







一、算法流程:

决策树的生成是个递归的过程,显然能发现三种导致递归返回的情况:
1、当前节点所包含的样本全部属于同一类,无需划分 。这时将结点化为叶子结点,样本属于该类别。
2、属性集为空或者数据集在当前属性集上所有取值相同,无法划分 。这时将结点化为叶子结点并将样本归属于多数类。
3、当前节点所包含的样本集合为空,不能划分。这时将结点化为叶子结点并将样本归属于父节点的多数类。
二、划分选择
信息熵:
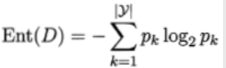
1.信息增益:
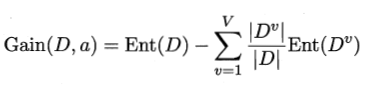
例题:根据西瓜数据集建立决策树。


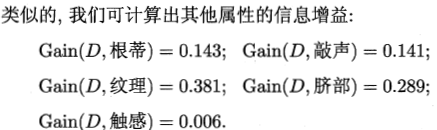
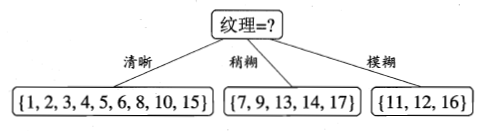
然后分别对剩下的五个属性按照此方法计算,得到最终如下的决策树:

2.C4.5——增益率
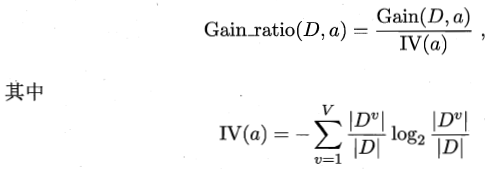
3.CART 基尼系数
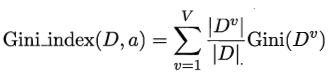
其中,
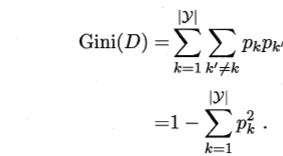
三、剪枝处理
1.预剪枝

预剪枝控制了决策树的生长,可以按照上图的方法进行(测试样本的分类错误率最小时停止),也可以通过设定信息增益阈值或者通过信息增益的统计显著性分析来进行。降低了过拟合的风险并显著减少了决策树的训练时间开销和测试时间开销。但是,由于缺乏全局观念,预剪枝可能导致欠拟合。
2.后剪枝

后剪枝欠拟合风险很小,泛化能力高于预剪枝决策树,但训练时间开销比未剪枝决策树和预剪枝决策树要大得多。
四、选择最佳划分的度量
对于离散属性,直接采用前面所述的信息增益、C4.5、CART方法构造决策树即可。但是,对于连续属性,我们可以采用二分法对连续属性进行处理:
1.给定样本集D上连续属性a的n个不同取值,按从小到大排序;
2.对连续属性求出可能的n-1个划分点集合T;
3.对T中的每个划分点计算对应的信息增益;
4.取使信息增益最大的划分点为真实的划分点
例题:对“密度”和“含糖率”属性进行划分。


对于缺失值,我们先忽略其缺失性,最终信息增益乘上一个缩放因子即可。
例题:对西瓜数据集构造决策树。



五、随机森林
1.对样本数据进行自举重采样,得到多个样本集;
2.用每个重采样样本集作为训练样本构造一个决策树;
3.得到所需数目的决策树后,代入测试样本对这些树的输出进行投票,以得票最多的类作为随机森林的决策。
补充:斜决策树

代码演示:
>>> from sklearn.datasets import load_iris
>>> from sklearn import tree
>>> X, y = load_iris(return_X_y=True)
>>> clf = tree.DecisionTreeClassifier()
>>> clf = clf.fit(X, y)
>>> tree.plot_tree(clf) 
>>> from sklearn.datasets import load_iris
>>> from sklearn.tree import DecisionTreeClassifier
>>> from sklearn.tree import export_text
>>> iris = load_iris()
>>> decision_tree = DecisionTreeClassifier(random_state=0, max_depth=2)
>>> decision_tree = decision_tree.fit(iris.data, iris.target)
>>> r = export_text(decision_tree, feature_names=iris['feature_names'])
>>> print(r)
|--- petal width (cm) <= 0.80
| |--- class: 0
|--- petal width (cm) > 0.80
| |--- petal width (cm) <= 1.75
| | |--- class: 1
| |--- petal width (cm) > 1.75
| | |--- class: 2














 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









