







1.量化简介
模型量化(Model Quantization)是深度学习中一种优化技术,旨在减少模型的计算和存储需求,同时尽量保持模型的性能。具体来说,模型量化通过将模型的权重和激活值从高精度(通常是32位浮点数)缩减到较低精度(如16位、8位甚至更低的整数),从而减少计算复杂度和内存占用
模型量化具有以下优点:
- 减少存储需求:低精度表示可以显著减少模型的存储空间。
- 加速推理速度:低精度计算通常比高精度计算更快,特别是在支持低精度运算的硬件上。
- 降低功耗:减少计算复杂度和内存访问次数,可以降低功耗,这对于移动和嵌入式设备尤为重要。
2.概念介绍
- 按量化参数分类,可分为静态量化和动态量化,区别这两种方式主要是是否提供校准集,动态量化更简单,更灵活,但是推理开销较大,会内嵌一些动态参数,特别注意,动态量化对于TensorRT的engine生成较复杂,因为TensorRT不支持DynamicQuantizeLinear操作。
- 按量化时间分类,可分为训练后量化(PTQ)和量化感知训练(QAT),区别这两种方式主要是是否需要对模型进行训练,也就是需要搭配troch、tensorflow等框架来训练模型,QAT方式更加复杂,精度也更高,常规的使用建议直接采用PTQ方式,待PTQ量化模型性能较差,再采用QAT方式进行优化。
2.1 动态量化(Dynamic Quantization)(量化方式)
描述:
- 动态量化在模型推理时对部分权重和激活值进行量化。具体来说,模型的权重在推理前保持为浮点数,在推理时将其动态转换为低精度(如8位整数)进行计算。激活值在推理过程中也会动态地从浮点数转换为低精度值。
优点:
- 简便性:无需校准数据集,适用于推理阶段的快速量化。
- 灵活性:适用于多种模型和场景,不需要重新训练模型。
缺点:
- 推理开销:在推理过程中进行动态量化,可能增加一些计算开销。
- 精度损失:虽然动态量化可以减少一些精度损失,但在某些情况下仍可能影响模型性能。
2.2. 静态量化(Static Quantization)(量化方式)
描述:
- 静态量化的目标是求取量化比例因子,主要通过对称量化、非对称量化方式来求,而找到最大值或阈值的方法有MinMax、KLD、ADMM、EQ等方法。
优点:
- 高效推理:预先量化的模型在推理时效率更高,无需额外的动态计算。
- 较好的精度:通过校准数据集可以较好地保持模型精度。
缺点:
- 需要校准数据集:需要一个代表性的校准数据集来计算量化参数。
- 实施复杂:量化过程可能较为复杂,需要对模型进行详细的分析和调整。
2.3. 量化感知训练(Quantization-Aware Training, QAT)(量化时间,通过结合静态量化)
描述:
- 量化感知训练(QAT)是一种在模型训练过程中引入量化操作的技术。通过在训练阶段模拟量化误差,模型能够学习并适应量化带来的精度损失,从而在量化后依然保持较高的准确性。QAT通常结合静态量化方法,在训练时将权重和激活值量化为低精度(如8位整数),并在反向传播时考虑量化误差。
优点:
- 最小化精度损失:在训练过程中模拟量化误差,使模型适应量化后的精度损失,通常能保持较高的准确性。
- 高效推理:量化后的模型在推理时效率很高。
缺点:
- 训练复杂度增加:需要在训练过程中引入量化感知机制,增加训练复杂度和时间。
- 计算资源需求高:训练过程需要更多的计算资源和时间。
2.4.后训练量化(Post-Training Quantization, PTQ)
描述:
- 在模型训练完成后进行量化,不需要重新训练模型。
- KL散度方法:通过计算原Float32与量化后的参数分布,得到最优
优点:
- 简单快速,适合快速部署。
缺点:
- 可能会有一定的精度损失,尤其是在量化敏感的模型中。
2.5 总结
- 动态量化适合需要快速部署和灵活应用的场景,但在推理时可能增加计算开销。
- 静态量化适合推理效率要求高的场景,但需要校准数据集和复杂的量化过程。
- 后训练量化适合已经训练好的模型,希望快速量化以便部署的场景,但可能会导致精度下降。
- 量化感知训练适合对精度要求高的场景,但增加了训练复杂度和资源需求。
3. QAT与PTQ区别
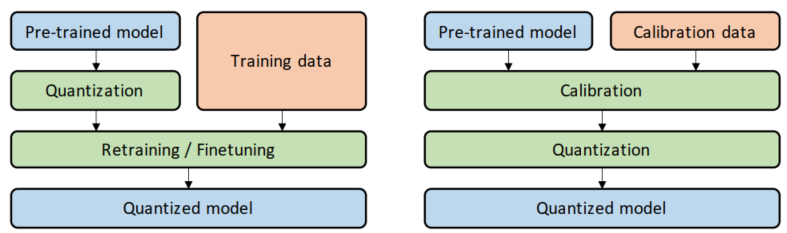
- 训练中量化:QAT,精度高,复杂;训练后量化:PTQ,精度略低,简单。
- 训练后量化 PTQ :它是使用一批校准数据对训练好的模型进行校准, 将训练过的FP32网络直接转换为定点计算的网络,过程中无需对原始模型进行任何训练。只对几个超参数调整就可完成量化过程, 且过程简单快速, 无需训练, 因此此方法已被广泛应用于大量的端侧和云侧部署场景, 优先推荐您尝试PTQ方法来查看是否满足您的部署精度和性能要求 。
- 量化感知训练 QAT :它是将训练过的模型量化后又再进行重训练。由于定点数值无法用于反向梯度计算,实际操作过程是在某些op前插入伪量化节点(fake quantization nodes), 用于在训练时获取流经该op的数据的截断值,便于在部署量化模型时对节点进行量化时使用。我们需要在训练中通过不断优化精度来获取最佳的量化参数。由于它需要对模型进行训练, 对操作人员技术要求较高。
4. QAT/PTQ量化与静态/动态量化的区别
PTQ(Post-Training Quantization,训练后量化)和QAT(Quantization-Aware Training,量化感知训练)主要是量化方法,而静态量化和动态量化是量化策略。
训练后量化(PTQ)
描述
PTQ是在模型训练完成后,对模型进行量化的一种方法。它不需要在训练过程中考虑量化误差,而是在训练结束后,通过分析训练数据或校准数据,对模型的权重和激活值进行量化。
静态量化 vs 动态量化
- 静态量化:PTQ可以用于静态量化,即在量化时使用一组校准数据来确定量化参数(如缩放因子和零点),并在推理时使用这些预先计算的量化参数。
- 动态量化:PTQ也可以用于动态量化,即在推理时根据输入数据动态地确定量化参数。这种方法通常用于激活值的量化,而权重通常在量化后保持静态。
量化感知训练(QAT)
描述
QAT是在训练过程中引入量化操作的一种方法。通过在训练阶段模拟量化误差,模型能够学习并适应量化带来的精度损失,从而在量化后依然保持较高的准确性。
静态量化 vs 动态量化
- 静态量化:QAT通常用于静态量化,即在训练过程中模拟量化误差,并在训练完成后使用固定的量化参数进行推理。由于模型已经适应了这些量化参数,推理时可以直接使用预先计算的量化参数,达到高效推理的效果。
- 动态量化:QAT一般不用于动态量化,因为动态量化主要是在推理时动态确定量化参数,而QAT的核心在于训练过程中模拟和适应量化误差。
总结
- PTQ:可以用于静态量化和动态量化。静态量化使用预先计算的量化参数,动态量化在推理时动态确定量化参数。
- QAT:主要用于静态量化,通过在训练过程中模拟量化误差,使模型适应固定的量化参数,从而在推理时达到高效和高精度的效果。
详细可参考下面资料进行深入学习:
















 1382
1382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











