







一棵决策树包含一个根结点,若干个内部结点和若干个叶结点。叶结点对应于决策结果,其他每个结点则对应于一个属性测试。
每个结点包含的样本集合根据属性测试的节点被划分到子结点中。根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定测试序列。决策树学习的目的是为了产生一棵泛化能力强的决策树,其基本流程遵循简单的分治策略。

决策树的生成是一个递归的过程,三种情况会导致递归返回
1.当前结点包含的样本全属于同一类别,无需划分;
2.当前属性集为空,或者所有样本在所有属性上取值相同,无法划分;
3.当前结点包含的样本集合为空,不能划分
情况2我们把当前结点标记为叶节点,并将其设定为该结点所含样本最多的类别;情况3同样把当前结点标记为叶节点,但将其类别设定为其父节点所含样本最多的类别。
情况2是利用当前结点的后验分布,情况3则是把父节点的样本分布作为当前结点的先验分布。
决策树的关键是如何选择最优划分属性。随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别。
信息熵是度量样本集合纯度最常用的一种指标。假定当前样本集合D中第k类样本所占的比例为pk,D的信息熵定义为
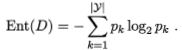
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









