







UNet Transformer:UNet结合自注意力和交叉注意力用于医学图像分割
Abstract
对于一些复杂的、低对比度的组织做医学图像分割十分具有挑战性。本文提出一种U-Transformer网络,将Transformer中的self-attention和cross attention融合进了UNet,这样克服了UNet无法建模长程关系和空间依赖的缺点,从而提升对于关键上下文的分割。
本文集合了两种注意力机制:self-attention建立encoder之间的全局交互,cross-attention被添加在skip connection中,通过过滤非语义特征在UNet Decoder中恢复空间信息。
在肺部CT图像数据集上显示,与UNet和local Attention UNet相比,U-Transformer性能有较大提升。本文强调了同时使用self-attention和cross-attention的重要性,也进行了一定的解释型分析。
Section I Introduction
器官分割在医学成像、CAD等都十分重要,比如为放射科医生提供评估身体变化、计算机辅助干预等辅助信息。
目前的SOTA框架主要基于全卷积神经网络,如UNet及其变体。UNet是一种编码-解码网络结构:encoder通过级联的卷积层提取不同层次的特征;decoder通过skip connection复用encoder提取到的高分辨率特征用于恢复、弥补丢失的空间信息。
尽管FCN系列取得了优异的性能,但是仍有自身局限性:当处理有局部二义性或者低对比度器官时效果不佳。Fig 1(a)展示了用UNet得到的胰腺分割示意图,可以看到由于受限于红色感受野的大小无法捕捉足够的上下文信息,使得分割失败,参见Fig1(c).

本文提出U-Transformer,借助Transformer的特性来帮助建模长程依赖关系和空间依赖关系,U-Transformer保留了原始的U型结构提取归纳偏执,此外引入两种注意力机制来改善网络的决策能力。
首先,self-attention在encoder的结尾用来显式的建模语义之间的全局交互关系;其次,在skip xconnection中引入cross attention从而过滤掉非语义特征,从而更好的协助UNet恢复空间信息。
Fig 1(b)展示了引入cross attention的U-Transformer,可以看到相同语义信息都被highlight了 ,比如 肝、胃、脾脏,从而对全局进行准确的分割。
通过在腹部CT数据集上的实验结果表明,U-Transformer比原始UNet的性能有较大提升。
Related Work
Transformer由最初提出用于NLP领域逐渐发展至解决CV领域的任务,比如non-local nwetwork将self-attention与卷积网络进行了结合;近期的研究重点在于如何近似计算self-attention从而减少trnasformer的计算量、减少对内存的需求。
而本文在UNet中同时引入self attention和cross attention有效的恢复了精细的空间信息和语义信息。
在医学图像分割任务下也有一些工作尝试引入注意力模型,通过注意力机制来有效的结合局部和全局特征,比如Dual Attention Network;但是这些工作没有将Transformer充分的利用起来。比如Attention UNet通过门控信号引入了cross attention,但是其注意力权重图谱也只是基于局部信息计算得到的,而本文的注意力则包含了丰富的空间信息和区域之间的交互信息。
Section II U-Transformer Network
U型网络的编解码结构可以有效提取全局上下文信息进行复杂的医学图像分割任务,本文的U-Transformer将多头Transforemr中的注意力模块引入UNet,通过两种注意力机制(多头自注意力和多头交叉注意力)来提取长程关系和空间依赖性。
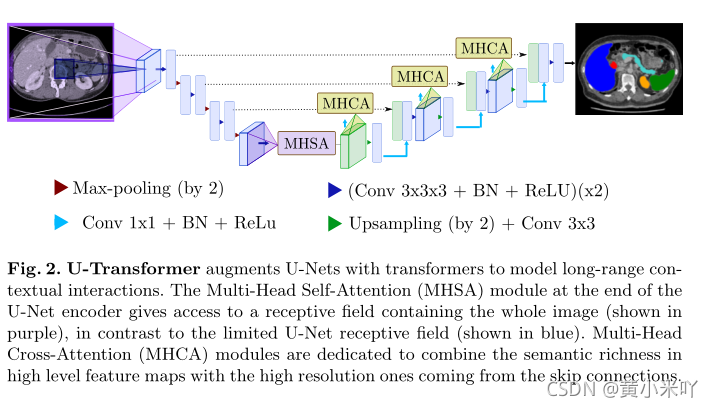
Fig 2展示了U-Transformer的网络结构,MHSA加在encoder的最后,其感受野是整张图像,而原始的UNet的感受野只是局部(蓝色区域);MHCA则是用在decoder中skip connection之后,主要将高层次语义更丰富的特征图谱与来自skipconnection的高分辨率图结合起来。
Part 1 Self-attention
MHSA多头自注意力模块用于提取图像中的长程结构信息,因此本文在UNet做完encoder后的底部加入MHSA,MHSA的主要作用是将抽象feature map中的每个元素之间建立关联,对应的感受野是整张图像。因此当前像素点的分类取决于所有输入像素。
注意力计算公式如下:
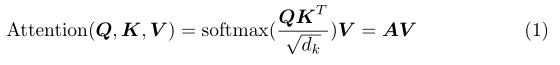
self-attention的计算涉及到Q,K,V三个矩阵,本文中Q,K,V维度相同,只不过是最高层feature map经过不同嵌入之后的结果。
Fig 3展示了MHSA模块的具体计算流程,feature map+positional embedding之后reshape到一定维度,Wq,Wk,Wv是训练的三个矩阵,通过这三个矩阵得到self-attention的计算结果;而positional embedding对于医学图像分割十分重要,因为不同的组织结构分别在图像中不同的固定位置,加入position信息家之后就可以捕获器官之间的绝对信息和相对信息。
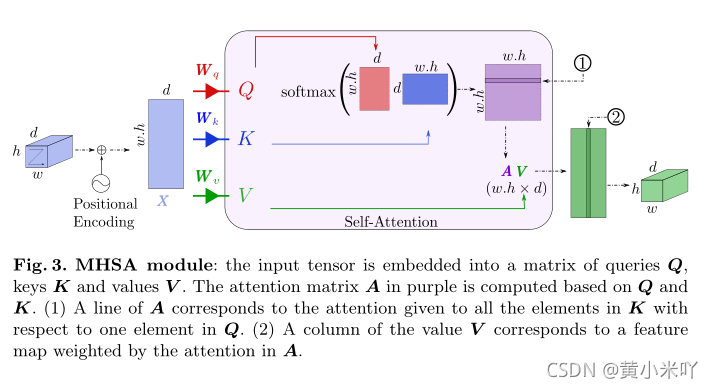
Fig 3中Q,K经过softmax后的结果为注意力系数矩阵A,A乘以V得到最后的注意力输出。
Part 2 Cross Attention
MHSA负责将输入图像的每一个像素之间建立关联,Attention也可以用在UNet decoder部分来提升decoder的效率,尤其是增强经过skip connection连接过来的低层次特征图。
如果skip connection连接的特征图保持丰富的高分辨率信息,那么这些特征图在语义信息上就比较匮乏,MHCA模块的核心思想就是想办法滤除skip connection中无关或噪声区域,突出显示相关区域。
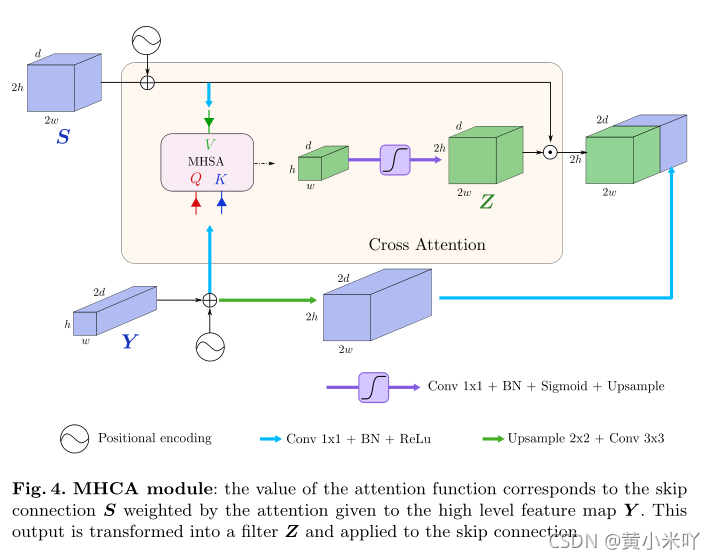
Fig 4展示了MHCA模块的示意图。
MHCA的作用类似于一个门控函数,输入分别是skip connection连接过来的结果S和上一层的feature map Y.处理之后的结果。Y嵌入后的结果作为K,Q,S输入的结果作为V,最后skip connection的输出是S经过Y加权处理之后的结果,计算出来的注意力权重会被rescale到0-1之间,最终cross attention计算的结果Z作为一个filter,与S做点积,其中幅值较小的元素代表噪声或不相关的区域,可以被去除。
这样处理后得到的是清洁版的S,将这一清洁版的结果S再与Y做级联。
Section III Experiments
本文在TCIA胰腺公共数据集和一个多器官分割数据集上测试了U-Transformer的性能。
胰腺分割由于胰腺体积小、结构复杂、外形多变、与周围组织对比度低,使得胰腺分割十分具有挑战性。而做多器官分割主要是为了考察U-Transformer如何利用来自多器官的注意力信息。
实验设定
TCIA数据集:包含82张胰腺CT扫描图 提供了像素级别的标注信息 分辨率 512*512
IMO多器官分割数据集:包含85张7类器官的CT扫描图,类别分别是:肝脏、胆囊、胰腺、脾脏、左右肾、胃部。
两类数据集划分情况:5折验证法 training:testing = 80%:20%
框架:Tensorflow
优化器:Adam
对比网络:UNet,Attention UNet
还测试了仅使用MHSA或仅使用MHCA的效果、UNet原始参数量在30M,将MHSA和MHCA模块的参数量限制在5M和2.5M。
Part 1 U-Transformer
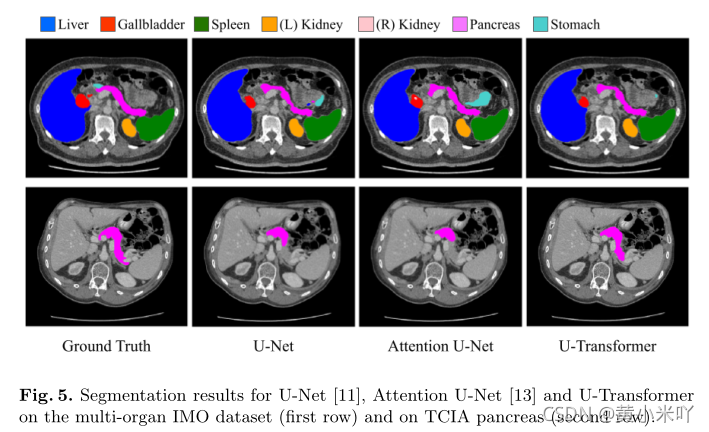
Table 1展示了不同网络在两个数据集上的分割性能,可以看到U-Transfromer达到了最优性能,以及MHCA和MHSA均对最终效果有提升。Fig 5可视化了这些网络的一些分割结果,可以看到U-Transformer在一些难以分割的情况下,比如模糊不清、容易混淆的地方表现尤其优秀,比如第二行的胰腺结构十分复杂,UNet和Attention UNet都无法准确分割,而U-Transformer准确的分割出了胰腺的形状。
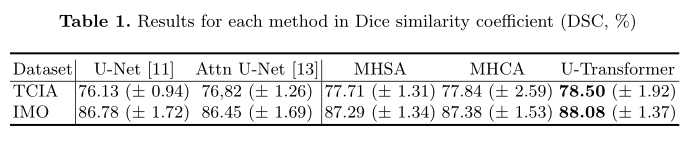
而且根据Table 1的展示结果可以看出,仅使用MHCA或MHSA的性能就已经超过了UNet和Attention UNet.
虽然MHCA和Attention UNet都是在skip connection处引入注意力机制,但是MHCA强调的是对器官的全局结构进行建模,而不仅仅聚焦局部注意力。实验结果证明,MHCA和MHSA这两种注意力可以互相补充,从而更好的进行协同分割。
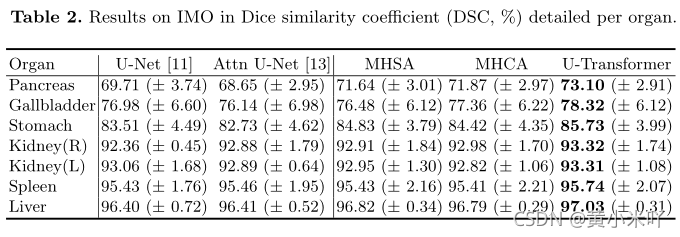
Table 2展示了不同网络对多器官分割的结果,可以看到U-Transformer显著优于Unet和Attention UNet,这充分验证了U-Transformer利用多类别的标注信息来建模不同结构之间的交互,并且可以借助一些容易分割的器官的分割结果来辅助分割难以分割的器官。
Part 2 U-Transformer analysis and properties
Positional encoding and multi-level MHCA
Table 3展示了引入位置嵌入(Positional embedding,PE)和多层次MHCA的对比结果,PE利用了原始图像中不同器官的绝对信息,可以看到引入PE后对胰腺分割、多器官分割均有提升。
而使用单级MHCA和多级MHCA也可以提升性能,虽然Attention UNet也使用了多级注意力,但是性能仍然逊于MHCA的效果。
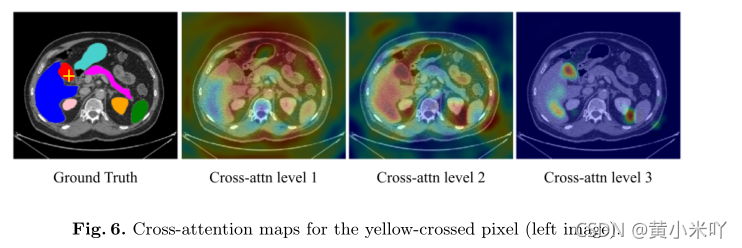
Fig 6可视化了不同层次MHCA的效果,比如level 3对应高分辨率的特征图可以看到倾向于关注特性的局部区域。
Further analysis
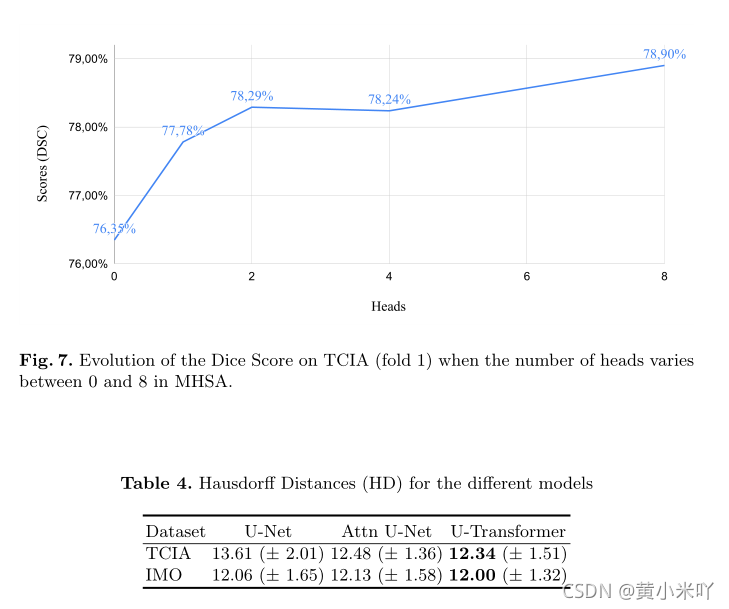
本文还进一步分析了MHSA的作用,Fig 7展示了不同数目的attention head对性能的影响,可以看到头数越多性能越高;但是最大的提升来自引入的第一个head(即从原始的UNet到MHSA)。
Table 4展示的是不同网络分割两个数据集的Hausdorff distance指标,豪斯多夫距离数是对边缘分割的一种度量,可以看到与Dice分数一样,这也说明了U-Transformer借助self-attention和cross-attention有效的增加了预测正确性。
Section IV Conclusion
本文提出的U-Transformer借助Transformer中的self-attention和cross-attention有效增强了UNet的性能,可以有效的捕获长程依赖关系,尤其对复杂器官或较小器官有更好的分割性能。未来将进一步探索U-Transformer在3D图像上的性能,或者在其他模态数据上的性能,如MRI图像;或者探索在其他医学图像分割任务上的性能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









