







文章目录
0 前言
如果 Network 模型太复杂,受内存空间和计算能力的限制,很难将模型应用到硬件设备上。虽然可以定制化硬件的架构加速模型的运算,不过不是本文讨论重点。本文由整理李宏毅老师视频课笔记和个人理解所得,详细讲述了Network Compression(模型压缩)的原理及实现方法。有问题欢迎在评论区交流,我会及时回复。

1 Network Pruning(网络剪枝)
通常网络模型的参数都是过多的,比如有些weight接近0,或者neuron的输出为0,实际上用不到那么参数。所以就可以将这些多余的参数从网络中移除。

类比下图人脑发育情况,刚出生的时候人脑连接较少,6岁的时候连接较多,但是随年龄增长反而连接减少:

1.1 Base method
网络剪枝怎么具体做呢?
- 预先训练一个比较庞大的模型
- 评估每个weight和neuron的重要性:比如计算L1和L2范数来衡量Weight的数值大小,观察neuron的输出变化。
- 按照参数重要性排序,Remove不重要的参数。不过这可能会导致准确率的下跌,所以一次不能移除太多,否则很难恢复。
- 将缩小的模型用训练资料再Fine-tune(微调)一次,这样可以减小Remove带来的损失。
- 如果缩小的模型没有达到要求,就重新从步骤2开始做一次。

为什么要舍本逐末的做Pruning,而不是直接训练一个规模小的模型呢?常见的说法是规模小的模型比较难训练,而大的模型比较容易做优化。有研究证明,因为模型参数增加之后会使得各个维度的local最优互相碰见的概率减小,所以形成local optimal solution的情况要少很多,大部分时候可以直接求得globally optimal solution。

有一篇论文用彩票的理论来解释为什么要做剪枝而不是直接用小模型。如下图,初始化一个Random init红色网络,然后得到一个Trained网络,再对这个网络做剪枝,获得一个Pruned subnetwork。如果就仅仅以此subnetwork网络结构来重新随机初始化参数之后再训练得到绿色网络,效果就远不如之前的Pruned subnetwork。但是如果将Random init红色网络的初始参数用于subnetwork网络,那么最后效果又会和Pruned subnetwork相同:

可以理解:一个规模的大的网络模型相当于一系列小的网络模型的组合(有不同的初始参数),有的小模型可以训练起来,有的训练不起来,而剪枝操作是从中选择了一个最好的小模型。
1.2 Weight Pruning
剪枝方式有两种,一种是Weight Pruning,一种是Neuron Pruning。对于Weight Pruning的实操是困难的,因为weight缺失之后会改变网络的架构,对于运算是不方便的,所以一般的操作是将剪枝的weight置为0。但是这种方式又似乎并没有使得参数减少,可操作性不大。

下图实验表明:即使是剪枝了95%的weight(weight置为0),但是训练速度仍然没有明显加速,所以并没有达到实际的要求。

1.3 Neuron Pruning
剪枝neuron会是比较好的方式,剪去neuron之后,其前后的weight都消失了,并不会改变计算的结构。因为参数是实际减少了,训练速度也会加快。

2 Knowledge Distillation(知识蒸馏)
基本思想是可以先训练一个规模大的Teacher network,再训练一个小的Student network去学习大的Teacher network的行为。为什么要使用Teacher network的输出来训练而不直接使用Labelled data呢?因为Teacher network可以提供更多的信息,输入一个样本后Teacher network会输出各种类别的概率值,这比单纯的Label信息要更丰富。因为是输出概率,所以使用交叉熵损失来训练是比较好的。

比如从“1”的结果中可以学习到“7”和“9”也形如“1”。

Ensemble Learning(集成学习)是比赛常用的方法,即使叠加很多模型然后求平均,这样可以获得很好的performance,但是实际却用处不大,而Knowledge Distillation的处理方法可以对Ensemble进行提取:

这里有一个小技巧。因为要求Teacher network最后输出是概率,如果最后一层仅使用一般的softmax layer,那可能概率值会很集中,就和直接使用labelled data一样了,如下图左侧:

所以需要将x除以Temperature,然后再经过softmax layer,这样可以获得如上图右侧的结果,分散了各个类比之间的概率。
3 Parameter Quantization (参数量化)
3.1 Base Method
-
使用更少的bit的来存储一个参数。
-
权值聚类:使用聚类中心来代替整个类的值,这样可以减少参数的储存。
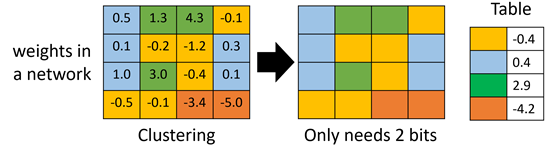
-
使用多的参数用比较少的bit来表示,使用少的参数用比较多的bit来表示,比如哈夫曼编码。
3.2 Binary Weight(二元权值)
Binary Weight:仅使用±1来表示权值。
或者也可以直接训练一个Binary Weight的network——Binary Connect:

具体可以参考这篇博客:文章链接
4 Architecture Design(结构设计)
调整network的结构使得其只需要较少的参数,李宏毅老师认为这是实际中最有效的做法。
4.1 Low Rank Appropriation
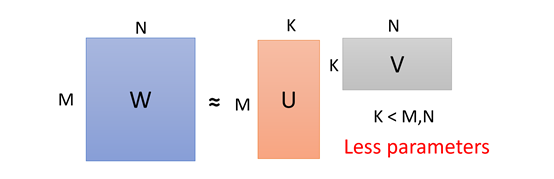
以全连接神经网络为例:

如上图,假设N 层和M层之间有W的权值矩阵,使用一个线性的没有激活函数的具有K个神经元的hidden layer 来替代W矩阵。 因为参数个数W=MN,U+V=K(M+N),只需要控制K的值使得U+V<M,那么就可以减少参数量了。
由于最终的结果也是有下图这个近似,也能保证效果接近。但是UV相乘的rank是小于等于W的,对比于原来的W加了一个限制,所以也会限制模型的能力:
4.2 Depthwise Separable Convolution(切除分离卷积)
4.2.1 Method
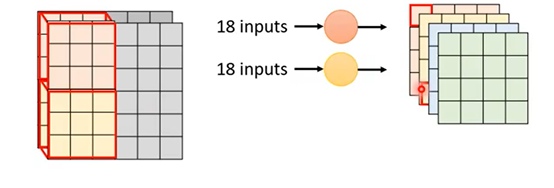
在介绍这个方法前先回顾一下标准CNN一个卷积层需要多少参数。Input feature map是2通道的数据,这里使用了4组2通道的3*3的Filter,来得到了4组4*4的output feature map。因为Filer实际等价于权值W,所以参数就是计算Filter的参数,一共72个:

第一步是Depthwise Convolution(切除卷积):使用同样的2通道Input feature map,但是Filer仅设为单层;Input feature map是多少通道,则使用多少个Filer,用1个Filter去配对Input feature map的1个通道做卷积。最终会获得2组44的output feature map:

因为第一步没有考虑Filer之间的关系,所以第二步就需要考虑进来。第二步是Pointwise Convolution(逐点卷积):第二步和一般的卷积操作是一样的。这里对第一步的输出的2组44的output feature map做卷积,但是仅使用11的Filer,最后可以获得4组44的output feature map:

Depthwise Separable Convolution的输入输出与标准CNN的是一样的,但是由上图计算得到最终该方法使用的参数仅为:18+8=26个。
4.2.2 Intuitive Explanation
更直观的解释一下Depthwise Separable Convolution与标准CNN有什么关系。如下图,对一般的卷积操作来说,output feature map上的一个点等于Input feature map上2层33的矩阵Dot Product(点乘)92个参数之后的结果:
而Depthwise Separable Convolution的output feature map上的一个点来源是中间的“hidden layer”来的,那该方法可以类比上文全连接神经网络的Low rank approximation的做法,核心就是将计算进行拆分,共用部分参数:

计算这两种方法之间参数规模的比例:

最终可以得到CNN和Depthwise Separable Convolution的比值:
k
×
k
×
I
+
I
×
0
k
×
k
×
I
×
0
=
1
0
+
1
k
×
k
\begin{gathered} \frac{k \times k \times I+I \times 0}{k \times k \times I \times 0} \\ \quad=\frac{1}{0}+\frac{1}{k \times k} \end{gathered}
k×k×I×0k×k×I+I×0=01+k×k1
因为通常O比I大很多,第一项可以忽略不计,所以仅看第二项即可。参数规模会缩小到1/kernel size。
5 Dynamic Computation(动态计算)
Network 也可以根据计算资源自我调整:

方式1:训练很多个network模型,根据需求选择不同的network模型。
方式2:训练一个network模型,但是将每一个Hidden Layer 上加一个Classifier:

可以根据运算资源来选择用哪个层输出,资源多则可以用的层数多,反之则少。
但是这样同样会有问题,第一个问题是靠前的Hidden Layer可能效果很差;第二问题是因为Classifier是需要一起训练的,Classifier的加入会影响整个network模型,因为训练Classifier也需要筛选参数。那具体怎么做可以参考这篇论文:
















 3745
3745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









