







CSDN:https://blog.csdn.net/Roaddd/article/details/114646354
论文:https://arxiv.org/pdf/1807.06521.pdf
【CBAM(Convolutional Block Attention Module)】
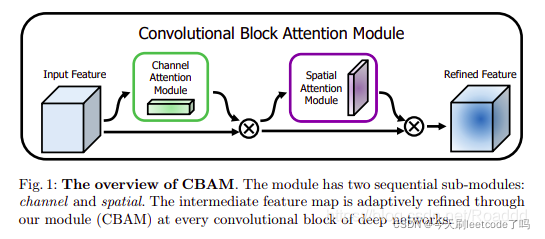
可以看到 CBAM 包含2个独立的子模块, 通道注意力模块(Channel Attention Module,CAM) 和空间注意力模块(Spartial Attention Module,SAM) ,分别进行通道与空间上的 Attention 。
这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
通道上的 Attention 机制在 2017 年的 SENet 就被提出,SENet可以参考我的这篇文章 https://blog.csdn.net/Roaddd/article/details/111357490。
事实上,CAM 与 SENet 相比,只是多了一个并行的 Max Pooling 层。至于为何如此更改,论文也给出了解释和实验数据支持。
1、Channel Attention Module(CAM)
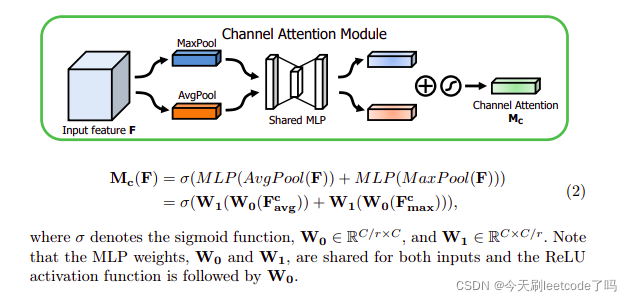
将输入的特征图F(H×W×C)分别经过基于width和height的global max pooling(全局最大池化)和global average pooling(全局平均池化),得到两个1×1×C的特征图。
接着,再将它们分别送入一个两层的神经网络(MLP),第一层神经元个数为 C/r(r为减少率),激活函数为 Relu,第二层神经元个数为 C,这个两层的神经网络是共享的。
而后,将MLP输出的特征进行基于element-wise的加和操作,再经过sigmoid激活操作,生成最终的channel attention feature,即M_c。
最后,将M_c和输入特征图F做element-wise乘法操作,生成Spatial attention模块需要的输入特征。
2、Spatial Attention Module(SAM)
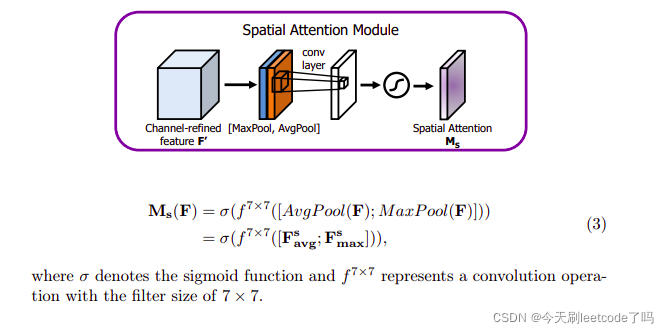
将Channel attention模块输出的特征图F‘作为本模块的输入特征图。
首先做一个基于channel的global max pooling 和global average pooling,得到两个H×W×1 的特征图,然后将这2个特征图基于channel 做concat操作(通道拼接)。
然后经过一个7×7卷积(7×7比3×3效果要好)操作,降维为1个channel,即H×W×1。
再经过sigmoid生成spatial attention feature,即M_s。
最后将该feature和该模块的输入feature做乘法,得到最终生成的特征。
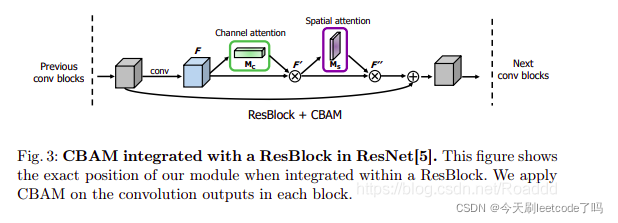
3、CBAM和ResBlock组合
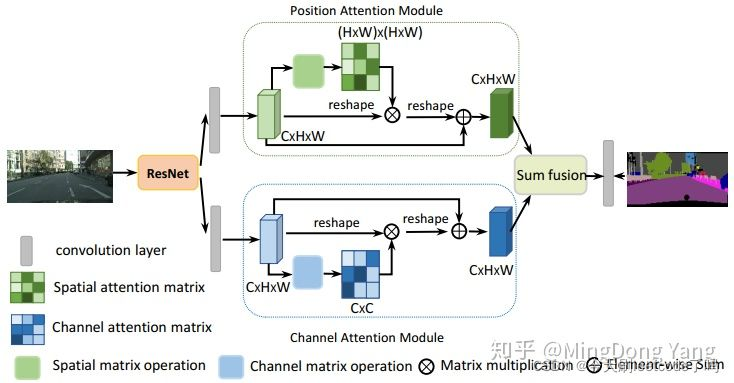
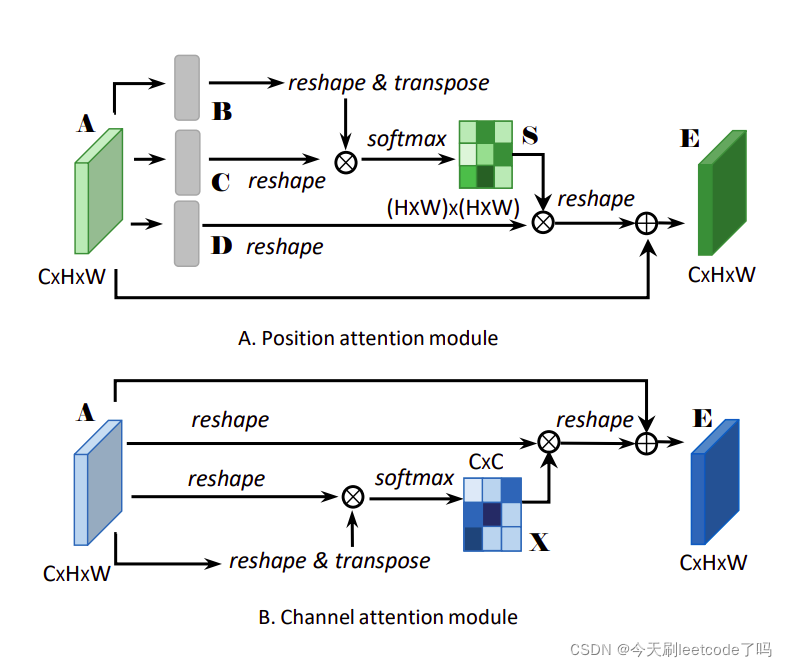
【Dual Attention Network for Scene Segmentation】
知乎:https://zhuanlan.zhihu.com/p/48056789
CSDN:https://blog.csdn.net/mieleizhi0522/article/details/83111183
代码(torch):https://github.com/junfu1115/DANet
论文:https://arxiv.org/pdf/1809.02983.pdf
【Rotate to Attend: Convolutional Triplet Attention Module】
CSDN:https://blog.csdn.net/weixin_39858245/article/details/111392537
论文:https://arxiv.org/pdf/2010.03045.pdf
代码:https://github.com/landskape-ai/triplet-attention

















 20万+
20万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









