







CvT:将卷积引入Transformer
Abstract
本文提出一种新的CvT结构通过向Transformer中引入卷积可以提升ViT的性能。主要由两个改进:首先是包含新的卷积Token嵌入的一种新的Transformer层次结构,二是一种使用卷积映射的Transformer block。
通过这两种改进可以有效将CNN的一些特性,如平移不变性、缩放等引入到Transformer中。在诸多实验中验证了CvT可以以更少的参数量、FLOPs等获得更好的性能;如果在大规模数据集上预训练后性能还会进一步提升。
本文还证实了Transformer中很重要的位置编码模块在Cvt中可以完全被移除,这样简化了处理更高分辨率输入的设计。
Section I Introduction
Transformer广泛用于NLP领域和CV领域,但是在一些任务上仍然逊于对应的CNN网络,尤其在小型数据集上。一种可能的原因是ViT缺少CNN一些独有的特性,比如二维图像拥有很强的局部特征,临近的像素点是高度关联的,CNN就可以通过局部感受野、权重共享和空间的下采样提取这些局部特性,因此CNN具有局部性和平移不变性的特点。此外卷积核的层次结构可以考虑不同空间大小的上下文信息,可以很好的捕获浅层的细节、纹理同时也可以捕获抽象的语义。
本文认为卷积可以进一步提升ViT的性能和鲁棒性,目前Transformer享有很高的计算复杂度和内存,为了验证本文的假设提出了CvT结构,将卷积引入到Transformer中来减少FLOPs和参数量。
CvT在Transformer两个核心部分引入了卷积,首先将Transformer划分多个stage,每个stage开始是一个conv token embedding模块,会使用步长卷积来reshape token序列,将其重建回二维形式,这样允许模型既可以捕获局部信息也可以逐渐降低序列长度。其次在每次SA模块之前的linear projection替换为卷积映射,即使用sxs的深度可分离卷积,这样可以进一步不糊哦局部上下文同时减少注意力机制中可能导致的二义性。这样也可以通过控制步长进一步控制计算复杂度。
因此总结一下,CvT借助了CNN的所有优势:如局部感受野、权重共享、空间采样,同时也保留了所有Transformer的优势,动态注意力、全局感受野、更好的泛化性。并且可以移除位置嵌入模块而不糊降低性能,这样简化了网路哦设计同时使其可以更适合处理不同分辨率的输入,这对许多视觉任务至关重要。
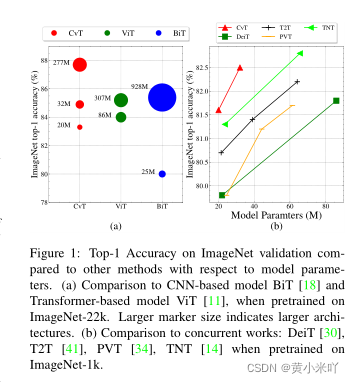
Section II Related Work
Vision Transformer
ViT将图像切分成一系列patch然后嵌入成patch序列,送入Transformer层进行处理。Transformer一般包含MHSA,FFN;本文则关注如何将卷积与Transformer结合从而更高效的提取局部和全局特征。
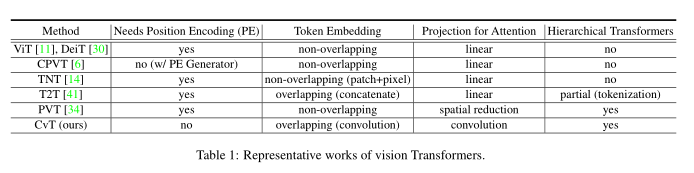
为了很更好的在Vit中建模局部信息也有许多工作做了各种尝试,比如CPVT将位置嵌入模块替换为有条件的位置编码(CPE),可以处理任意大小的输入而不用插值;TNT则是即使用外部的Transformer模块来处理patch embedding又使用内部的Transformer建模像素之间的关联;T2T则是 主要通过滑窗的方式来聚合token;PVT则是搭建了多尺度的Transformer模型来处理密集预测任务。与上述工作的不同在于本文尝试如何将卷积引入到Transformer中,Table 1展示了本文与其他工作的区别。
Introducin self-attention to CNNs
注意力机制被用于CNN模型中来处理视觉任务,比如non-local主要借助全局注意力来提取长程依赖关系;loal-relation nwtworks则根据像素之间的相似性来聚合权重信息,这种自适应的权重调整引入了几何结构这种先验知识到网络中;最近BoTNet则是在ResNet最后三个阶段引入了MHSA,在图像识别任务上取得了大幅提升。本文的方向与之相反,是将卷积引入到Transformer中。
Introducing Convolutions to Transformers
在NLP、语音识别等任务中已经有将卷积引入Transformer的尝试,比如把MHSA替换为卷积层,或者以并行、串联的方式添加卷积层来捕获局部信息。还有的提出将注意力图通过残差连接到后续卷积层中。本文则在Transformer的两个主要部分引入卷积操作,第一是使用卷积投影代替线性投影,二是在多层次结构中使用不同分辨率的2D卷积来reshape token map,这一点和CNN类似。最终显著提升了模型的性能和效率。
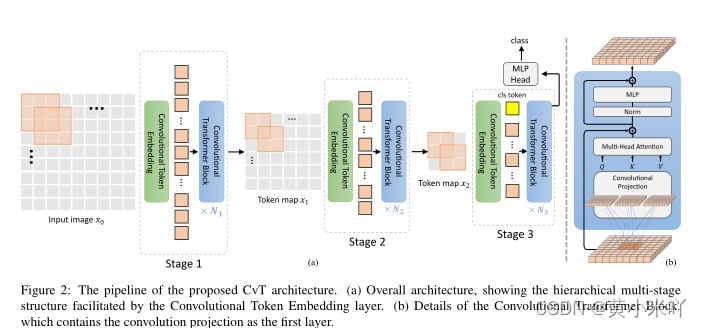
Section III Convolution vision Transformer
Fig 2展示了CvT的整体结构,卷积引入的部分分别叫做Convolutional Token Embedding和Convolutional Projection。
CvT一共包含3个stage,每个stage由两部分组成,首先输入图像会经过convolutional token embedding层,CTE层会执行类似卷积的操作来处理输入特征图或者是reshape后的2D Token map,随后还会经过一个归一化层,这样会逐渐减少token的数目当然token的宽度也会逐渐增多,这代表着空间分辨率的下降,特征表示更丰富,这也与CNN的处理过程比较类似。但是本文与其他Transformer工作不同在于不会将position embedding添加到token上。
另一部分则是提出的Convolutional Transformer Block,模块中使用深度可分离卷积作为convolitional projection来进行q,k,v的映射,而不再使用ViT中的线性映射。
在最后一个stage添加cls token用于类别的预测。
Part 1 Convolutional Token Embedding
CvT中的卷积操作主要用来建模局部空间上下文信息,这样通过多阶段的网络结构可以获得低级到高级的特征,类似CNN的处理流程。
对于输入的特征图或者reshape的2D Token map,会学习token之间的映射,执行的是步长为s的卷积操作,输出大小为:
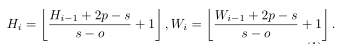
在每个stage使用不同的卷及参数这样可以逐渐减少token序列的长度,同时增加每个token的特征维度;这样可使使得token逐渐能够表达更复杂的视觉模式。
Part 2 Convolution Projection for Attention
之前也有尝试在Transformer模块中添加额外的卷积模块用于语音识别和NLP,但是都使得计算更加复杂。因此本文建议使用深度可分离卷积提到原来的线性投影,执行convolutional projection操作。
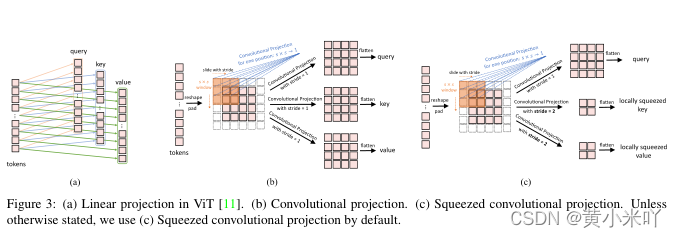
Fig 3分别展示了原始的linear projection和convolutional projection,以及本文的深度可分离卷积映射。可以看到token会被reshape成2D token map,然后经过深度可分离卷积的处理,最终在将token展平会1D用于后续处理,整个处理流程表述为:
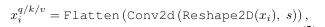
这可以看做是原始Transforemr Block的一种推广,原始的位置信息的投影可以替换为1x1卷积实现。
Part 3 Efficiency Considerations
使用卷积映射有2大好处,一是深度可分离卷积的高效性,使用卷积参数量为s2C2,FLOPs为 C是token channel维度,T是token的数目。 而本文将卷积替换为深度可分离卷积,这样参数量下降到s2C,FLOPs也降到 二是卷积映射可以降低MHSA的计算复杂度。
如果使用卷积核大小为s不同步长的的卷积映射,可以减少token的数目,本文q使用步长=1,k,v的映射均通过步长为2的卷积映射得到。这样k,v的数目就将少了4倍,MHSA中计算复杂度也减少了4倍。也没有带来明显的性能损失,因为图像中相邻像素往往具有语义冗余,而借助卷积的局部性则弥补了由于分辨率降低产生的信息损失。
Part 4 Methodological Discussions
Removing Positional Embeddings
因为基于卷积做token embedding以及使用卷积映射使得模型已经建模了局部空间信息,因此可以移除掉位置嵌入信息还不会带来性能下降,也简化了针对不同分辨率的架构设计。
Relations to Concurrent Work
与同期工作的对比,比如T2T ViT会以渐进的方式进行tokenization,还是基于Transformer作为backbone,但是token的长度是固定的。而本文的Cvt会在不同的阶段逐渐减少token长度,同时增加特征表述的丰富性。
PVT通过搭建金字塔形网路结构处理密集预测任务,ViT中输出的特征图只有单一尺度,本文和PVT类似都是多尺度模型,PVT旨在投影中对特征映射护着k/v矩阵进行下采样,本文则是通过步长卷积实现的下采样。
Section IV Experiments
本文会测试Cvt在图像分类并且迁移到其他下游任务的性能。会先在ImageNet数据集上训练然后迁移到下游任务如CIFAR-10,Oxford-IIIT-Pet,Flowers等数据集。
Part 1 Comparison to SOTA
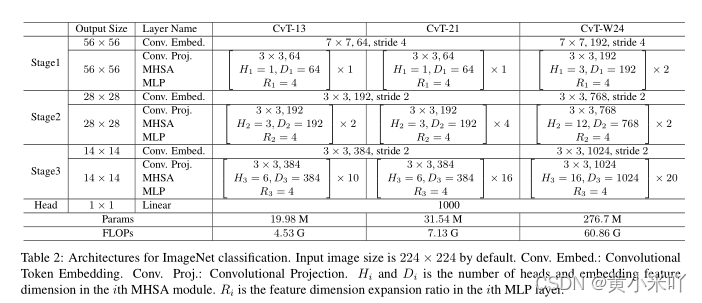
Table 2展示了不同设定下的CvT模型每一个stage的具体信息,并将它们与当前一些SOTA模型进行对比,主要是基于CNN模型和基于Transformer的模型,对比结果参见Table 3。
可以看到与Transforemr模型相比,CvT可以在更少参数量和FLOPs下达到更高的精度,CVt-21在ImageNet达到了82.5%的top-1精度,比DeiT_B参数量减少63%,FLOPs减少60%,精度提0.5%。
本文网络的参数量、FLOPs还可以通过NAS进一步减少。
本文搜索了使用不同步长(1,2)卷积映射到k,v,以及MLP expansion ratio(取2,4)。最终搜索的结果是CvT-13-NAS,具体设定为:
stage 1:stride=2 Mlp Ratio=2
stage 2:stride=1 Mlp Ratio=4
stage 3:stride=2 Mlp Ratio=2
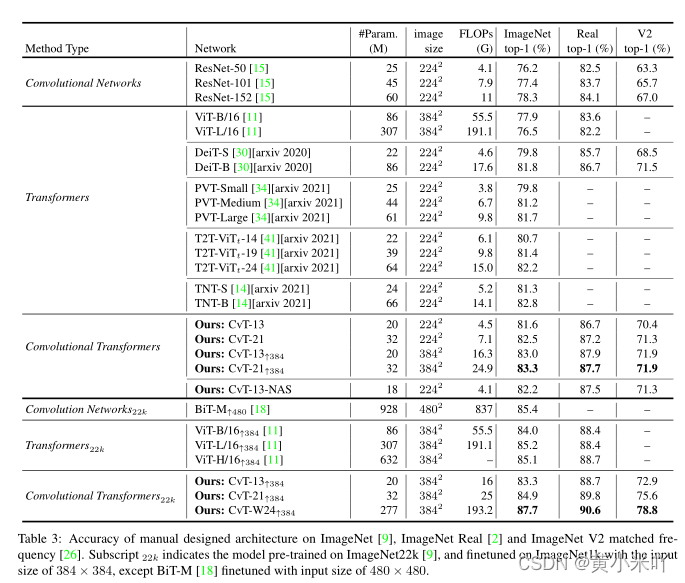
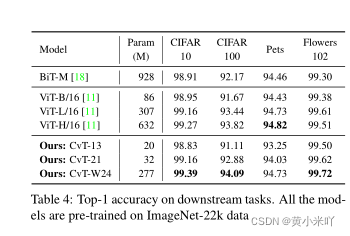
与CNN模型相比,则是进一步缩小了与卷积对应模型的差距,比如CVT-13比ResNet性能提升了3.2%但是参数量只有20M,ResNet是它的三倍。并且随着数据量越来越多,CvT的性能会进一步提升。 Table 4展示了在ImageNet预训练后迁移到下游不同任务后的结果,可以看到预训练后的Cvt在所有下游任务都取得了最佳性能。
Part 2 Ablation Study
接下来还进行了消融实验验证本文一系列设计的有效性。
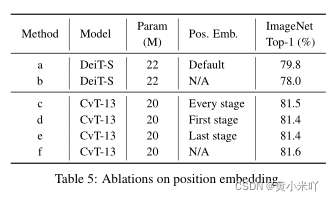
Removing Position Embedding
Tabel 5显示在不同阶段移除位置嵌入模块都没有影响Cvt的性能;相比DeiT-S,移除位置嵌入会使得精度下降1.8%,因为无法建模图像的空间关系,这进一步证明了本文引入卷积的有效性。
位置嵌入通常是固定长度的可学习向量,这就限制了模型接受自适应变化长度的输入,但是通用的视觉模型应该能够接受可变的图像分辨率。
CPVT尝试使用条件位置编码,而Cvt则是完全移除了位置编码模块,使得视觉模型的设计更加简洁。
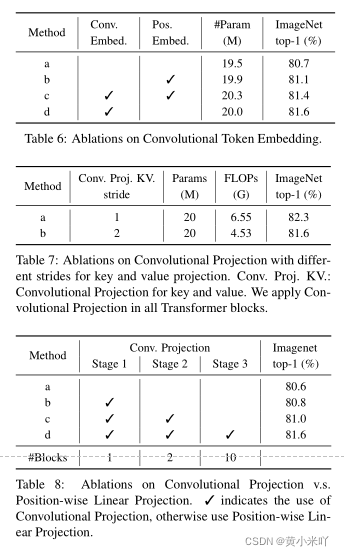
Convolutional Token Embedding
Table 6展示了使用卷积token embedding的有效性,可以看大使用互不重叠的patch embedding时精度下降了0.8% ;位置嵌入结合卷积embedding时有0.3%的提升。这些实验结果说明convolutional token embedding的使用有助于性能的提升,并且不需要位置嵌入的帮助。
Convolutional Projection
Table 7展示了使用不同步长的卷积进行映射的节骨,可以看到key stride=2会有0.3%的性能下降,但是FLOPs却减少了30%,因此本文使用stride=2对key,value进行卷积映射来节省计算和内存成本。
Table 8展示了使用卷积映射了常规的Linearproijection的对比,可以看到精度从80.6%提升到81.5% 。此外可以看到随着stage的增多性能会不断提升,验证了本文的Cvt是一种有效的建模策略。
Section V Conclusion
本文提出一种将卷积融合进Transformer的CvT模型,可以有效的结合卷积和Transformer的优势用于图像识别任务。大量的实验结果表明通过卷积嵌入和卷积投影,以及这种多阶段设计使得CvT在保证计算效率的同时有效提升了性能。此外由于引入了卷积操作获取了局部上下文,CvT还不需要使用位置嵌入,这使得它可以适应不同分辨率的输入,具有更大的应用潜力。

















 1226
1226

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









