







文章目录
0 前言
最近在学习贝叶斯网络,有些概念已经忘记了,索性就从头开始,将概率—>贝叶斯定理—>贝叶斯网络的公式和概念都串起来讲一遍。
1 概率公式
1.1 联合概率
联合概率指的是包含多个条件且所有条件同时成立的概率,记作P(X=a,Y=b)或P(A,B),有的书上也习惯记作P(AB)。注意是所有条件同时成立,同时发生。
1.2 边缘概率(又称先验概率)
边缘概率是与联合概率对应的,P(X=a)或P(Y=b),这类仅与单个随机变量有关的概率称为边缘概率
1.3 联合概率与边缘概率的关系
P ( X = a ) = ∑ b P ( X = a , Y = b ) P ( Y = b ) = ∑ a P ( X = a , Y = b ) \begin{aligned} &P(X=a)=\sum_b{P}(X=a,Y=b)\\ &P(Y=b)=\sum_a{P}(X=a,Y=b)\\ \end{aligned} P(X=a)=b∑P(X=a,Y=b)P(Y=b)=a∑P(X=a,Y=b)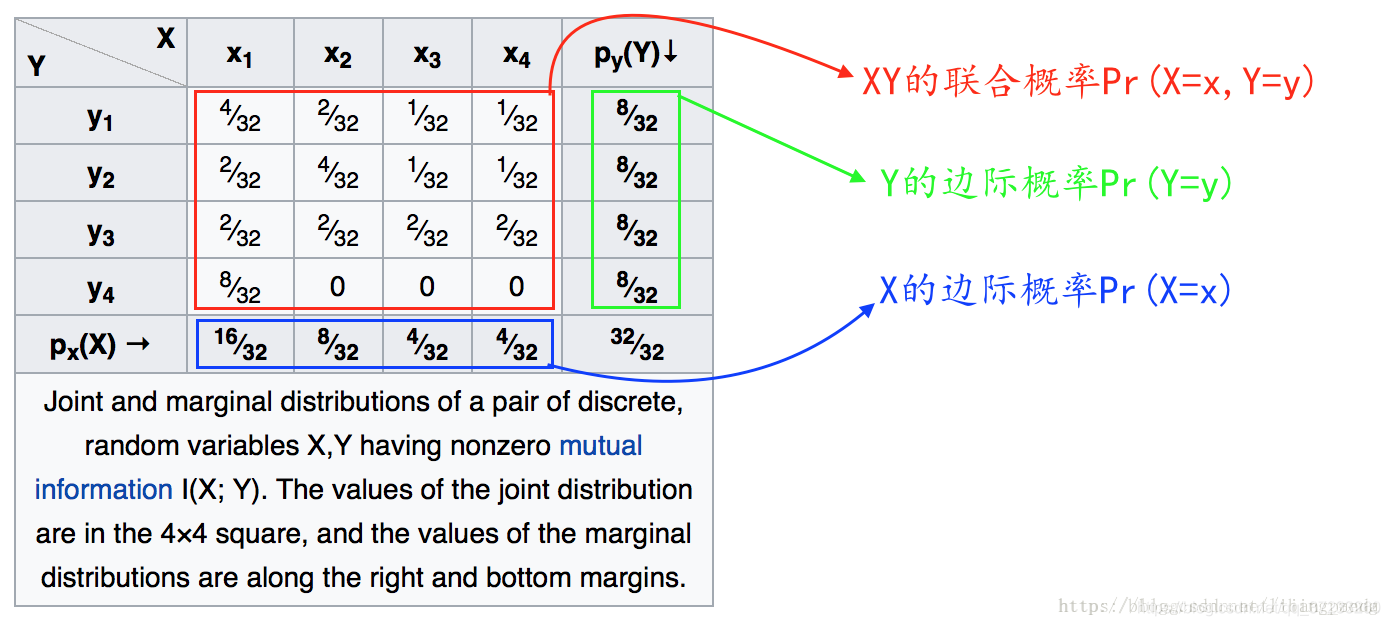
1.4 条件概率(又称先验概率)
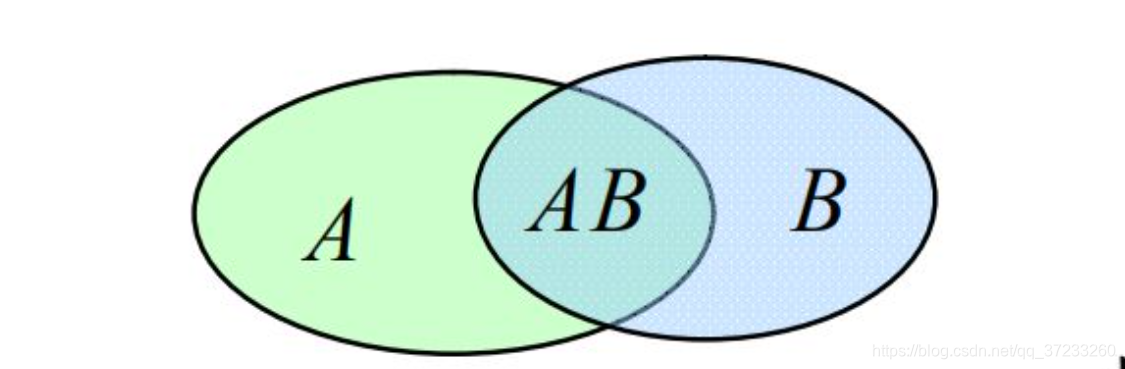
如图, A A A和 B B B不是相互独立的,求在条件 B B B成立的情况下, A A A的概率,记作 P ( X = a ∣ Y = b ) P(X=a|Y=b) P(X=a∣Y=b)或 P ( B ∣ A ) P(B\mid A) P(B∣A),且有 P ( B ∣ A ) ≠ P ( B ) P(B\mid A)\ne P(B) P(B∣A)=P(B)。也就是 A B AB AB中基本事件数占 A A A中的比例:
P ( B ∣ A ) = P ( A B ) P ( A ) P(B\mid A)=\frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)
1.5 全概率公式
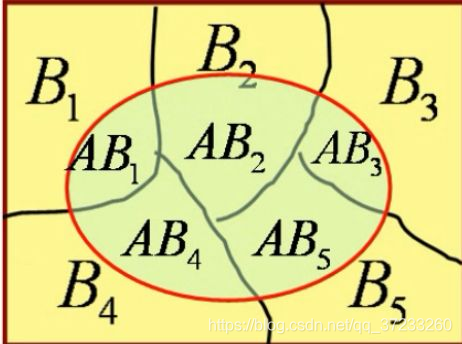
简单推导一下,如图:
P ( A ) = P ( A B 1 ) + P ( A B 2 ) + P ( A B 3 ) + P ( A B 4 ) + P ( A B 5 ) P(A)=P\left( AB_1 \right) +P\left( AB_2 \right) +P\left( AB_3 \right) +P\left( AB_4 \right) +P\left( AB_5 \right) P(A)=P(AB1)+P(AB2)+P(AB3)+P(AB4)+P(AB5)
由条件概率公式:
P ( A B 1 ) = P ( A ) P ( B 1 ∣ A ) = P ( B ) P ( A ∣ B 1 ) P\left( AB_1 \right) =P(A)P\left( B_1\mid A \right) =P(B)P\left( A\mid B_1 \right) P(AB1)=P(A)P(B1∣A)=P(B)P(A∣B1)
代入可以得到:
P ( A ) = P ( A ) P ( B 1 A ) + P ( A ) P ( B 2 ∣ A ) + ⋯ + P ( A ) P ( B 5 ∣ A ) = P ( B 1 ) P ( A ∣ B 1 ) + P ( B 2 ) P ( A ∣ B 2 ) + ⋯ + P ( B 5 ) P ( A ∣ B 5 ) \begin{aligned} P(A)&=P(A)P\left( B_1A \right) +P(A)P\left( B_2\mid A \right) +\cdots +P(A)P\left( B_5\mid A \right)\\ &=P\left( B_1 \right) P\left( A\mid B_1 \right) +P\left( B_2 \right) P\left( A\mid B_2 \right) +\cdots +P\left( B_5 \right) P\left( A\mid B_5 \right)\\ \end{aligned} P(A)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 232
232

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









