







 本文介绍了LMDeploy在大模型部署中的实践,重点关注其量化技术,通过INT4和FP16的混合使用减少显存消耗,以及高效的推理引擎设计。还提供了GitHub上的实践教程链接。
本文介绍了LMDeploy在大模型部署中的实践,重点关注其量化技术,通过INT4和FP16的混合使用减少显存消耗,以及高效的推理引擎设计。还提供了GitHub上的实践教程链接。
LMDeploy 大模型量化部署实践


大模型部署背景


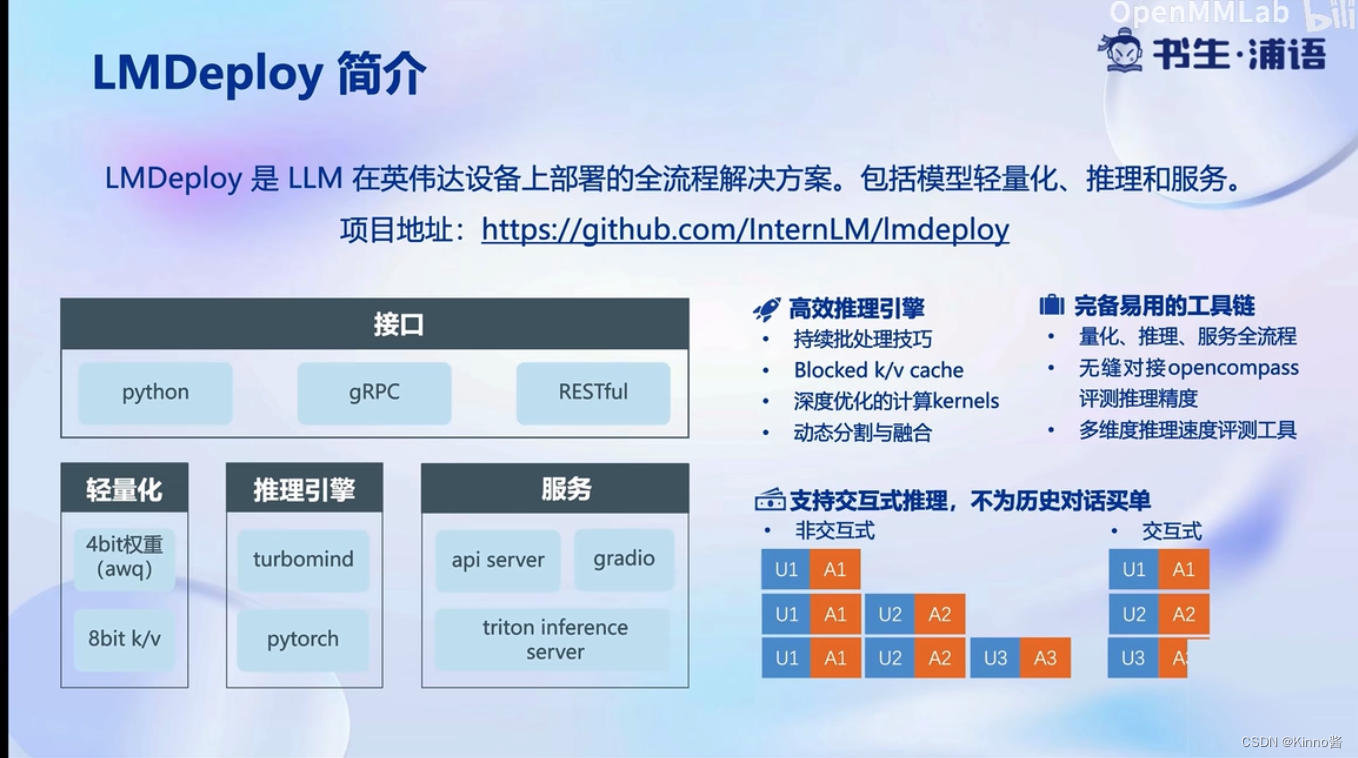
LMDeploy简介
轻量化、推理引擎、服务
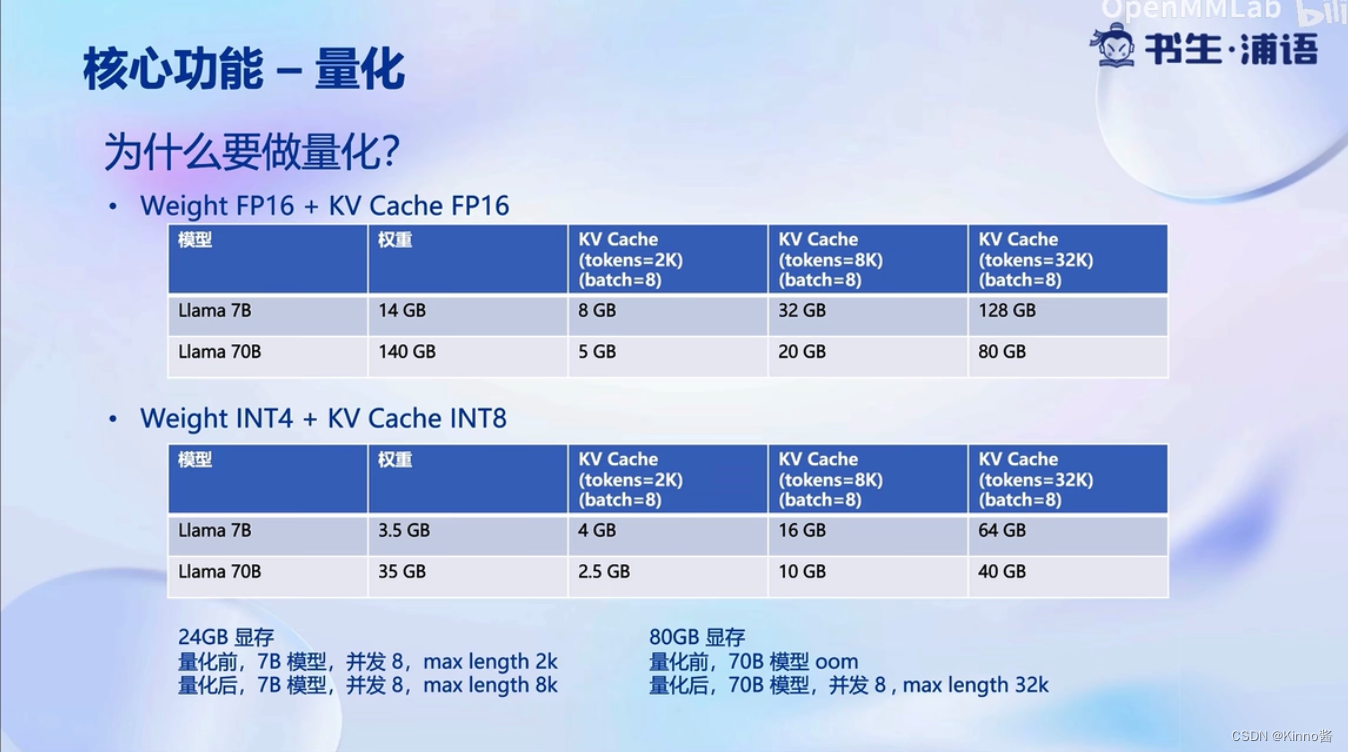
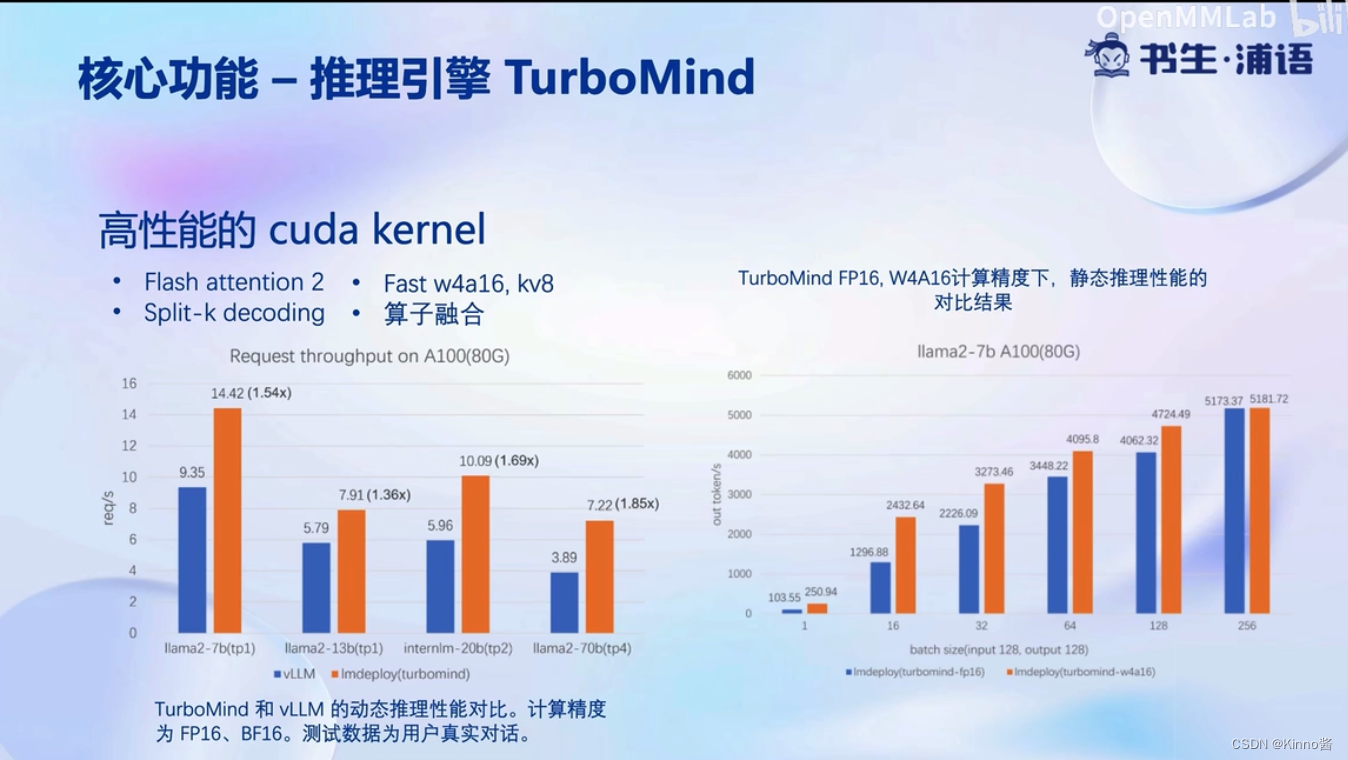
核心功能-量化
显存消耗变少了

大语言模型是典型的访存密集型任务,因为它是decoder-by-decoder
先把数据量化为INT4存起来,算的时候会反量化为FP16
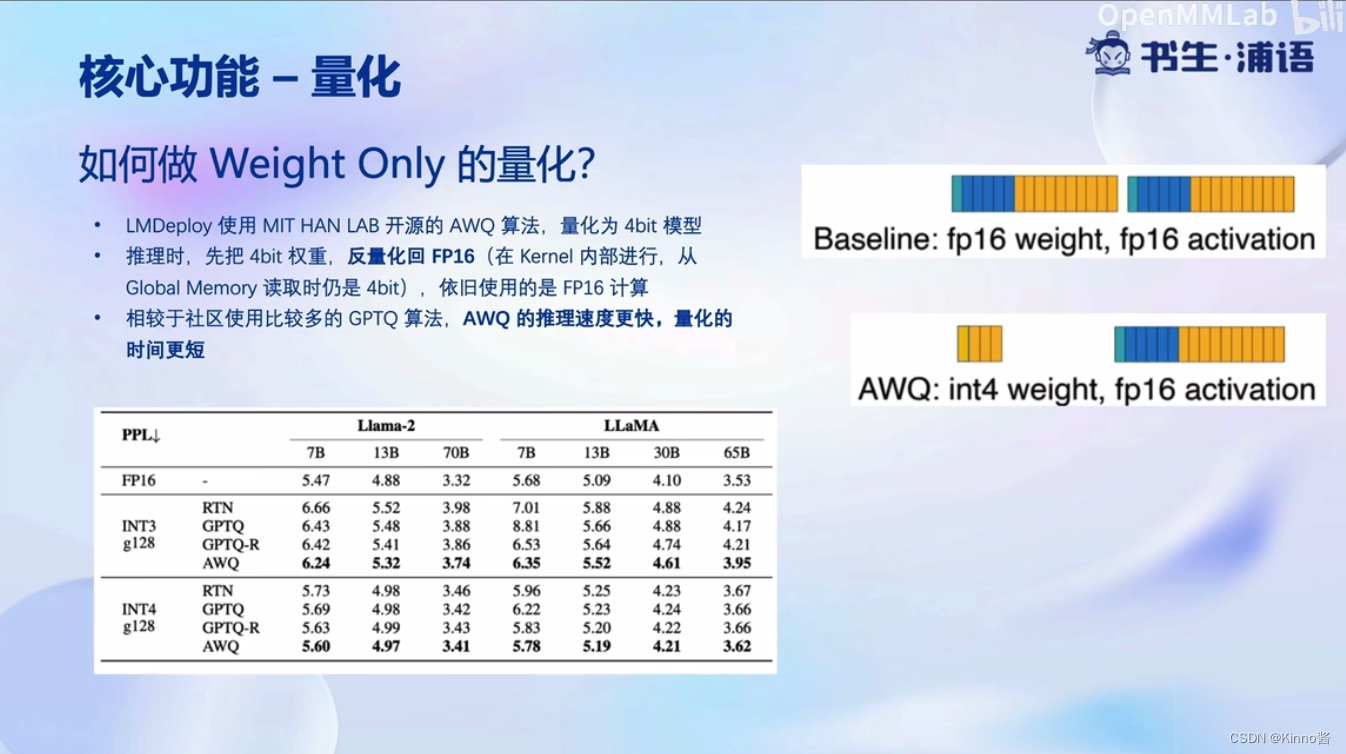
AWQ算法:观察到模型在推理过程中,只有一小部分参数是重要的参数,这部分参数不量化,其他的参数量化,这样保留了显存,性能也不会下降多少
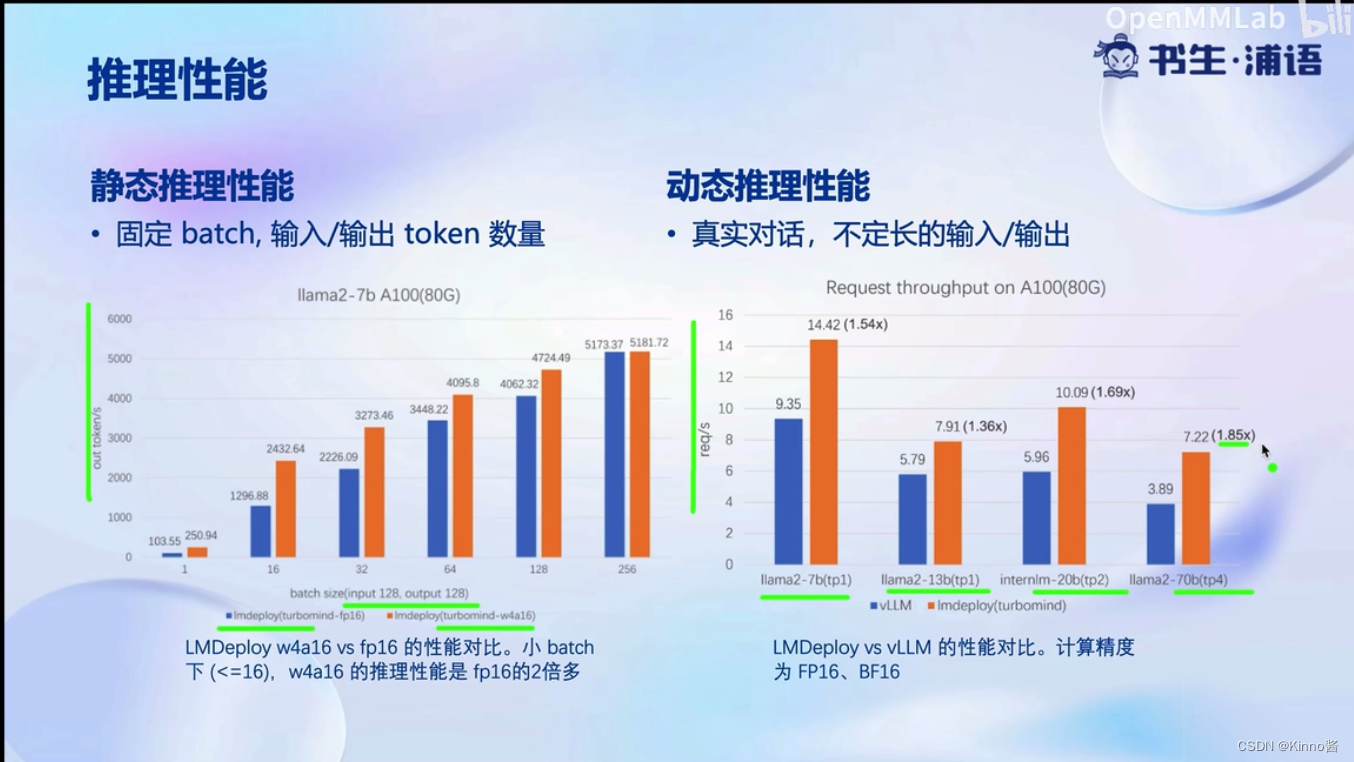
核心功能-推理引擎
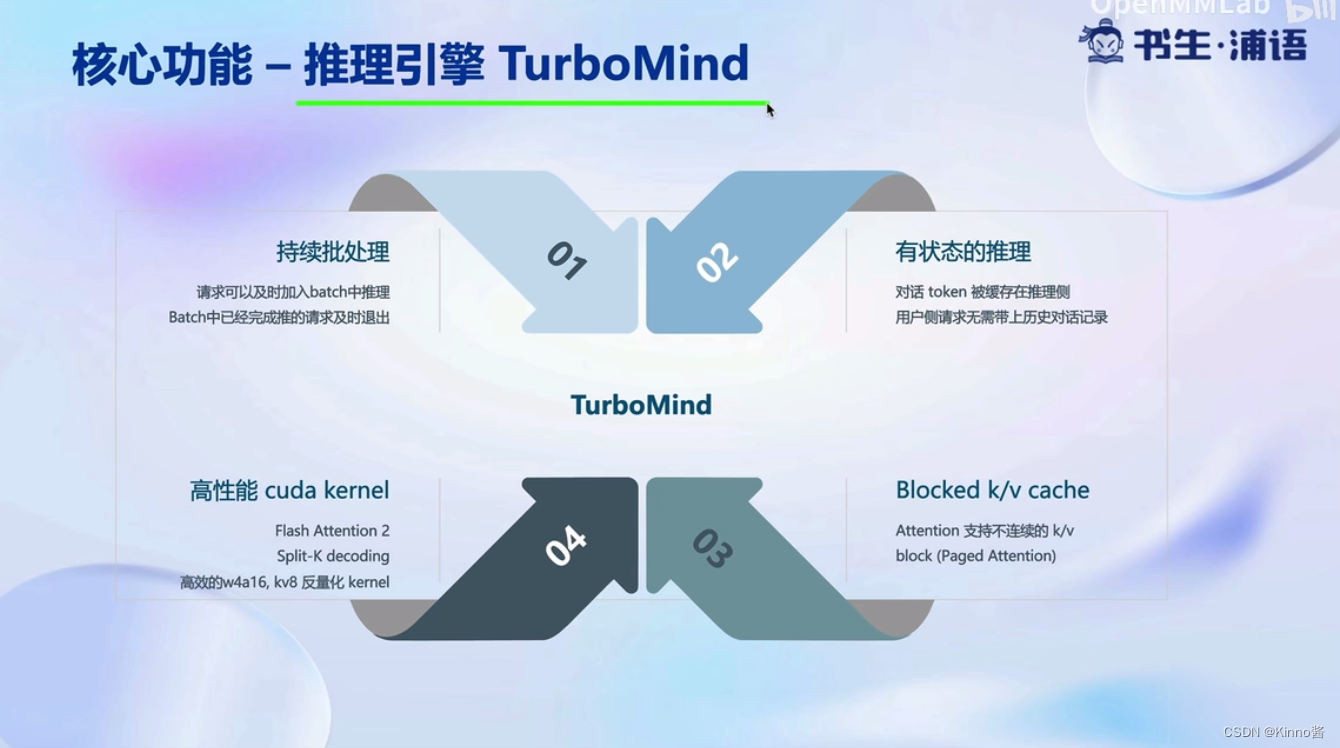
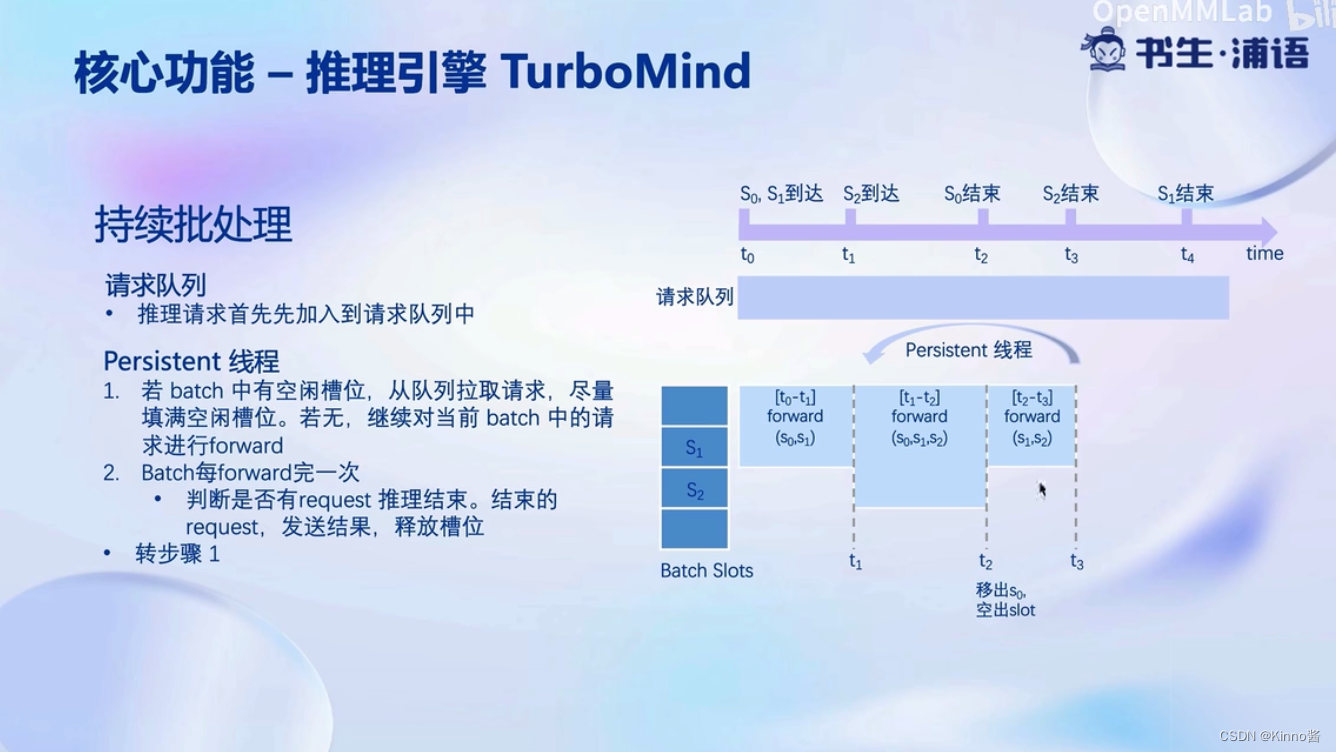
不用等到整个batch结束


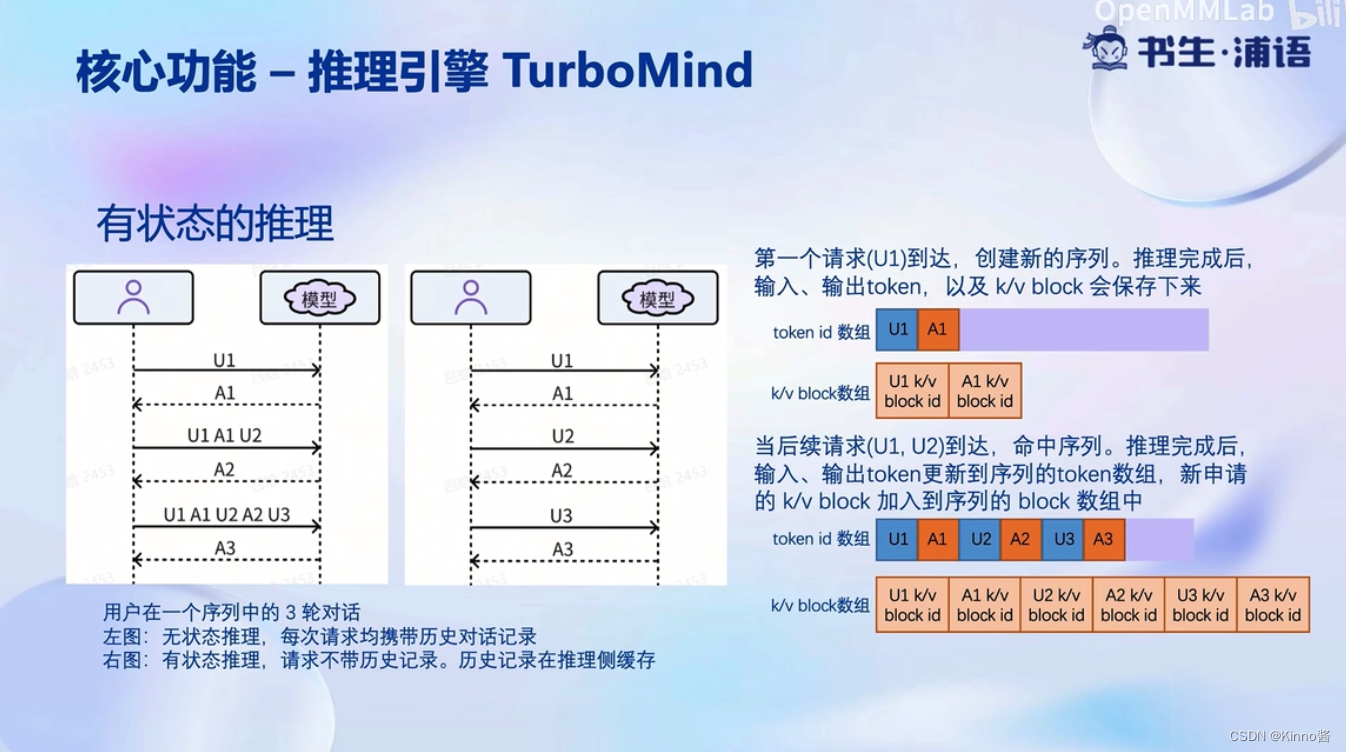
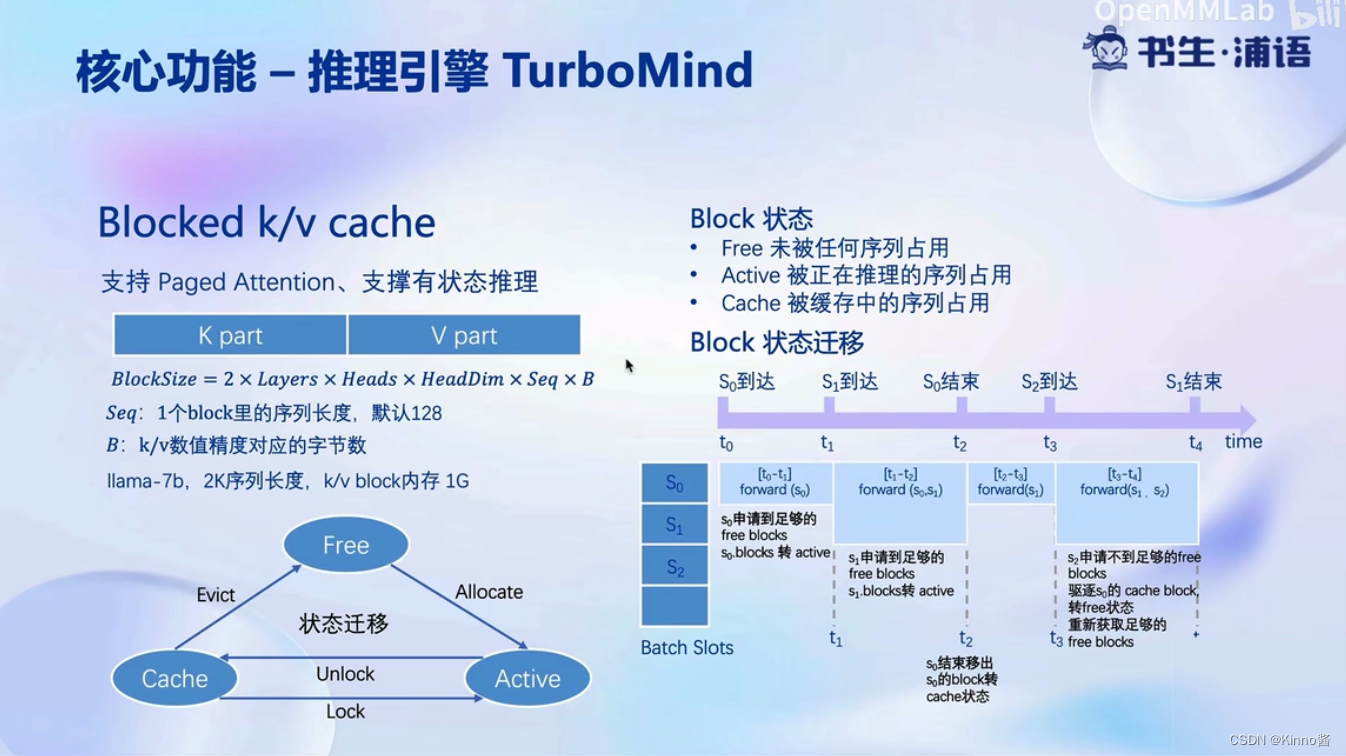
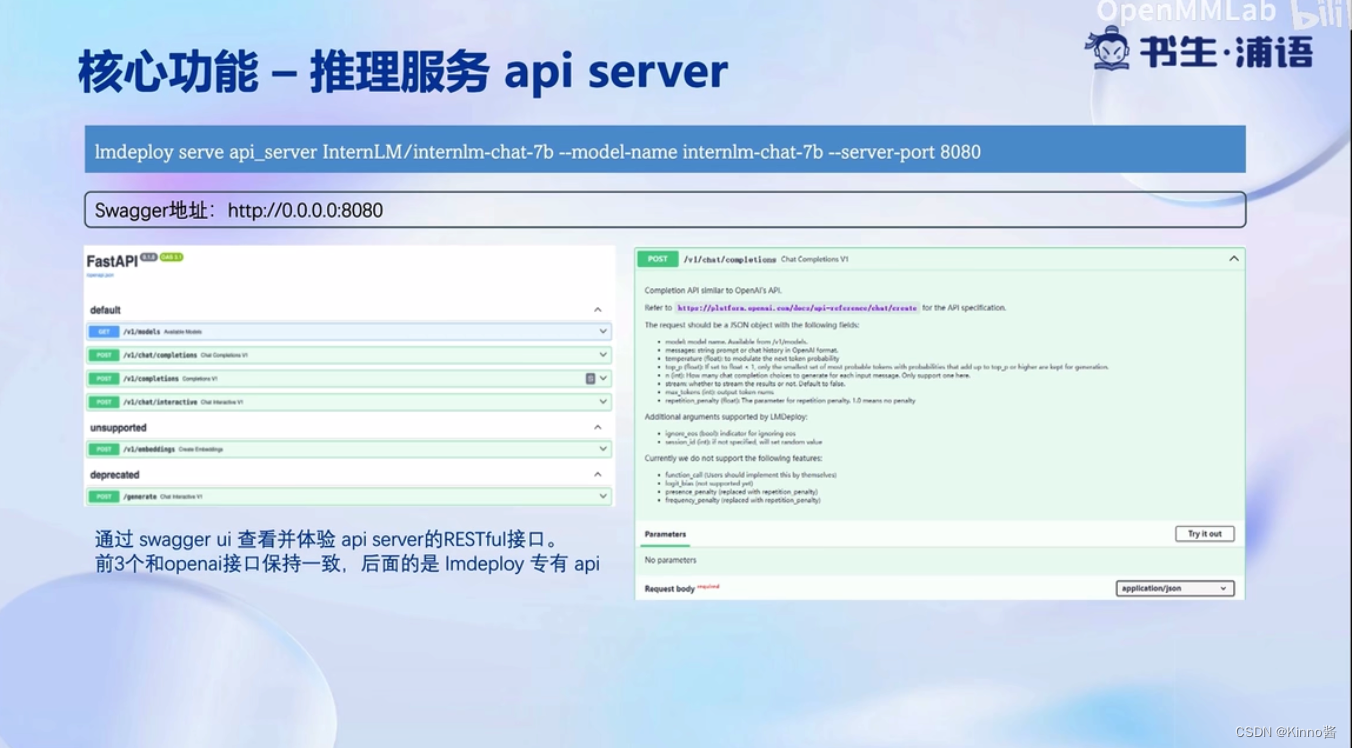
核心功能-推理服务api server
动手实践环节
https://github.com/InternLM/tutorial/blob/main/lmdeploy/lmdeploy.md















 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









