







强化学习(二)--DQN算法
上一节课的Q-learning算法和sarsa算法都是基于Q表格的,但是当状态较多时,Q表格占用大量内存且查找不便,针对这个问题,划时代的DQN算法由此诞生。DQN算法是Q-learning算法的改进,它是运用一个神经网络来拟合Q值,具有以下的优点:
- 仅需储存有限的参数;
- 状态泛华,相似的状态可以输出一样的Q值;
1. DQN算法
关于DQN算法的详细讲解可以看一下科老师的公开课(公开课地址),可以很清晰的了解整个DQN算法的详细流程。
这里展示了DQN算法的伪代码:

DQN算法引入神经网络Q来拟合Q值,它有两大创新点:
- Experience replay (经验回放)
- Fixed Q target (固定Q目标)
1.1 Experience replay (经验回放)
经验回放是为了切断输入样本的相关性,并解决了样本利用率低的问题,具体做法是增加一个缓冲区(buffer)来存放与环境交互的数据,学习时再抽取batch来训练Q网络。
一组数据通常为 (s,a,r,s_),因此DQN是一个典型的off-policy算法。
1.2 Fixed Q target (固定Q目标)
固定Q目标是解决算法更新不平稳的问题,因为target_q值也是需要过一遍Q网络才能拿到的,而Q网络是在不定更新的,因此会造成算法的不平稳。举个例子,射箭是我们射击的兔子是在不断运动的,因此很难进行瞄准,而射击靶标时则更容易射中。
未解决这个问题,需要建立一个和Q网络一模一样的Target_Q网络,来输出target_q值,每隔一段时间再拷贝Q网络的参数到Target_Q网络。
1.3 神经网络的LOSS函数
熟悉监督学习的朋友都知道,神经网络学习的反向传递过程是需要计算网络预测值和label值的loss,而在强化学习中是没有label,我们则使用target_q值来作为label。
计算Q网络的预测值和target_q的loss,反向传递来优化神经网络,使其能更好的预测Q值。
2. DQN的代码实现
这里使用的环境是gym中的 ‘CartPole-v0’,它有向左和向右两个action,保持杆子不倒且不超过边界的时间越长,获得的奖励越大。

2.1 代码的整体框架
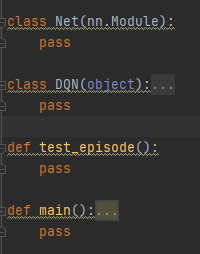
代码的整体框架如下图:如果理解DQN算法按照这个框架可以很容易的实现算法。
- Net类:神经网络的搭建;
- DQN类:DQN算法的主要更新步骤和动作的选取函数;
- test_episode函数:测试算法效果时的函数;
- main函数:主函数。
2.2 主函数
主函数主要实现 run episode的过程,首先定义DQN的类,然后进行400个episode的循环,要注意的地方是:
- 只有在replay memory中存在一定的交互数据后才进行训练;
我们每20个episode进行一下测试,也就是运行test_episode的函数,main函数的代码如下:
def main():
dqn = DQN()
print('\nCollecting experience...')
for i_episode in range(400):
s = env.reset()
ep_r = 0
while True:
env.render()
# 选择动作
a = dqn.choose_action(torch.unsqueeze(torch.FloatTensor(s), 0))
# 与环境交互
s_, r, done, info = env.step(a)
# 重新定义reward
x, x_dot, theta, theta_dot = s_
r1 = (env.x_threshold - abs(x)) / env.x_threshold - 0.8
r2 = (env.theta_threshold_radians - abs(theta)) / env.theta_threshold_radians - 0.5
r = r1 + r2
# 存入数据到经验池
dqn.store_transition(s 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 391
391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









