







DQN算法
DQN(Deep Q-Network)是一种基于深度学习的强化学习算法,被广泛应用于解决各种复杂的决策问题。本文将对DQN算法进行总结,并探讨其在不同领域的应用。
DQN算法概述
DQN算法是由DeepMind提出的一种基于神经网络的强化学习算法,它的核心思想是将Q-learning算法与深度神经网络相结合。相比传统的Q-learning算法,DQN算法通过引入深度神经网络可以处理高维输入状态空间,使得算法具备更强的表达能力和泛化能力。
DL与RL结合
目前相关问题
DL需要大量带标签的样本进行监督学习;RL只有reward返回值,而且伴随着噪声,延迟(过了几十毫秒才返回),稀疏(很多State的reward是0)等问题;
DL的样本独立;RL前后state状态相关;
DL目标分布固定;RL的分布一直变化,比如你玩一个游戏,一个关卡和下一个关卡的状态分布是不同的,所以训练好了前一个关卡,下一个关卡又要重新训练;
过往的研究表明,使用非线性网络表示值函数时出现不稳定等问题。
DQN解决问题方法
通过Q-Learning使用reward来构造标签(对应问题1)
通过experience replay(经验池)的方法来解决相关性及非静态分布问题(对应问题2、3)
使用一个CNN(MainNet)产生当前Q值,使用另外一个CNN(Target)产生Target Q值(对应问题4)
DQN算法流程:
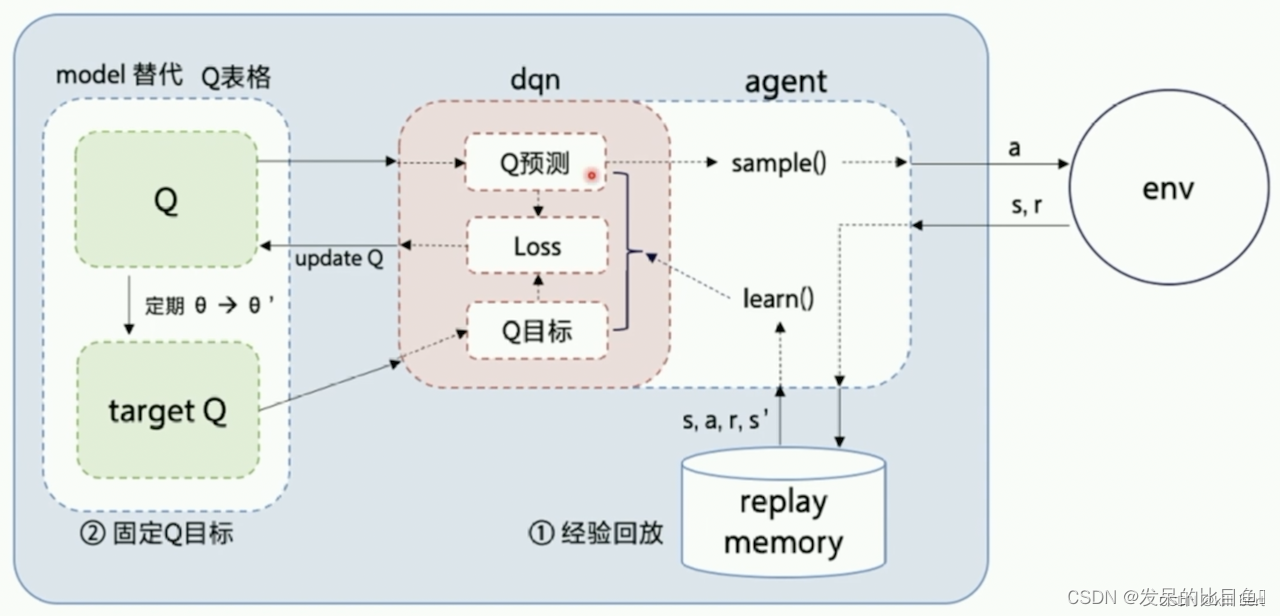
- 初始化经验池,随机初始化Q网络,初始化target Q \mathrm{Q} Q 网络,其参数与 Q \mathrm{Q} Q 网络参数相同;
- repeat
- 重置环境,获得第一个状态;
- repeat
- 用 ϵ \epsilon ϵ-greedy策略生成一个action: 其中有 ϵ \epsilon ϵ 的概率会随机选择一个action,即为探索模式;其他情况下, a t = max a Q ( s t , a ; θ ) a_t=\max _a Q\left(s_t, a ; \theta\right) at=maxaQ(st,a;θ) ,选择在 s t s_t st 状态下使得 Q \mathrm{Q} Q 最大的action,即为经验模式;
- 根据动作与环境的交互,获得反馈的reward r t r_t rt 、下一个状态 s t + 1 s_{t+1} st+1 和是否触发终止条件 done;
- 将经验 s t , a t , r t , s t + 1 s_t, a_t, r_t, s_{t+1} st,at,rt,st+1, done 存入经验池;
- 从经验池中随机获取一个minibatch的经验;
- Qtarget t = { r t , if done r t + γ max a ′ Qtarget ′ ( s t + 1 , a ′ ; θ ) , if not done _t=\left\{\begin{array}{c}r_t, \text { if done } \\ r_t+\gamma \max _{a^{\prime}} \operatorname{Qtarget}^{\prime}\left(s_{t+1}, a^{\prime} ; \theta\right) \text {, if not done }\end{array}\right. t={rt, if done rt+γmaxa′Qtarget′(st+1,a′;θ), if not done
- 根据 Qpred t _t t 和 Q Q Q target t t t 求loss,梯度下降法更新Q网络;
- until done = = = True
- 每隔固定个training step,更新target Q \mathrm{Q} Q 网络,使其参数与 Q \mathrm{Q} Q 网络相同;
- until Q ( s , a ) Q(s, a) Q(s,a) 收敛
代码
QLearning使用表格估计Q函数,不便于扩展.
所以使用神经网络估计Q函数.
- 游戏环境
import gym
#定义环境
class MyWrapper(gym.Wrapper):
def __init__(self):
env = gym.make('CartPole-v1', render_mode='rgb_array')
super().__init__(env)
self.env = env
self.step_n = 0
def reset(self):
state, _ = self.env.reset()
self.step_n = 0
return state
def step(self, action):
state, reward, terminated, truncated, info = self.env.step(action)
over = terminated or truncated
#限制最大步数
self.step_n += 1
if self.step_n >= 200:
over = True
#没坚持到最后,扣分
if over and self.step_n < 200:
reward = -1000
return state, reward, over
#打印游戏图像
def show(self):
from matplotlib import pyplot as plt
plt.figure(figsize=(3, 3))
plt.imshow(self.env.render())
plt.show()
env = MyWrapper()
env.reset()
env.show()
- 定义模型
import torch
#定义模型,评估状态下每个动作的价值
model = torch.nn.Sequential(
torch.nn.Linear(4, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 64),
torch.nn.ReLU(),
torch.nn.Linear(64, 2),
)
model
- 创建数据
from IPython import display
import random
#玩一局游戏并记录数据
def play(show=False):
data = []
reward_sum = 0
state = env.reset()
over = False
while not over:
action = model(torch.FloatTensor(state).reshape(1, 4)).argmax().item()
if random.random() < 0.1:
action = env.action_space.sample()
next_state, reward, over = env.step(action)
data.append((state, action, reward, next_state, over))
reward_sum += reward
state = next_state
if show:
display.clear_output(wait=True)
env.show()
return data, reward_sum
play()[-1]
- 经验池化
#数据池
class Pool:
def __init__(self):
self.pool = []
def __len__(self):
return len(self.pool)
def __getitem__(self, i):
return self.pool[i]
#更新动作池
def update(self):
#每次更新不少于N条新数据
old_len = len(self.pool)
while len(pool) - old_len < 200:
self.pool.extend(play()[0])
#只保留最新的N条数据
self.pool = self.pool[-2_0000:]
#获取一批数据样本
def sample(self):
data = random.sample(self.pool, 64)
state = torch.FloatTensor([i[0] for i in data]).reshape(-1, 4)
action = torch.LongTensor([i[1] for i in data]).reshape(-1, 1)
reward = torch.FloatTensor([i[2] for i in data]).reshape(-1, 1)
next_state = torch.FloatTensor([i[3] for i in data]).reshape(-1, 4)
over = torch.LongTensor([i[4] for i in data]).reshape(-1, 1)
return state, action, reward, next_state, over
pool = Pool()
pool.update()
pool.sample()
len(pool), pool[0]
- 训练
#训练
def train():
model.train()
optimizer = torch.optim.Adam(model.parameters(), lr=2e-4)
loss_fn = torch.nn.MSELoss()
#共更新N轮数据
for epoch in range(1000):
pool.update()
#每次更新数据后,训练N次
for i in range(200):
#采样N条数据
state, action, reward, next_state, over = pool.sample()
#计算value
print(model(state).shape)
value = model(state).gather(dim=1, index=action)
#计算target
with torch.no_grad():
target = model(next_state)
target = target.max(dim=1)[0].reshape(-1, 1)
target = target * 0.99 * (1 - over) + reward
loss = loss_fn(value, target)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if epoch % 100 == 0:
test_result = sum([play()[-1] for _ in range(20)]) / 20
print(epoch, len(pool), test_result)
train()
















 2806
2806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









