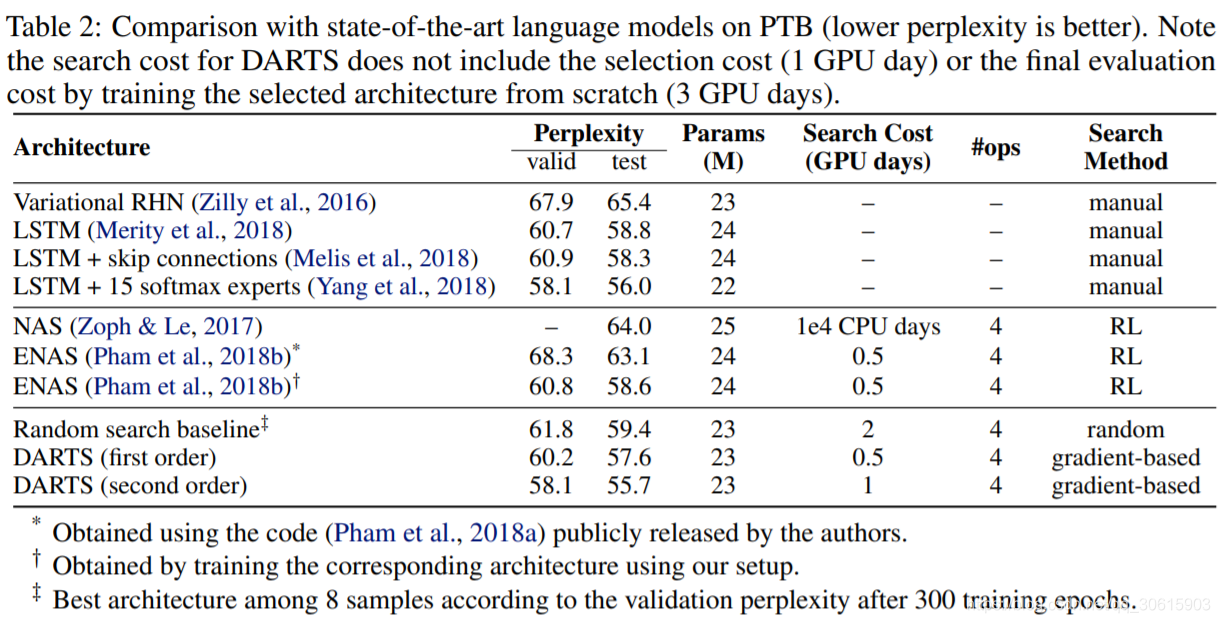
读了这篇paper,给了我很大的冲击,这种将搜索空间转化成可微形式进行优化,是我之前想都没想过的,同时本文的方法优化部分环环相扣,各种数学优化的trick层出不穷,也让我清晰的认识到,数学才是AI领域真正的内功。

















 1000
1000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









