








1.原理

词语向量:
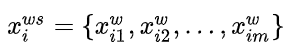
字符向量:
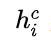
具体步骤:(在此省略dropout)
1.将词向量的维度进行对齐,使其与bert_dim维度一致:[batch_size,max_len,num_words,bert_dim]
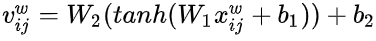
2.计算词语与字符的注意力矩阵:[batch_size,max_len,num_words]
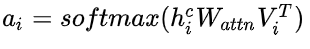
3.将词向量通过注意力矩阵进行加权:[batch_size,max_len,bert_dim]
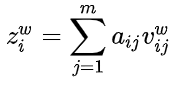
4.将注意力加权后的词向量与bert字符表征相加:[batch_size,max_len,bert_dim]
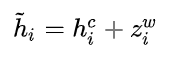
2.小黑代码demo
from transformers.configuration_bert import BertConfig
from transformers import BertPreTrainedModel
from transformers.modeling_bert import BertEmbeddings,BertEncoder,BertPooler,BertLayer,BaseModelOutput,BaseModelOutputWithPooling
from transformers.modeling_bert import BERT_INPUTS_DOCSTRING,_TOKENIZER_FOR_DOC,_CONFIG_FOR_DOC
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import math
import os
import warnings
from dataclasses import dataclass
from typing import Optional,Tuple
import torch.utils.checkpoint
from torch.nn import CrossEntropyLoss,MSELoss
from transformers.file_utils import add_code_sample_docstrings,add_start_docstrings_to_callable
class WordEmbeddingAdapter(nn.Module):
def __init__(self,config):
super(WordEmbeddingAdapter,self).__init__()
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.tanh = nn.Tanh()
self.linear1 = nn.Linear(config.word_embed_dim,config.hidden_size)
self.linear2 = nn.Linear(config.hidden_size,config.hidden_size)
attn_W = torch.zeros(config.hidden_size,config.hidden_size)
self.attn_W = nn.Parameter(attn_W)
self.attn_W.data.normal_(mean = 0.0,std = config.initializer_range)
self.layer_norm = nn.LayerNorm(config.hidden_size,eps = config.layer_norm_eps)
def forward(self,layer_output,word_embeddings,word_mask):
# layer_output:[batch_size,max_len,bert_dim]
# word_embeddings:[batch_size,max_len,num_words,word_dim]
# word_mask:[batch_size,max_len,num_words]
# 对齐词向量与字符向量
# word_outputs:[batch_size,max_len,num_words,bert_dim]
word_outputs = self.linear1(word_embeddings)
word_outputs = self.tanh(word_outputs)
# word_outputs:[batch_size,max_len,num_words,bert_dim]
word_outputs = self.linear2(word_outputs)
word_outputs = self.dropout(word_outputs)
# 计算每个字符向量,与其对应的所有词向量的注意力权重,然后加权求和。采用双线性映射计算注意力权重
# scores:[batch_size,max_len,1,bert_dim]
scores = torch.matmul(layer_output.unsqueeze(2),self.attn_W)
# scores:[batch_size,max_len,1,num_words]
scores = torch.matmul(scores,torch.transpose(word_outputs,2,3))
# scores:[batch_size,max_len,num_words]
scores = scores.squeeze(2)
scores.masked_fill_(word_mask,-1e9)
scores = F.softmax(scores,dim = -1)
# attn:[batch_size,max_len,num_words,1]
attn = scores.unsqueeze(-1)
# weighted_word_embedding:[batch_size,max_len,bert_dim]
weighted_word_embedding = torch.sum(word_outputs * attn,dim = 2)
# layer_output:[batch_size,max_len,bert_dim]
layer_output = layer_output + weighted_word_embedding
layer_output = self.dropout(layer_output)
layer_output = self.layer_norm(layer_output)
return layer_output
pretrain_model_path = 'bert-base-chinese'
config = BertConfig.from_pretrained(pretrain_model_path)
config.word_embed_dim = 200
model = WordEmbeddingAdapter(config)
num_words = 3
max_len = 10
bert_dim = 768
batch_size = 4
layer_output = torch.randn([batch_size,max_len,bert_dim])
word_embeddings = torch.randn([batch_size,max_len,num_words,config.word_embed_dim])
word_mask = torch.ones([batch_size,max_len,num_words]).long()
layer_output = model(layer_output,word_embeddings,word_mask)
print('layer_output.shape:',layer_output.shape)
输出:
layer_output.shape: torch.Size([4, 10, 768])















 5282
5282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









