







 本文深入探讨了ShuffleNet V1和V2的设计原理,包括Channel Shuffle和Group Convolution,以及内存访问成本(MAC)对模型效率的影响。同时,介绍了EfficientNet V1和V2的模型缩放策略和结构改进,强调了平衡宽度、深度和分辨率的重要性。此外,还简要提及了Transformer中的multi-head self-attention机制在自然语言处理中的应用。
本文深入探讨了ShuffleNet V1和V2的设计原理,包括Channel Shuffle和Group Convolution,以及内存访问成本(MAC)对模型效率的影响。同时,介绍了EfficientNet V1和V2的模型缩放策略和结构改进,强调了平衡宽度、深度和分辨率的重要性。此外,还简要提及了Transformer中的multi-head self-attention机制在自然语言处理中的应用。
ShuffleNet V1
原论文链接:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices。
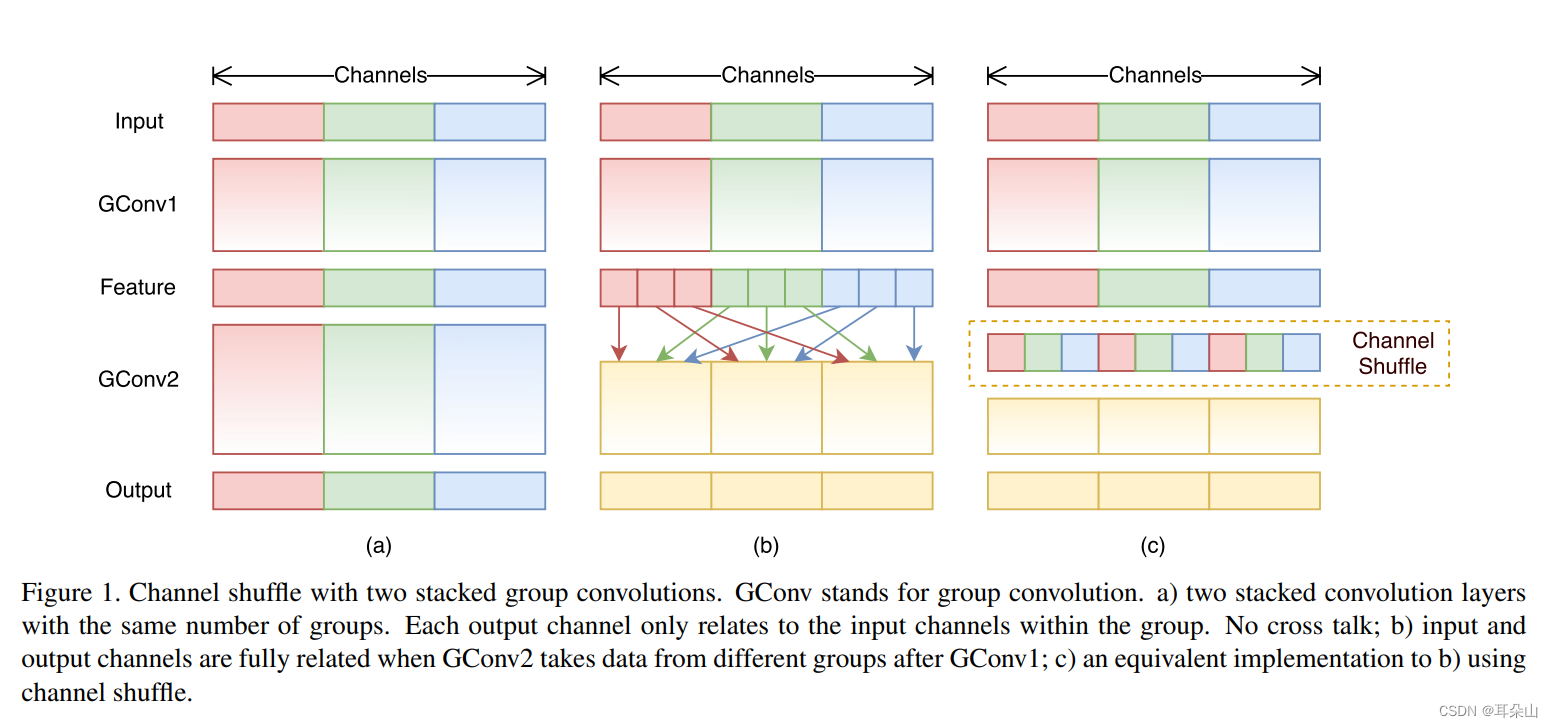
如图(a)中是常规的group conv,但问题是如果只是简单的串联各组信息,各个channel的信息就被隔离开来,组与组之间的信息没有交流,此属性会阻塞通道组之间的信息流并削弱表征能力。由此提出了Channel Shuffle,如图(b)(c)所示,将每一个group分成不同的subgroup,再将不同subgroup重新组合之后作为下一次group conv的输入。
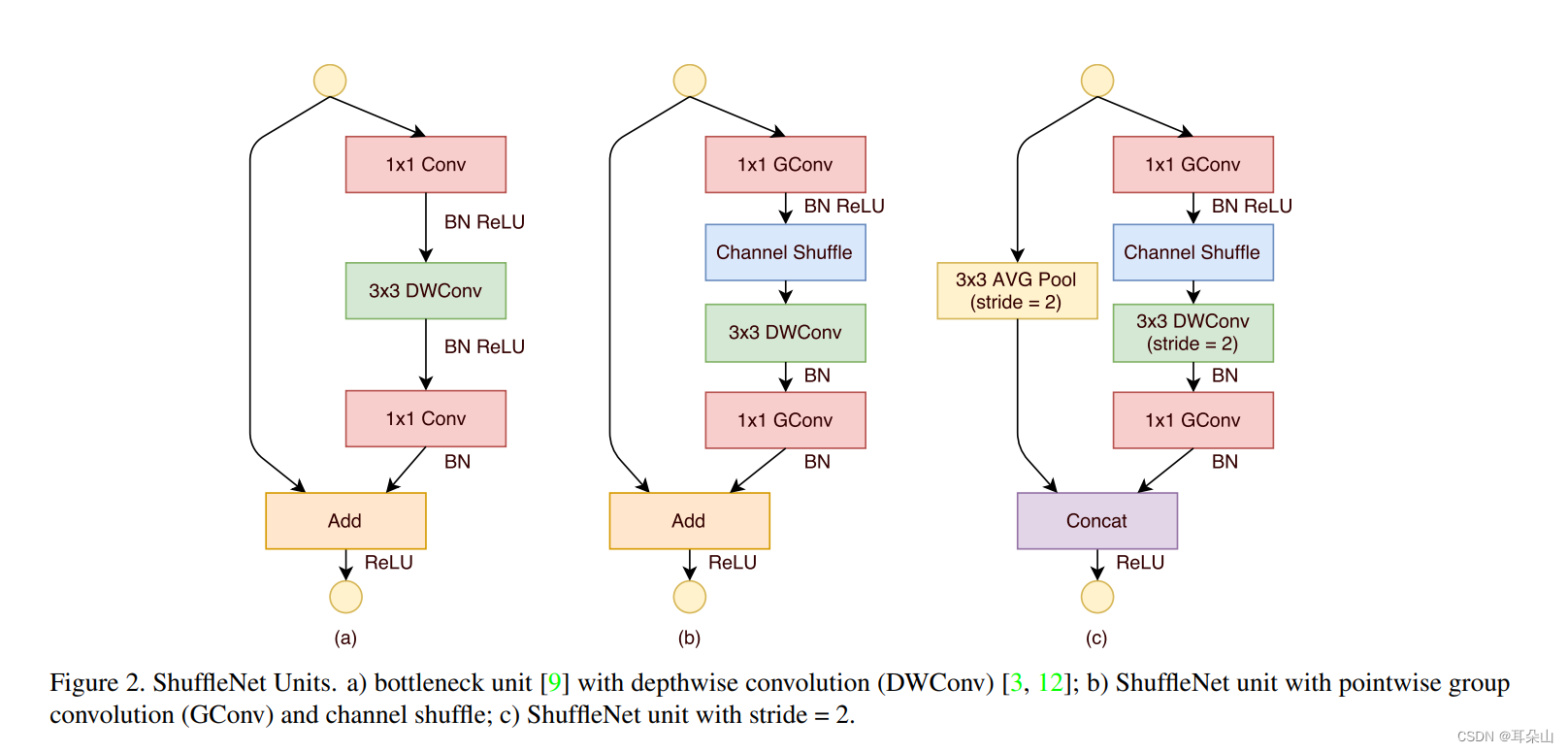
与传统ResNet中不同的是,如图(a)与(b)所示,作者在Shuffle Net中直接对1x1的卷积做group操作,因为作者认为1*1的卷积操作的计算量不可忽视。在图(c)中添加了一个Average pooling和设置了stride=2,另外原来ResNet最后是一个Add操作,也就是元素值相加,而在图(c)中是采用concat的操作,也就是按channel合并,类似googleNet的Inception操作。
ShuffleNet的核心就是用 PointWise Group Convolution,Channel Shuffle和DepthWise Separable Convolution代替ResNet block的相应层构成了ShuffleNet unit,达到了减少计算量和提高准确率的目的。
ShuffleNet V2
原论文链接:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design。
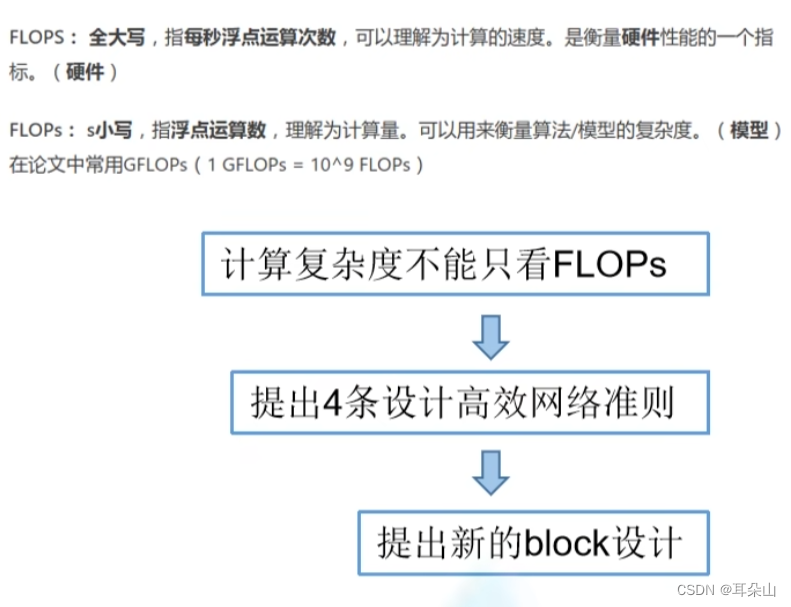
ShuffleNet V2提出模型执行效率的准则不能完全取决于FLOPs,经常发现FLOPs差不多的两个模型的运算速度却不一样,整个运行时被分解为不同的操作,如图所示。我们注意到FLOPs度量只考虑了卷积部分。虽然这一部分消耗的时间最多,但其他操作包括data I/O、data shuffle和element-wise operations(AddTensor、ReLU等)也占用了相当多的时间。因此,FLOPs并不是对实际运行时的足够准确的估计,影响模型运行速度的另一个指标也很重要,那就是MAC(memory access cost)内存访问成本。

ShuffleNet V2提出了以下4条Guideline:
G1) Equal channel width minimizes memory access cost (MAC)
当卷积层的输入特征矩阵与输出特征矩阵channel相等时MAC最小(保持FLOPs不变时)
G2) Excessive group convolution increases MAC
过多的使用组卷积,会增加MAC
G3) Network fragmentation reduces degree of parallelism
网络分支数量虽然增加了模型的模型的性能,但对模型速度的有影响,网络的分支减少了并行度,模型的分支数量越少,模型的速度越快
G4) Element-wise operations are non-negligible
Element-wise 操作对模型速度的影响,element-wise所带来的时间消耗远比FLOPs上体现的数值要多,因此需要尽可能的减
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









