







《PyTorch 深度学习实践》第4讲–反向传播算法
1. 张量预备知识
Tensor 中重要的两个成员,data 用于保存权重本身的值 ω \omega ω, grad 用于保存损失函数对权重的导数 ∂ l o s s ∂ ω \frac{\partial loss}{\partial \omega} ∂ω∂loss,grad 本身也是个张量。对张量进行的计算操作,都是建立计算图的过程。
# 测试tensor 中的data和grad
import torch
b=torch.Tensor([1.0])
print('b的类型是:',type(b))
print('b中的data=',b.data)
print('b中的data类型是:',type(b.data))
print('b中的grad=',b.grad)
print('b中的grad类型是:',type(b.grad))
b的类型是: <class 'torch.Tensor'>
b中的data= tensor([1.])
b中的data类型是: <class 'torch.Tensor'>
b中的grad= None
b中的grad类型是: <class 'NoneType'>
2. 实现线性模型 y=wx
# 反向传播算法实现
import torch
import matplotlib.pyplot as plt
# step1 准备数据集
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
x_num=len(x_data) #样本个数
# 定义w为tensor类型,需要计算梯度
w=torch.Tensor([1.0])
w.requires_grad=True
# step2 选择模型 y=wx
# 正向传播
def forward(x):
return w*x
# 计算损失,构建计算图
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
# 模型训练前 预测
print('Predict (before training)',4,forward(4).item())
# step3 训练模型
epoch_list=[]
cost_list=[]
for epoch in range(100):
for x_val,y_val in zip(x_data,y_data):
# 计算损失 lost 是一个张量,tensor 主要是在建立计算图 forward, compute the loss
lost=loss(x_val,y_val)
# 反向传播计算需要计算的梯度
lost.backward()
print('\t grad:',x_val,y_val,w.grad.item())
# 权重更新时,需要用到标量,注意 grad 也是一个张量
w.data-=0.01*w.grad.data
# 释放之前计算的梯度
w.grad.data.zero_()
cost_list.append(lost.item())
epoch_list.append(epoch+1)
print('Epoch: ',epoch+1,'cost: ',lost.item())
# 模型训练后 预测
print('Predict (after training)',4,forward(4).item())
# 绘制损失图
plt.plot(epoch_list,cost_list)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
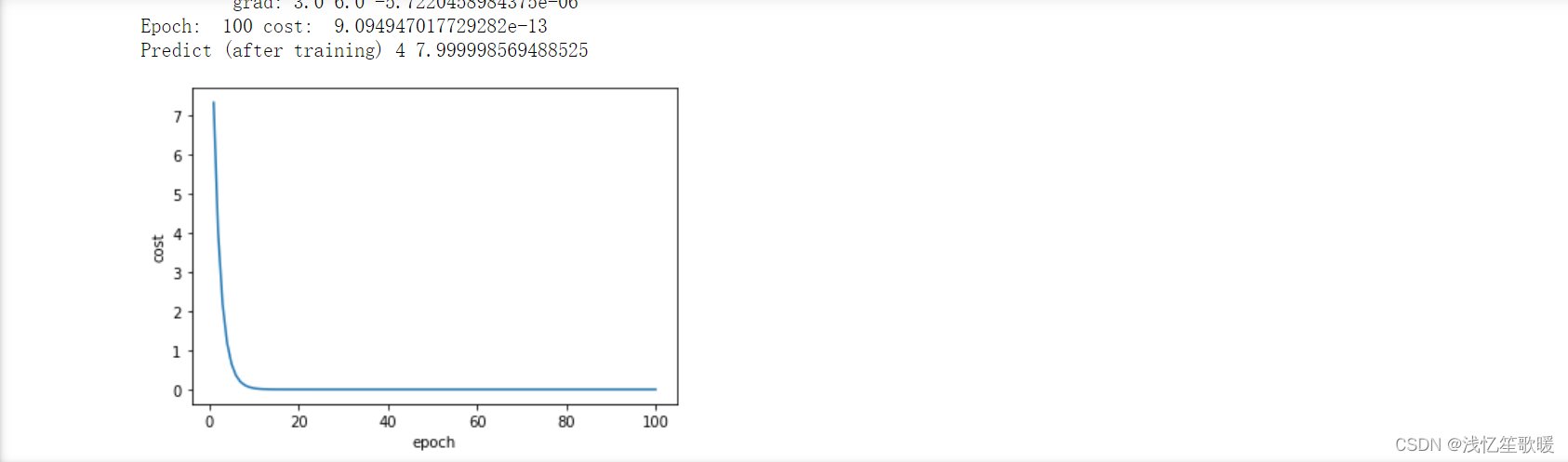
代码说明:
- w是 Tensor 数据类型, forward() 的返回值是 Tensor 数据类型,loss() 的返回值也是 Tensor数据类型.
- 反向传播实现代码是调用 backward(),调用该函数后 w.grad 由 None 更新为 Tensor 数据类型,且 w.grad.data 的值用于后续 w.data 的更新。
- backward() 会把计算图中所有需要梯度 grad 的地方都会求出来,然后把梯度都存在对应的待求的参数中,最终通过调用 grad.data.zero_() 将梯度清零,释放计算图。
- 取 tensor 中的 data 是不会构建计算图的。
3. 实现模型 y=w1x^2+w2x+b
# 接下来实现对模型 y=w1*x**2+w2*x+b 的反向传播
import matplotlib.pyplot as plt
import torch
# step1 准备数据
x_data=[1.0,2.0,3.0]
y_data=[2.0,4.0,6.0]
# 初始化参数 定义w1,w2,b为tensor类型,需要计算梯度
w1=torch.Tensor([1.0])
# 是否需要计算梯度?——True
w1.requires_grad=True
w2=torch.Tensor([1.0])
w2.requires_grad=True
b=torch.Tensor([0.0])
b.requires_grad=True
# step2 选择模型 y=w1*x**2+w2*x+b
# 正向传播
def forward(x):
return w1*x**2+w2*x+b
#定义损失函数 构建计算图
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
# 训练前 预测
# .item()的作用主要是把数据从tensor取出来,变成python的数据类型
print('Predit (before training)',4,forward(4).item())
# step3 开始训练
# 设置一些超参数
epochs=100 # 训练轮次
lr=1e-2 # 学习率
total_cost=[]
total_epoch=[]
for epoch in range(epochs):
for x_val,y_val in zip(x_data,y_data):
# 计算损失 lost 是一个张量,tensor主要是建立计算图 forward,compute the loss
lost=loss(x_val,y_val)
# 利用PyTorch的反向传播函数求梯度
lost.backward()
print('\t grad:',x_val,y_val,w1.grad.item(),w2.grad.item(),b.grad.item())
# 更新参数 需要用到标量,注意grad也是一个tensor
# 这里是数值计算,w一定要取data值,tensor做加法运算会构建运算图,消耗内存
w1.data-=lr*w1.grad.data
w2.data-=lr*w2.grad.data
b.data-=lr*b.grad.data
total_epoch.append(epoch+1)
total_cost.append(lost.item())
# 将之前计算的梯度清零
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
print('Epoch:',epoch+1,'cost=',lost.item())
# step 4 预测
#模型训练好后 预测
print('Prident (after training)',4,forward(4).item())
# 绘制损失函数图
plt.plot(total_epoch,total_cost)
plt.xlabel('epoch')
plt.ylabel('cost')
plt.show()
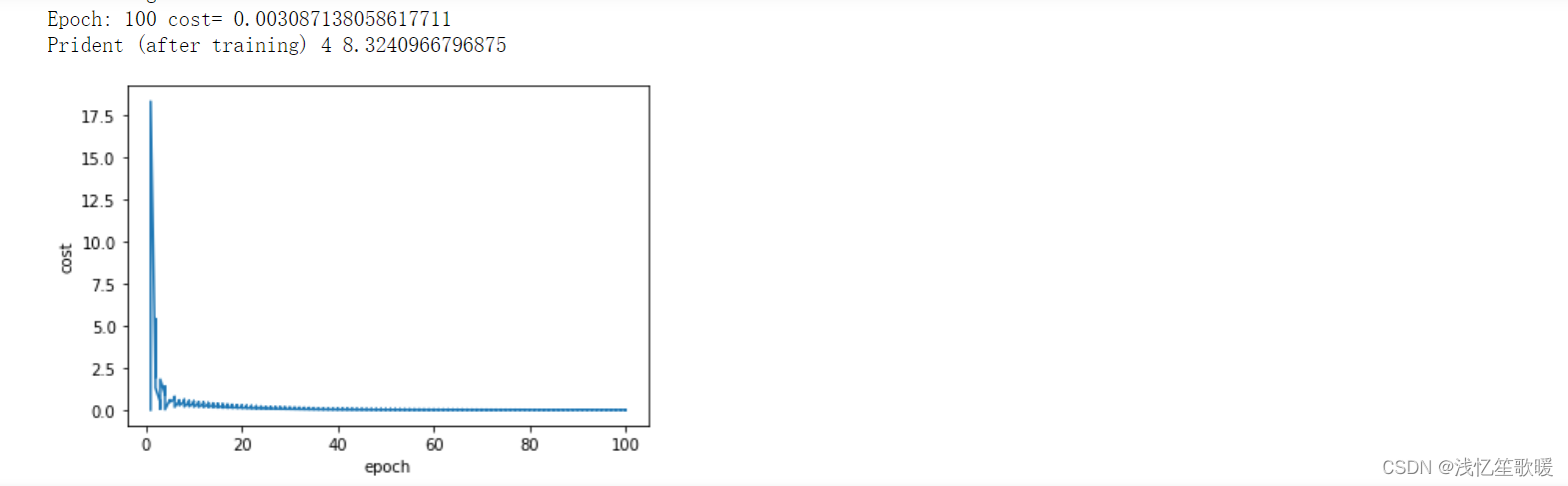
总结:可以看到,训练100轮次后,当x=4时,y=8.3。与正确值8相差比较大,原因可能是使用的模型是二次函数,数据集本身是一次函数的数据,所以导致预测结果和正确值相差比较大的情况。
4. 课后作业
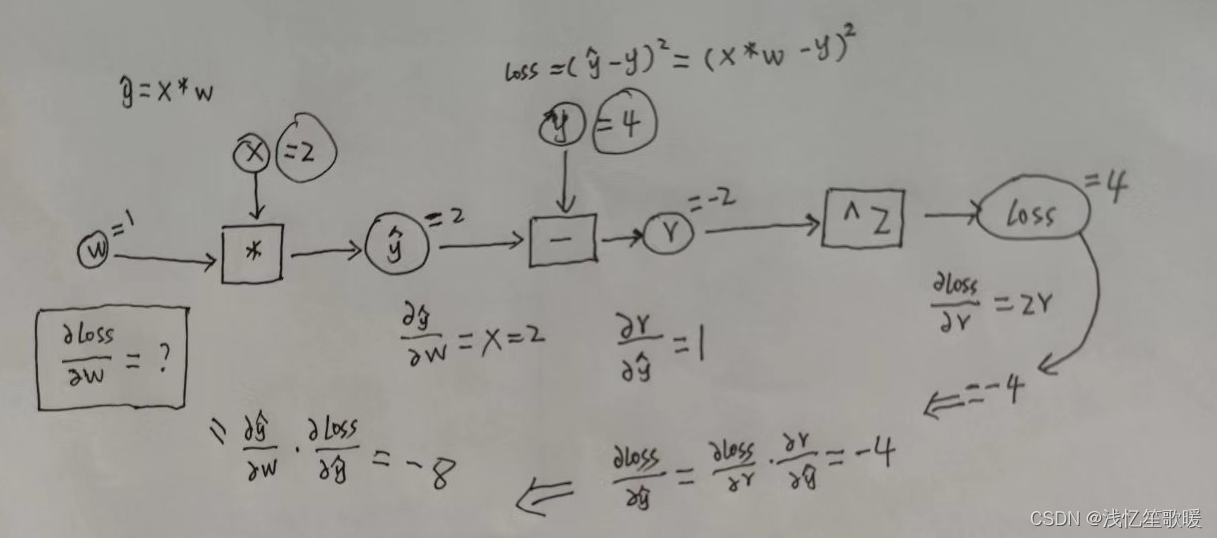
- 4.1 手动推导线性模型 y=w*x,损失函数 loss=(ŷ-y)² 下,当数据集 x=2, y=4的时候,反向传播的过程。
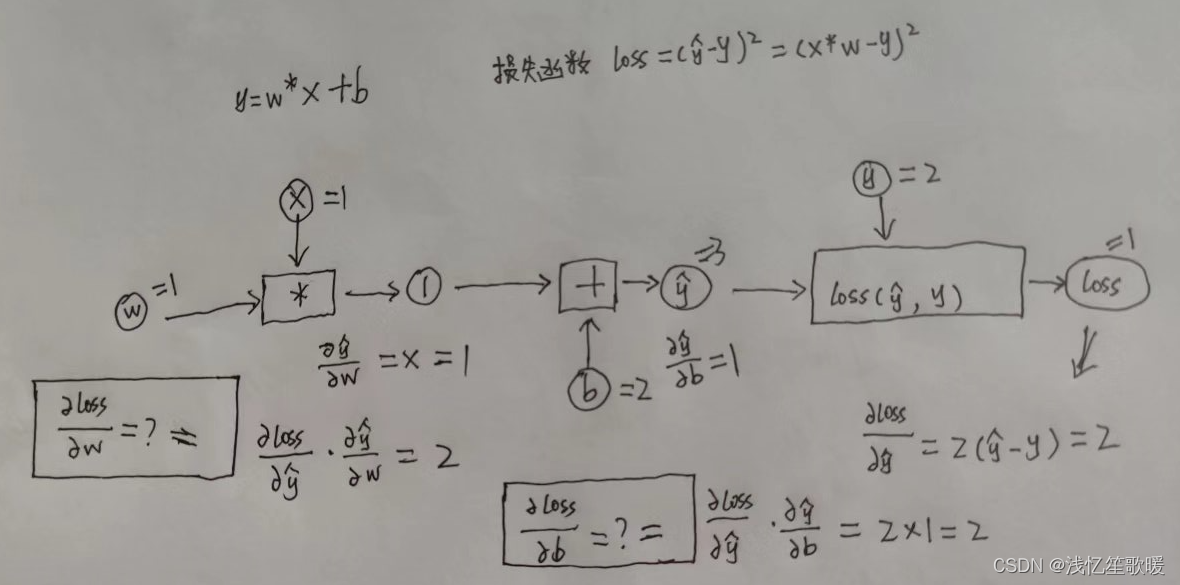
- 4.2 手动推导线性模型 y=w*x+b,损失函数 loss=(ŷ-y)² 下,当数据集x=1, y=2 的时候,反向传播的过程。
- 4.3 画出二次模型 y=w1x²+w2x+b,损失函数 loss=(ŷ-y)² 的计算图,并且手动推导反向传播的过程。

5. 参考
- 《PyTorch 深度学习实践》: https://www.bilibili.com/video/BV1Y7411d7Ys?p=4&vd_source=435453f6c8cc1940667595c415308e92
- 《PyTorch 深度学习实践 第5讲笔记》: http://biranda.top/Pytorch%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0005%E2%80%94%E2%80%94%E5%8F%8D%E5%90%91%E4%BC%A0%E6%92%AD%E7%AE%97%E6%B3%95/
- PyTorch学习(三)–反向传播: https://blog.csdn.net/weixin_44841652/article/details/105046519














 755
755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









