






序、慢慢来才是最快的方法。
背景
LinkedHashMap 是继承于 HashMap 实现的哈希链表,它同时具备双向链表和散列表的特点。事实上,LinkedHashMap 继承了 HashMap 的主要功能,并通过 HashMap 预留的 Hook 点维护双向链表的逻辑。
1.缓存淘汰算法
1.1什么是缓存淘汰算法
缓存是提高数据读取性能的通用技术,在硬件和软件设计中被广泛使用,例如CPU缓存,Glide缓存内存缓存,数据库缓存。由于缓存空间不可能无限大,当缓存容量占满时,就需要利用某种策略将部分数据换出缓存,这就是缓存的淘汰问题/替换策略。
常见的缓存淘汰策略有:
-
1、随机策略: 使用一个随机数生成器随机地选择要被淘汰的数据块;
-
2、FIFO 先进先出策略: 记录各个数据块的访问时间,最早访问的数据最先被淘汰;
-
3、LRU (Least Recently Used)最近最少策略: 记录各个数据块的访问 “时间戳” ,最近最久未使用的数据最先被淘汰。与前 2 种策略相比,LRU 策略平均缓存命中率更高,这是因为 LRU 策略利用了 “局部性原理”:最近被访问过的数据,将来被访问的几率较大,最近很久未访问的数据,将来访问的几率也较小;
-
4、LFU (Least Frequently Used)最不经常使用策略: 与 LRU 相比,LFU 更加注重使用的 “频率” 。LFU 会记录每个数据块的访问次数,最少访问次数的数据最先被淘汰。但是有些数据在开始时使用次数很高,以后不再使用,这些数据就会长时间污染缓存。可以定期将计数器右移一位,形成指数衰减。
FIFO和LRU策略图形解释
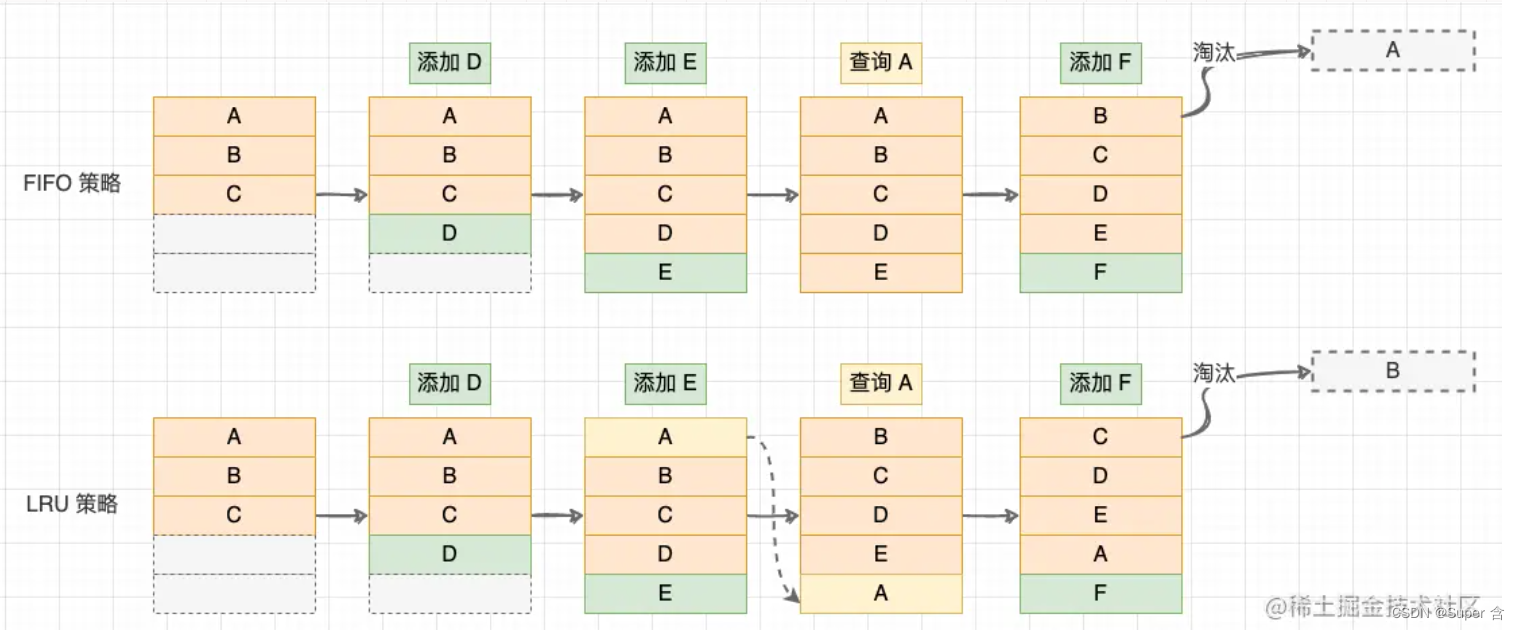
1.2向外看,LRU的变型
在标准的LRU算法上还有一些变型实现,这是因为LRU算法本身也存在一些不足。例如,当数据中热点数据较多时,LRU能够保证较多的命中率。但是当有偶然的批量的非热点数据产生时,就会讲热点数据寄出缓存,是的缓存被污染。因此,LRU也有一些变型。
- LRU-K: 提供两个 LRU 队列,一个是访问计数队列,一个是标准的 LRU 队列,两个队列都按照 LRU 规则淘汰数据。当访问一个数据时,数据先进入访问计数队列,当数据访问次数超过 K 次后,才会进入标准 LRU 队列。标准的 LRU 算法相当于 LRU-1;
- Two Queue: 相当于 LRU-2 的变型,将访问计数队列替换为 FIFO 队列淘汰数据数据。当访问一个数据时,数据先进入 FIFO 队列,当第 2 次访问数据时,才会进入标准 LRU 队列;
- Multi Queue: 在 LRU-K 的基础上增加更多队列,提供多个级别的缓冲。
1.3如何实现LRU缓存淘汰算法
我们尝试找到 LRU 缓存淘汰算法的实现方案。经过总结,我们可以定义一个缓存系统的基本操作:
我们发现,前 3 个操作都有 “查询” 操作, 所以缓存系统的性能主要取决于查找数据和淘汰数据是否高效。 下面,我们用递推的思路推导 LRU 缓存的实现方案,主要分为 3 种方案:
PS:双向链表+散列表这种数据结构就叫“哈希链表或链式哈希表”,Java的LinkedHashMap就是基于哈希链表的数据结构。
2.LinkedHashMap哈希链表
PS:需要注意:LinkedHashMap 中的 “Linked” 实际上是指双向链表,并不是指解决散列冲突中的分离链表法。
2.1LinkedHashMap 的特点
2.2说一下 HashMap 和 LinkedHashMap 的区别?
-
- 操作 1 - 添加数据: 先查询数据是否存在,不存在则添加数据,存在则更新数据,并尝试淘汰数据;
- 操作 2 - 删除数据: 先查询数据是否存在,存在则删除数据;
- 操作 3 - 查询数据: 如果数据不存在则返回 null;
- 操作 4 - 淘汰数据: 添加数据时如果容量已满,则根据缓存淘汰策略一个数据。
-
方案 1 - 基于时间戳的数组: 在每个数据块中记录最近访问的时间戳,当数据被访问(添加、更新或查询)时,将数据的时间戳更新到当前时间。当数组空间已满时,则扫描数组淘汰时间戳最小的数据。
- 查找数据: 需要遍历整个数组找到目标数据,时间复杂度为 O(n);
- 淘汰数据: 需要遍历整个数组找到时间戳最小的数据,且在移除数组元素时需要搬运数据,整体时间复杂度为 O(n)。
-
方案 2 - 基于双向链表: 不再直接维护时间戳,而是利用链表的顺序隐式维护时间戳的先后顺序。当数据被访问(添加、更新或查询)时,将数据插入到链表头部。当空间已满时,直接淘汰链表的尾节点。
- 查询数据:需要遍历整个链表找到目标数据,时间复杂度为 O(n);
- 淘汰数据:直接淘汰链表尾节点,时间复杂度为 O(1)。
-
方案 3 - 基于双向链表 + 散列表: 使用双向链表可以将淘汰数据的时间复杂度降低为 O(1),但是查询数据的时间复杂度还是 O(n),我们可以在双向链表的基础上增加散列表,将查询操作的时间复杂度降低为 O(1)。
- 查询数据:通过散列表定位数据,时间复杂度为 O(1);
- 淘汰数据:直接淘汰链表尾节点,时间复杂度为 O(1)。
-
1、LinkedHashMap 是继承于 HashMap 实现的哈希链表,它同时具备双向链表和散列表的特点。事实上,LinkedHashMap 继承了 HashMap 的主要功能,并通过 HashMap 预留的 Hook 点维护双向链表的逻辑。
- 1.1 当 LinkedHashMap 作为散列表时,主要体现出 O(1) 时间复杂度的查询效率;
- 1.2 当 LinkedHashMap 作为双向链表时,主要体现出有序的特性。
-
2、LinkedHashMap 支持 2 种排序模式,这是通过构造器参数
accessOrder标记位控制的,表示是否按照访问顺序排序,默认为 false 按照插入顺序。- 2.1 插入顺序(默认): 按照数据添加到 LinkedHashMap 的顺序排序,即 FIFO 策略;
- 2.2 访问顺序: 按照数据被访问(包括插入、更新、查询)的顺序排序,即 LRU 策略。
-
3、在有序性的基础上,LinkedHashMap 提供了维护了淘汰数据能力,并开放了淘汰判断的接口
removeEldestEntry()。在每次添加数据时,会回调removeEldestEntry()接口,开发者可以重写这个接口决定是否移除最早的节点(在 FIFO 策略中是最早添加的节点,在 LRU 策略中是最早未访问的节点);-
4、与 HashMap 相同,LinkedHashMap 也不考虑线程同步,也会存在线程安全问题。可以使用 Collections.synchronizedMap 包装类,其原理也是在所有方法上增加 synchronized 关键字。
-
事实上,HashMap 和 LinkedHashMap 并不是平行的关系,而是继承的关系,LinkedHashMap 是继承于 HashMap 实现的哈希链表。
两者主要的区别在于有序性: LinkedHashMap 会维护数据的插入顺序或访问顺序,而且封装了淘汰数据的能力。在迭代器遍历时,HashMap 会按照数组顺序遍历桶节点,从开发者的视角看是无序的。而是按照双向链表的顺序从 head 节点开始遍历,从开发者的视角是可以感知到的插入顺序或访问顺序。
LinkedHashMap 继承于 HashMap,在后者的基础上通过双向链表维护节点的插入顺序或访问顺序。因此,我们先回顾下 HashMap 为 LinkedHashMap 预留的 Hook 点:
参考
- afterNodeAccess: 在节点被访问时回调;
- afterNodeInsertion: 在节点被插入时回调,其中有参数
evict标记是否淘汰最早的节点。在初始化、反序列化或克隆等构造过程中,evict默认为 false,表示在构造过程中不淘汰。 afterNodeRemoval: 在节点被移除时回调。















 901
901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









