






Vision Transformer
原论文地址:An Image Is Worth 16x16 Words: Transformers For Image Recognition At Scale
源码地址:GitHub - google-research/vision_transformer
本段参考博文:Vision Transformer详解_太阳花的小绿豆的博客-CSDN博客
Transformer最初提出是针对NLP领域的,并且在NLP领域大获成功。这篇论文也是受到其启发,尝试将Transformer应用到CV领域,并且ImageNet数据集上取得不错的效果。
下图是原论文中给出的关于Vision Transformer(ViT)的模型框架。简单而言,模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)
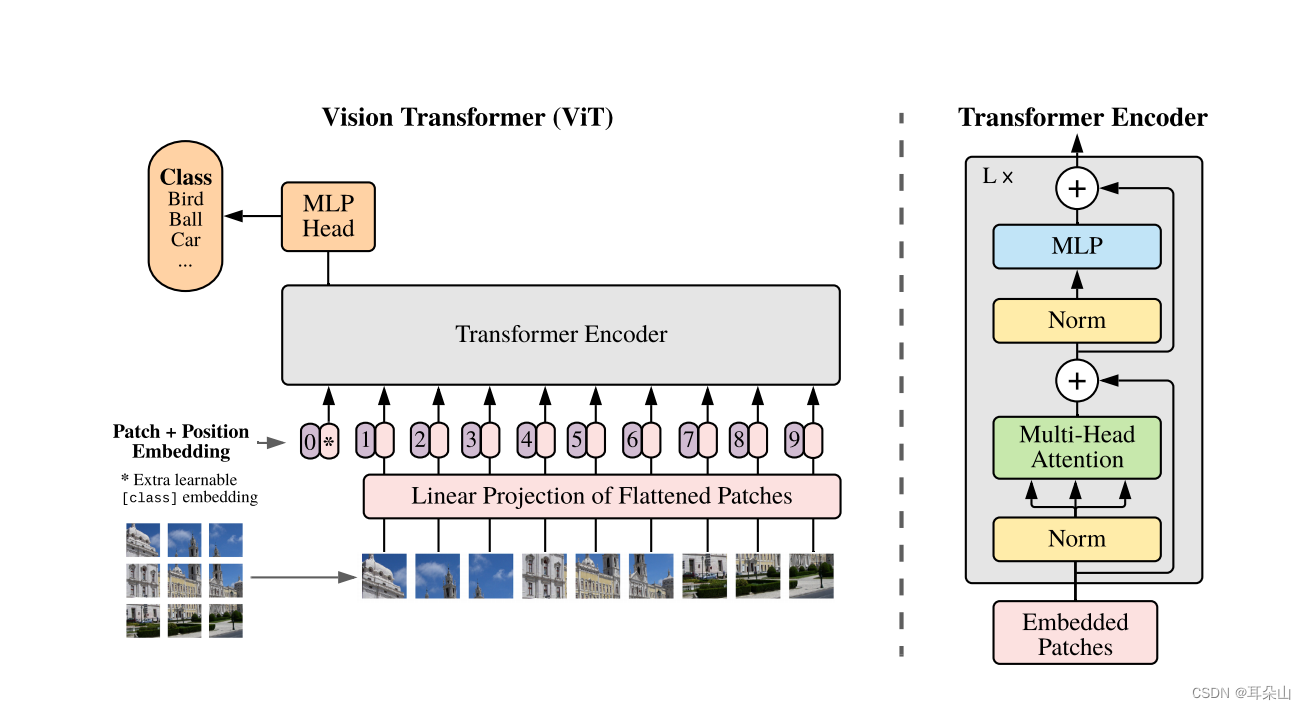
Embedding层结构详解
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim],以ViT-B/16为例,每个token向量长度为768。
对于图像数据而言,其数据格式为[H, W, C]是三维矩阵,所以需要先通过一个Embedding层来对数据做个变换。如下图所示,首先将一张图片按给定大小分成一堆Patches。以ViT-B/16为例,将输入图片(224 x 224)按照16 x 16大小的Patch进行划分,划分后会得到( 224 / 16 ) 2 = 196个Patches。接着通过线性映射将每个Patch映射到一维向量中,以ViT-B/16为例,每个Patche数据shape为[16, 16, 3]通过映射得到一个长度为768的向量(后面都直接称为token)

在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。 作者说参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,然后关于Position Embedding就是之前Transformer中讲到的Positional Encoding,这里的Position Embedding采用的是一个可训练的参数,是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。

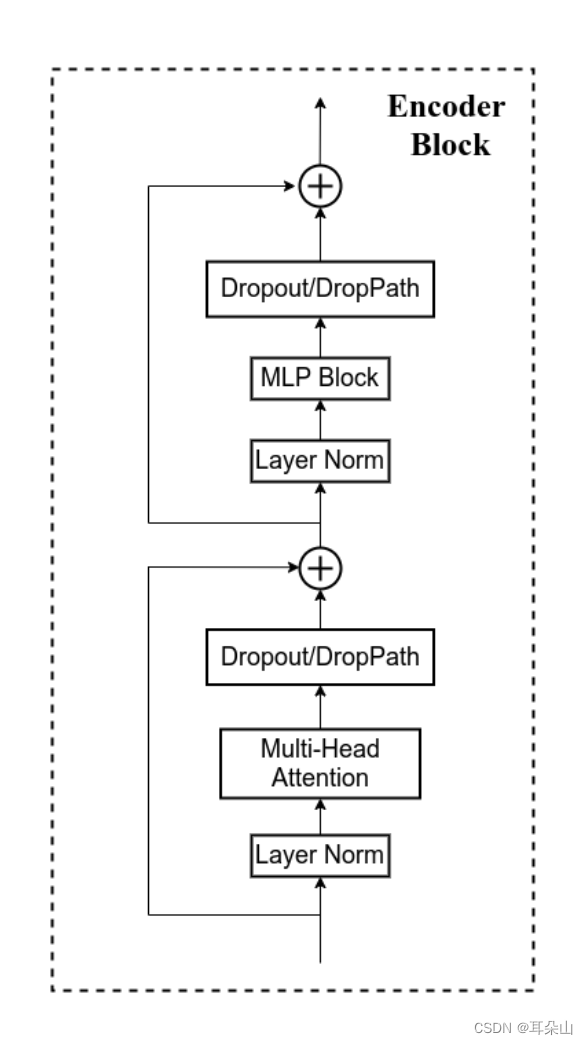
Transformer Encoder详解
Transformer Encoder其实就是重复堆叠Encoder Block L次,主要由以下几部分组成:
- Layer Norm,这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理。
- Multi-Head Attention
- Dropout/DropPath
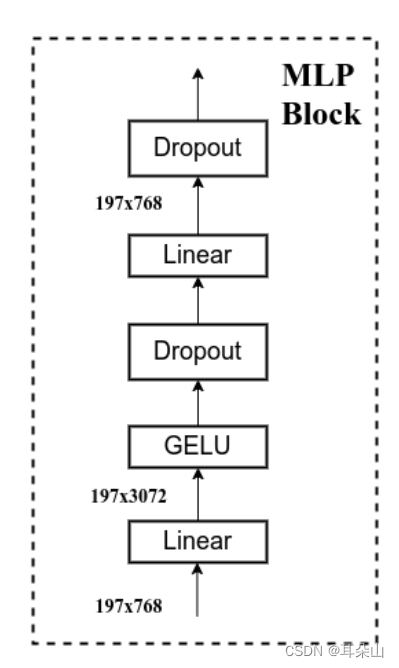
- MLP Block,如图右侧所示,就是全连接 + GELU激活函数 + Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
MLP Head详解
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。注意,在Transformer Encoder后其实还有一个Layer Norm没有画出来,这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。
Swin Transformer
原论文地址:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
本段参考博文:Swin-Transformer网络结构详解_太阳花的小绿豆的博客-CSDN博客_transformer网络结构
目前Transformer应用到图像领域主要有两大挑战:
- 视觉实体变化大,在不同场景下视觉Transformer性能未必很好
- 图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大
针对上述两个问题,我们提出了一种包含滑窗操作,具有层级设计的Swin Transformer。
其中滑窗操作包括不重叠的local window,和重叠的cross-window。将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量。
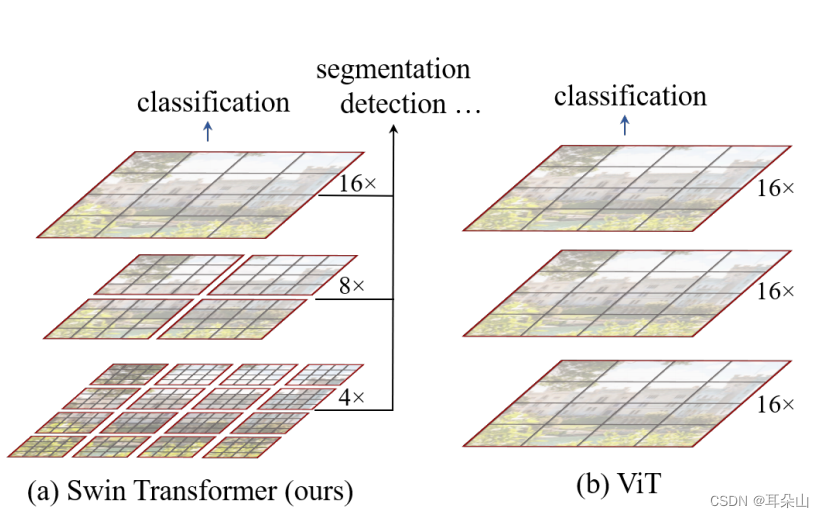
以下两图是Swin-T与Vit的对比,我们可以从中至少看出两点不同:
- Swin Transformer使用了类似卷积神经网络中的层次化构建方法(Hierarchical feature maps),比如特征图尺寸中有对图像下采样4倍的,8倍的以及16倍的,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而在之前的Vision Transformer中是一开始就直接下采样16倍,后面的特征图也是维持这个下采样率不变。
- 在Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在下图的4倍下采样和8倍下采样中,将特征图划分成了多个不相交的区域(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。相对于Vision Transformer中直接对整个(Global)特征图进行Multi-Head Self-Attention,这样做的目的是能够减少计算量的,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量但也会隔绝不同窗口之间的信息传递,所以在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递。
Swin-T的网络架构:

整个模型采取层次化的设计,一共包含4个Stage,每个stage都会缩小输入特征图的分辨率,像CNN一样逐层扩大感受野,通过图片我们可以看出整个网络框架的基本流程如下:
- 在输入开始的时候,做了一个
Patch Embedding,将图片切成一个个图块,并嵌入到Embedding。 - 在每个Stage里,由
Patch Merging和多个 Block 组成,Block主要由LayerNorm,MLP,Window Attention和Shifted Window Attention组成。 - 其中
Patch Merging模块主要在每个 Stage 开始时降低图片分辨率。 - 最后对于分类网络,后面还会接上一个Layer Norm层、全局池化层以及全连接层得到最终输出。
Patch Embedding
在输入进Block前,我们需要将图片切成一个个patch,然后嵌入向量。
具体做法是对原始图片裁成一个个 patch_size * patch_size的窗口大小,然后进行嵌入。
这里可以通过二维卷积层,将stride,kernelsize设置为patch_size大小。设定输出通道来确定嵌入向量的大小。最后将H,W维度展开,并移动到第一维度
Patch Merging
该模块的作用是在每个Stage开始前做降采样,用于缩小分辨率,调整通道数 进而形成层次化的设计,同时也能节省一定运算量。
在CNN中,则是在每个Stage开始前用
stride=2的卷积/池化层来降低分辨率。
每次降采样是两倍,因此在行方向和列方向上,间隔2选取元素。
然后拼接在一起作为一整个张量,最后展开。此时通道维度会变成原先的4倍(因为H,W各缩小2倍),此时再通过一个全连接层再调整通道维度为原来的两倍
Window Attention
这是这篇文章的关键。传统的Transformer都是基于全局来计算注意力的,因此计算复杂度十分高。而Swin Transformer则将注意力的计算限制在每个窗口内,进而减少了计算量。
我们先简单看下公式
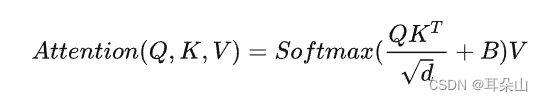
主要区别是在原始计算Attention的公式中的Q,K时加入了相对位置编码。后续实验有证明相对位置编码的加入提升了模型性能。
Shifted Window Attention
前面的Window Attention是在每个窗口下计算注意力的,为了更好的和其他window进行信息交互,Swin Transformer还引入了shifted window操作。
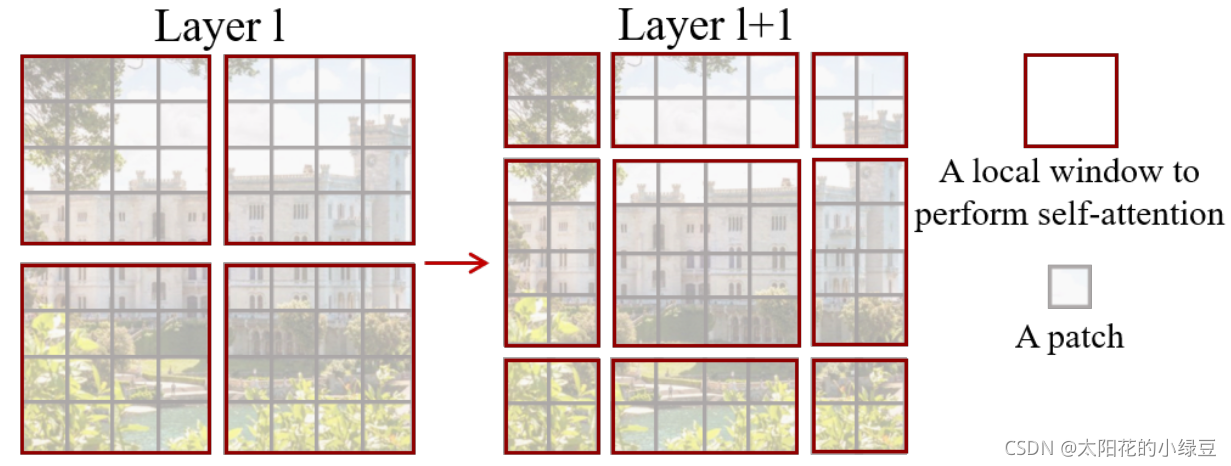
左边是没有重叠的Window Attention,而右边则是将窗口进行移位的Shift Window Attention。可以看到移位后的窗口包含了原本相邻窗口的元素。但这也引入了一个新问题,即window的个数翻倍了,由原本四个窗口变成了9个窗口。
在实际代码里,我们是通过对特征图移位,并给Attention设置mask来间接实现的。能在保持原有的window个数下,最后的计算结果等价。
感想
多阅读优秀的模型论文,多借鉴优秀模型的巧妙trick,才能有自己的idea















 5359
5359











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









