






mysql的slowlog通过filebeat处理,合并为一行以后,格式还是比较复杂的,通过百度可以网上查到一些grok表达式,但有的可用,有的不可用,也没有对此进行解析,比较难看懂。本文通过逐步解析mysql-slowlog,帮助理解这个较为复杂的表达式。
# User@Host: root[root] @ [118.125.0.86] Id: 13\n# Query_time: 16.470589 Lock_time: 0.000090 Rows_sent: 300000 Rows_examined: 300000\nSET timestamp=1671957812;\nSELECT * FROM class_comment;先看一段mysql-slowlog,首先以\n换行符,对这段日志逐步解析。
# User@Host: root[root] @ [118.125.0.86] Id: 13\n首先解析第一行,对应的表达式为
^#\s+User@Host:\s+%{USER:query_user}\[[^\[\]]+\]\s+@\s+\[%{IP:query_ip}\]\s*Id:\s+%{NUMBER:id:int}\s*%{USER:query_user}这是官方预定义的 grok 表达式,用于匹配用户名
查询官方github,可以看到对于USER的定义

\[[^\[\]]+\]这一段是用于匹配一对中括号括起来的非[]符号的任何字符
后面的IP,NUMBER均为预定义表达式,比较好理解
在debugger中验证

接着看第二行
# Query_time: 16.470589 Lock_time: 0.000090 Rows_sent: 300000 Rows_examined: 300000\n这一行比较简单,基本用预定义表达式就可以处理
#\s+Query_time:\s+%{NUMBER:query_time:float}\s+Lock_time:\s+%{NUMBER:lock_time:float}\s+Rows_sent:\s+%{NUMBER:rows_sent:int}\s+Rows_examined:\s+%{NUMBER:rows_examined:int}\s*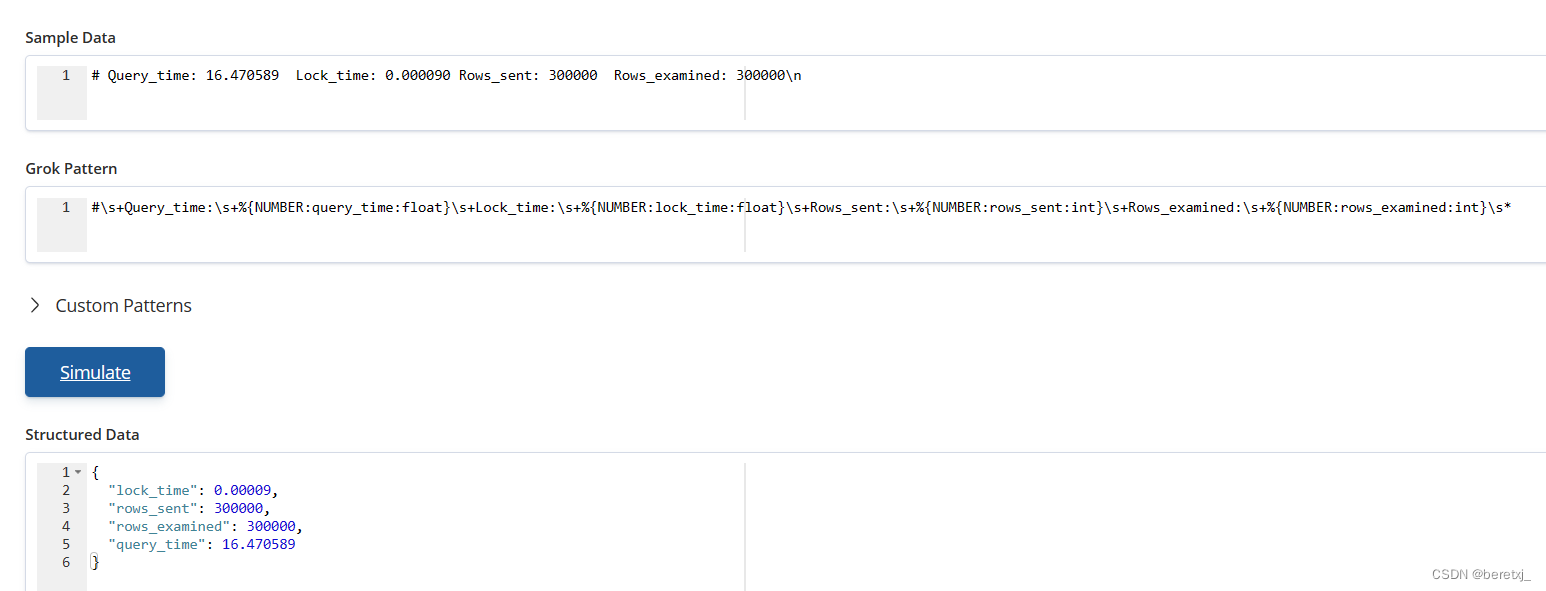 第三行到最后
第三行到最后
SET timestamp=1671957812;\nSELECT * FROM class_comment;表达式为
SET\s+timestamp=%{NUMBER:timestamp};\s*%{GREEDYDATA:query}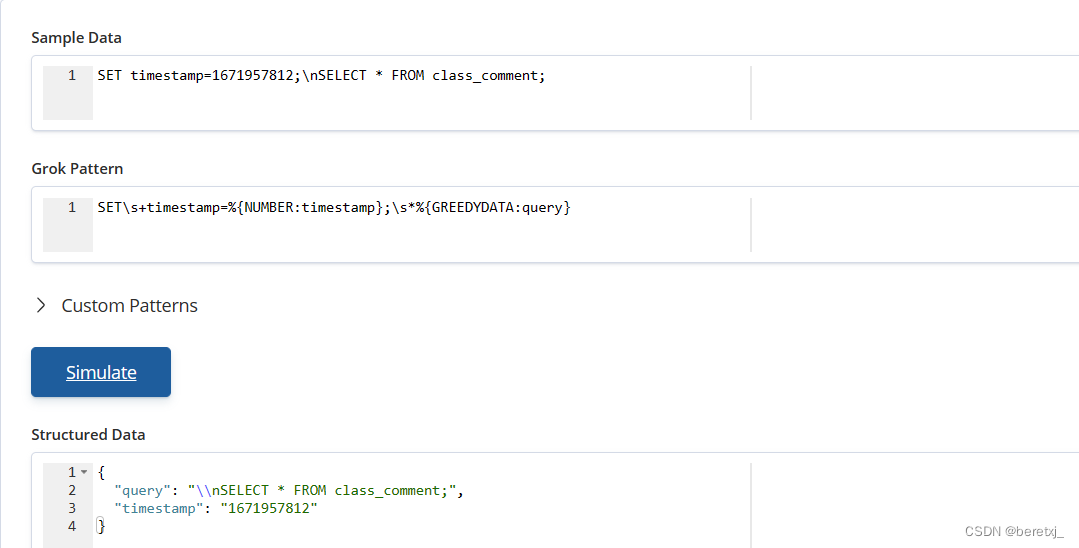
处理也比较简单,因为最后肯定是sql语句,所以使用了GREEDYDATA这个表达式,匹配所有字符
经过以上处理,逐步解决了slowlog各个部分的表达式
那么,我们把这些表示式合并起来,能否正常表示呢?
我们来试试
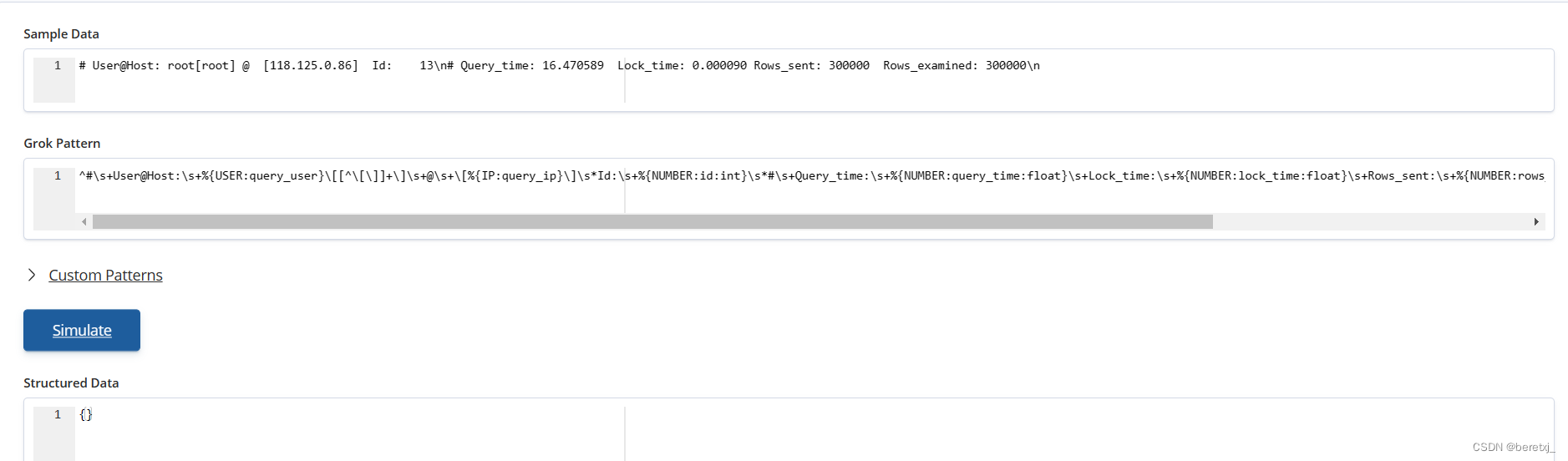
我们把第一行和第二行的表达式合并起来发现是报错的,为什么呢?
因为标准的grok正则表达式是不能匹配换行符的,如果有换行符,必须要单独做处理
查询github,可以发现对于这种情况要在表达式开始位置加 (?m) 标记,然后dot(即点)可以支持匹配回车换行符
https://github.com/kkos/oniguruma/blob/master/doc/RE
+ ONIG_SYNTAX_ONIGURUMA
(?m): dot (.) also matches newline然后我们可以进行如下处理
完整日志:
# User@Host: root[root] @ [118.125.0.86] Id: 13\n# Query_time: 16.470589 Lock_time: 0.000090 Rows_sent: 300000 Rows_examined: 300000\nSET timestamp=1671957812;\nSELECT * FROM class_comment;完整的表达式
(?m)^#\s+User@Host:\s+%{USER:query_user}\[[^\[\]]+\]\s+@\s+\[%{IP:query_ip}\]\s*Id:\s+%{NUMBER:id:int}.*#\s+Query_time:\s+%{NUMBER:query_time:float}\s+Lock_time:\s+%{NUMBER:lock_time:float}\s+Rows_sent:\s+%{NUMBER:rows_sent:int}\s+Rows_examined:\s+%{NUMBER:rows_examined:int}.*SET\s+timestamp=%{NUMBER:timestamp};\s*%{GREEDYDATA:query}
可以看到已经能正常解析。
将这个表达式配置到logstash配置文件中
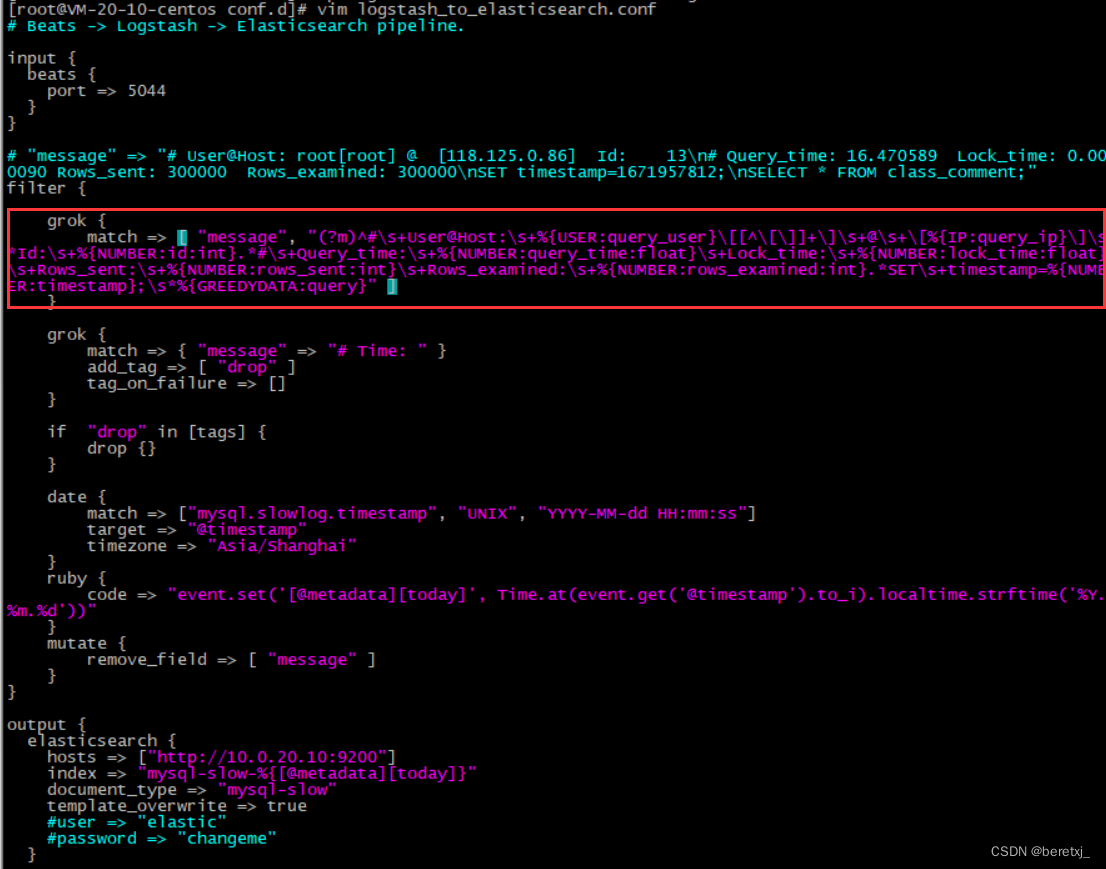
重启程序后,可以发现logstash是可以正常解析给到elasticsearch建立索引的 。
所以,对于遇到的问题,不用总是百度,网上的方案不一定可以正常工作,这时我们把一个较为复杂一点的问题,逐步分析,逐步解决,将一个大问题拆分为几个小问题,这样更有利于问题的处理。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









