







 这篇博客详细介绍了深度学习的基础知识,包括范数、MP神经元和万有逼近定理。通过从零开始实现线性回归,讨论了数据集生成、模型参数初始化、损失函数和优化算法。接着,博主通过螺旋数据分类实例展示了线性模型的局限性和激活函数的重要性,探讨了几种常见的激活函数。最后,总结了模型训练的关键因素:训练数据、损失函数、优化算法和模型结构。
这篇博客详细介绍了深度学习的基础知识,包括范数、MP神经元和万有逼近定理。通过从零开始实现线性回归,讨论了数据集生成、模型参数初始化、损失函数和优化算法。接着,博主通过螺旋数据分类实例展示了线性模型的局限性和激活函数的重要性,探讨了几种常见的激活函数。最后,总结了模型训练的关键因素:训练数据、损失函数、优化算法和模型结构。
目录
3.螺旋数据分类(spiral classification)
构建线性模型分类
1.理论部分
范数
范数定义了向量空间里的距离,它的出现使得向量之间的比较成为了可能。
简单理解:范数可以把一组实数列表,映射成一个实数。
L1范数,也叫曼哈顿距离:是一个向量中所有元素的绝对值之和。
L2范数,也叫欧几里得范数:是一个向量中所有元素取平方和,然后再开平方。pytorch中的norm()为L2范数。
在深度学习中,我们经常试图解决优化问题:最⼤化分配给观测数据的概率; 最⼩化预测和真实观测之间的 距离。⽤向量表⽰物品(如单词、产品或新闻⽂章),以便最⼩化相似项⽬之间的距离,最⼤化不同项⽬之间 的距离。⽬标,或许是深度学习算法最重要的组成部分(除了数据),通常被表达为范数。
MP神经元
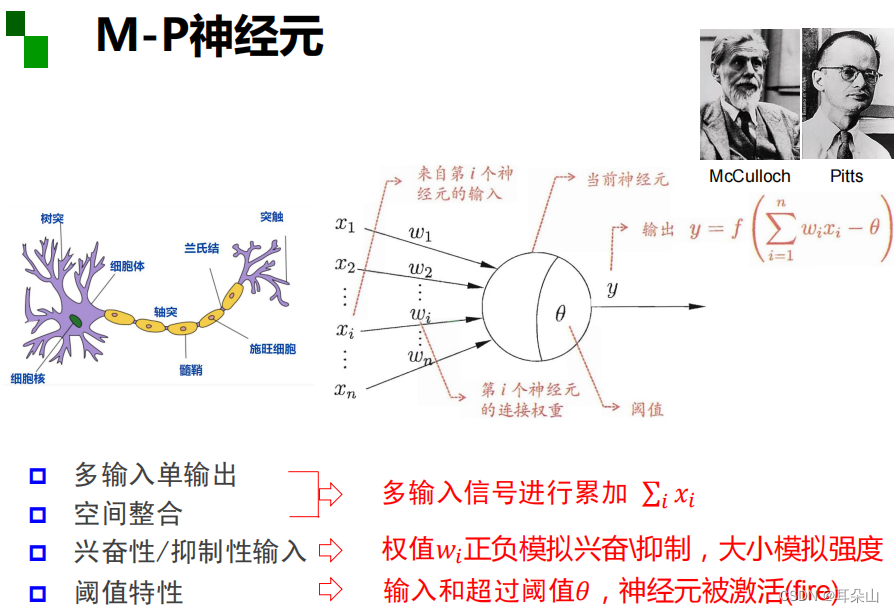
万有逼近定理
如果一个隐层包含足够多的神经元,三层前馈神经网络(输入-隐层-输出)能以任意精度逼近任意预定的连续函数。
当隐层足够宽时,双隐层感知器(输入-隐层1-隐层2-输出)可以逼近任意非连续函数:可以解决任何复杂的分类问题。
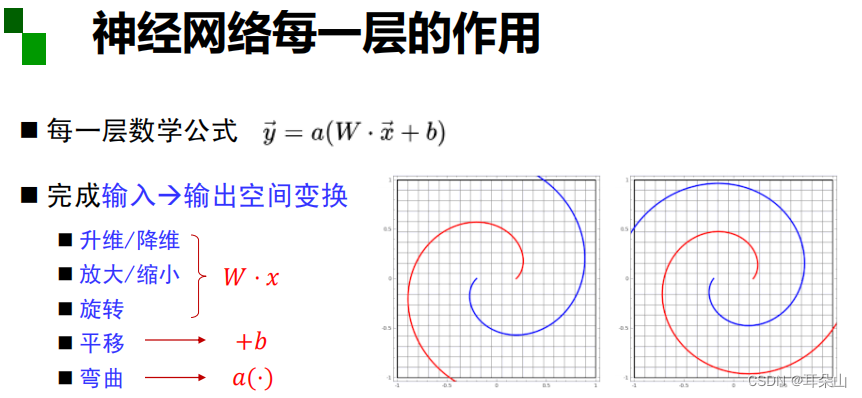
神经网络中每一层的作用
2.线性回归的从零开始实现
%matplotlib inline
#使用%matplotlib命令可以将matplotlib的图表直接嵌入到Notebook之中
#或者使用指定的界面库显示图表,它有一个参数指定matplotlib图表的显示方式
#inline表示将图表嵌入到Notebook中。
import random
import torch
from d2l import torch as d2l生成数据集
为了简单起见,我们将根据带有噪声的线性模型构造一个人造数据集。 我们的任务是使用这个有限样本的数据集来恢复这个模型的参数。 我们将使用低维数据,这样可以很容易地将其可视化。 在下面的代码中,我们生成一个包含1000个样本的数据集, 每个样本包含从标准正态分布中采样的2个特征。 我们的合成数据集是一个矩阵
。
我们使用线性模型参数 和噪声项
生成数据集及其标签:
你可以将ϵ视为模型预测和标签时的潜在观测误差。 在这里我们认为标准假设成立,即ϵ服从均值为0的正态分布。 为了简化问题,我们将标准差设为0.01。 下面的代码生成合成数据集。
def synthetic_data(w, b, num_examples):
"""生成y=Xw+b+噪声"""
#
X = torch.normal(0, 1, (num_examples, len(w)))
# y = X * w + b
y = torch.matmul(X, w) + b
# 再补上一个满足标准差为0.01,均值为0的正态分布的噪声
y += torch.normal(0, 0.01, y.shape)
#若原来的向量的y.shape为(a,b)
#reshape(-1,m)中, 改变维度为d行m列,其中-1表示行数自动计算,行数 = a*b/m
return X, y.reshape((-1, 1))
#真实值w
true_w = torch.tensor([2, -3.4])
#真实值b
true_b = 4.2
#生成1000组样本 其中features对应X , labels对应y
#features中的每一行都包含一个二维数据样本,
#labels中的每一行都包含一维标签值(一个标量)
features, labels = synthetic_data(true_w, true_b, 1000)
读取数据集
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









