







引言
因为之前并没有接触到剪枝相关工作,所以有必要了解一些剪枝知识和先人工作。
剪枝核心思想:核心思想:剔除模型中“不重要”的权重,使模型减少参数量和计算量,同时尽量保证模型的性能不受影响。
结构化剪枝:结构化剪枝和非结构化剪枝的主要区别在于剪枝权重的粒度。结构化剪枝的粒度较大,主要是在卷积核的channel和Filter维度进行裁剪,而非结构化剪枝主要是对单个权重进行裁剪。
Learning Efficient Convolutional Networks through Network Slimming:本文提出了一种channel-level的裁剪方案,可以通过稀疏化尺度因子(BN层的scaling factor)来裁掉“不重要”的channel。具体方案为:
- 在训练时,对BN层的scaling factor施加 L 1 L1 L1正则化,在训练网络的同时得到稀疏化的尺度因子;
- 裁掉低于指定阈值的channel:设定裁剪的百分比;依据百分比找到所有尺度因子的阈值;逐层进行裁剪。
- 对得到的模型进行fine-tune以恢复因裁剪损失的精度
CNN中的BN:
我们知道BN层是对于每个神经元做归一化处理,而不是对一整层网络的神经元进行归一化。既然BN是对单个神经元的运算,那么在CNN中卷积层上要怎么搞?假如某一层卷积层有6个通道,每个通道的大小是100100,这样就相当于这一层网络有6100100个神经元,如果采用BN,就会有6100*100个参数
γ
γ
γ、
β
β
β,这样岂不是太恐怖了。因此卷积层上的BN使用,其实也是使用了类似权值共享的策略,把一个通道当做一个神经元进行处理。
卷积神经网络经过卷积后得到的是一系列的特征图,如果min-batch sizes为 m m m,那么网络某一层输入数据可以表示为四维矩阵 ( m , f , p , q ) (m,f,p,q) (m,f,p,q),, f f f为channel个数, p p p、 q q q分别为channel的宽高。我们可以把每个channel看成是一个特征处理(一个神经元),因此在使用Batch Normalization,mini-batch size 的大小就是: m ∗ p ∗ q m*p*q m∗p∗q,于是对于每个特征图都只有一对可学习参数: γ γ γ、 β β β。
0. 摘要

神经元结构化剪枝是一种在不影响预测精度的情况下减少神经网络计算量的非常有效的技术。在以往的工作中,结构化剪枝通常是通过对神经元的尺度因子施加L1正则化,对尺度因子低于一定阈值的神经元进行剪枝来实现的。理由是尺度因子越小的神经元对网络输出的影响越弱。接近0的比例因子实际上抑制了一个神经元。但是L1正则化缺乏神经元之间的区分,因为它将所有的缩放因子推向0。更合理的剪枝方法是只抑制不重要的神经元(比例因子为0),同时保持重要神经元的完整(比例因子较大)。为了实现这一目标,我们提出了一种新的比例因子正则化,即极化正则化。理论上,我们证明了极化正则化将一些比例因子推至0,将其他比例因子推至 a > 0 a > 0 a>0。实验表明,使用极化正则化的结构化剪枝比使用L1正则化的剪枝获得更好的结果。在CIFAR和ImageNet数据集上的实验表明,我们方法达到了最佳效果。
1. 动机
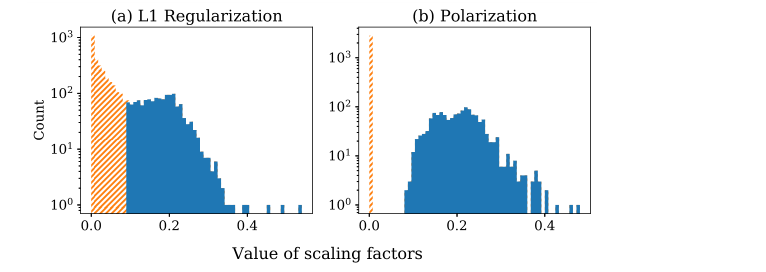
对于结构化剪枝,一种有前途的方法是将每个神经元与一个比例因子相关联,并在训练中正则化这些比例因子。然后修剪比例因子低于某个阈值的神经元。尺度因子的正则化因子通常选择为L1正则化。然而,L1正则化器试图将所有比例因子推至0。往往很难找到合理的修剪阈值。如下图所示,比例因子密集地分布在阈值周围。阈值处的切割不是很合理,因为阈值周围没有将修剪的神经元与保留的神经元分开的余量。用这个阈值修剪将导致严重的准确性下降。
一个更合理的正则化应该更明显地分离被修剪和保留的神经元,它们之间有更大的余量。为了实现这一目标,我们提出了一种新的正则化称为极化。与将所有比例因子推至0的L1正则化不同,极化同时将比例因子推至0(从而修剪这些神经元),并将其余比例因子推至大于0的值(从而保留这些神经元)。
直觉上,极化不是在修剪中抑制所有神经元,而是试图只抑制一部分神经元,同时保持其他神经元完好无损。极化正则化自然会区分修剪的和保留的神经元。并且所得到的比例因子更容易分离。如图1 (b)所示,极化导致修剪的神经元(橙色部分)和保留的神经元(蓝色部分)的比例因子之间有明显的差异。使用极化进行修剪更合理,因为被修剪的神经元对网络输出的影响比保留的神经元小得多。
2. 贡献
我们的贡献如下:
- 我们提出了一种新的正则化方法,即极化,用于神经网络的结构化剪枝。我们从理论上分析了极化正则化的性质,证明了它同时将有些比例因子推至0,将其他的比例因子推至大于0的值。
- 我们在广泛使用的CIFAR和ImageNet数据集上验证了极化剪枝的有效性,并获得了最先进的剪枝结果。
3. 模型
3.1 问题定式
我们需要训练一个神经网络 f ( x ; θ ) f(x;θ) f(x;θ),其中 θ θ θ表示网络参数。我们为每个神经元引入一个比例因子,并将比例因子表示为向量 γ ∈ R n γ \in R_n γ∈Rn,其中 n n n是网络中神经元的数量。我们使用BN中的比例因子作为神经元的比例因子。对比例因子进行正则化的网络训练的目标函数是:
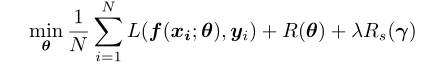
其中 L ( ) L() L()是损失函数, R ( ) R() R()通常是网络权重的L2正则化, R s ( ) R_s() Rs()是神经元比例因子的稀疏正则化。在修剪中,选择阈值,并且修剪比例因子低于阈值的神经元。
3.2 极化正则化
设 γ = ( γ 1 , γ 2 , . . . , γ n ) γ = (γ_1,γ_2,...,γ_n) γ=(γ1,γ2,...,γn),和 I n = ( 1 , 1 , , 1 ) ∈ R n I_n= (1,1,,1) ∈ R_n In=(1,1,,1)∈Rn。设 γ − γ^- γ−表示平均值:

我们需要防止比例因子收敛到一个值。所以我们把极化正则化定义为:
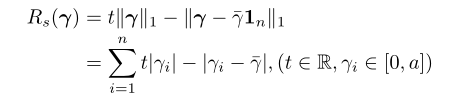
在这个公式中,我们增加了一个新项,它的作用是尽可能将比例因子尽可能远离平均值。实际上,当所有 γ γ γ都相等时,该项达到最大值;当 γ γ γ的一半等于0,而另一半等于 a a a时,该项达到最小值。我们还使用超参数 t t t来控制权重。 t t t还控制正则化下等于0的比例因子的比例。
极化正则化有几个很好的性质。第一个性质是置换不变性,这意味着极化正则化子是置换不变的。这个属性确保所有的神经元在修剪时得到平等的对待,没有任何神经元的优先修剪偏差。该正则化的第二个性质是凹度。
极化正则化的作用是将比例因子推至0,其余比例因子推至 a a a。比例 ρ ρ ρ分段线性取决于超参数 t t t,如下式所示。所以告诉我们比例为0的概率是由 t t t决定的。
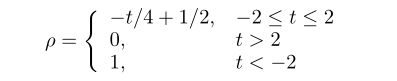
另外有一个值得注意的是,了完全分离两个极点,比例因子的上限 a a a不应太小,理由是对于BN来说,包含 identity transform是很重要的,具体可参考论文(Batch normalization: Accelerating deep network training byreducing internal covariate shift.)
3.3 剪枝策略
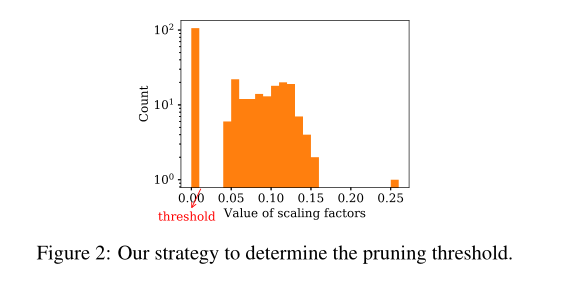
在用极化正则化器训练之后,我们获得比例因子的值和分布。我们仍然需要一个阈值来修剪掉具有小比例因子的神经元。我们利用极化效应,提出了一种更合理的自动设置阈值的策略。由于极化效应,分布图总是至少有两个局部最大值(峰值):一个位于0附近的中心,其他的位于较大值的中心,如图2所示。我们的策略是只修剪属于最接近0的峰值的神经元。因此,阈值位于最接近0的峰值尾部。具体来说,当我们绘制分布直方图时,我们将面元宽度设置为0.01。然后我们从左到右扫描直方图中的面元,找到第一个局部最小面元。那么这个水平坐标就是剪枝的阈值。
我们通过调整两个超参数来控制FLOPS:等式(1)中的 λ λ λ和等式(2)中的 t t t。给定目标数量的减少的FLOPS,我们的目标是选择 λ λ λ和 t t t的值,以便极化修剪将实际上减少目标数量的FLOPS。请注意,减少的FLOPs数量与修剪的神经元数量正相关。
具体搜索算法如下,注意搜索 λ λ λ时使用了二分搜索。

修剪后,我们根据训练数据微调修剪后的网络。
4. 实验结果
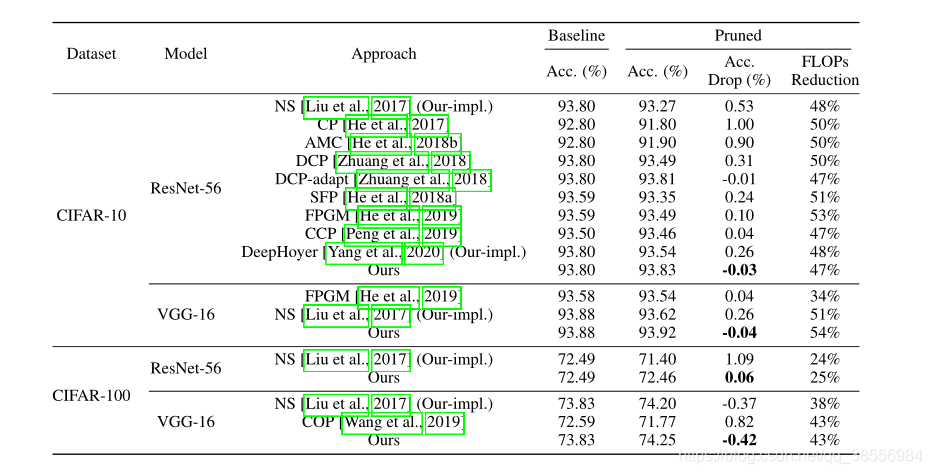
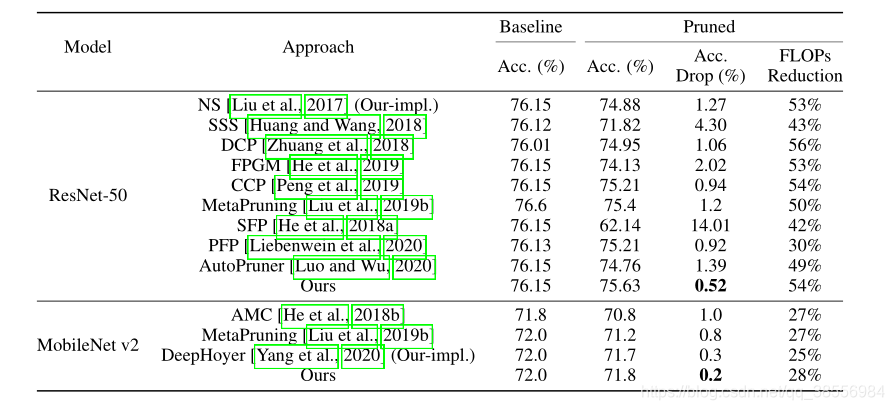
在不同数据集和不同模型的实验效果如下:
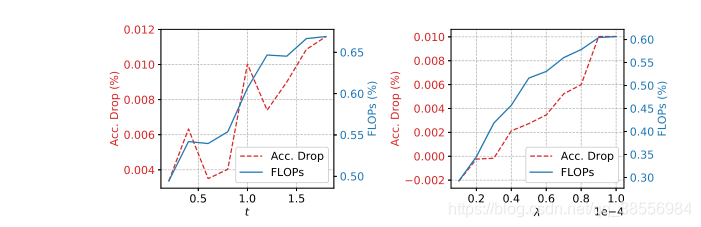
超参数的影响:如图3所示,我们根据经验研究了超参数 t t t和 λ λ λ对减少的浮点运算次数的影响,以及基线和修剪模型之间的精度下降。当 t t t变大时,减少的FLOPs也会变大。这是合理的,与此同时,精度下降的总体趋势是变大,但曲线波动更大。这表明精度下降并不是相对于 t t t单调增加的。当 λ λ λ变大时,FLOPs减小和精度下降都单调变大。这也是合理的,因为λ是等式(1)中极化正则化的总权重。随着 λ λ λ变大,极化正则化对训练的影响越来越大,导致更多的神经元被修剪,精度下降越来越大。
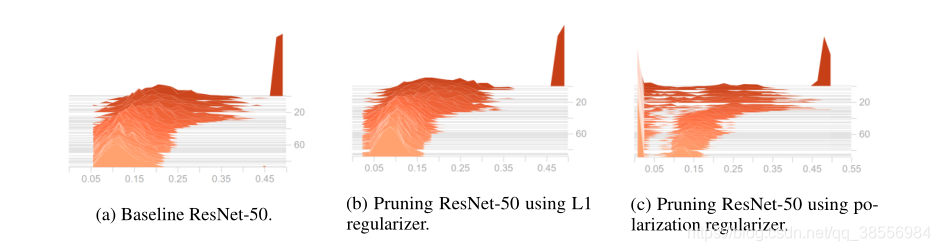
修剪的可视化:如下图所示。在子图©中,我们可以清楚地看到偏振正则化器逐渐将标度因子推向两个簇,一个簇位于0,另一个簇位于更大的值。这两个集群之间有明显的差距;另一方面,子图(b)表明,L1正则化将标度因子推至位于0.09附近的一个簇。
5. 个人思考
该文章出发的两个动机:
- 使剪枝和保留的神经元更加可分
- 抑制不重要神经元,保留重要神经元完好。
论文中有一个不太明白的小问题。论文中的实验结果自己枚举(降低不同的FLOPS然后查看性能影响)得到的最好的一个效果吗?
参考链接:https://www.yuque.com/u1267820/ynt2l2/bfv4i4















 5030
5030











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









