







简介
数据库分片可以把他理解成分库,将一张表拆分到多个数据库中,通常是在表数据大的情况进行拆分。
根据InnerDB索引原理,主键索引类型bigint计算得出一张表达到2千万就需要进行拆分了。当然也需要提前做好拆分,数据量大查询效率会慢。
阿里巴巴《Java 开发手册》提出单表行数超过 500 万行或者单表容量超过 2GB,建议分表分库。
MyCat支持的常见的分片算法:
1、求模算法
2、分片枚举
3、范围约定
4、日期指定
5、固定分片hash算法
6、通配取模
7、ASCII码求模通配
8、编程指定
9、字符串拆分hash解析
参考文献:
mycat1.6官方文档:http://www.mycat.org.cn/mycat1.html
mycat权威指南:http://dl.mycat.org.cn/mycat-definitive-guide.pdf
MyCat分片求模算法配置
本文的配置建立在上篇MyCat读写分离的基础上。
在主节点创建三个数据库并且创建t_uesr表。
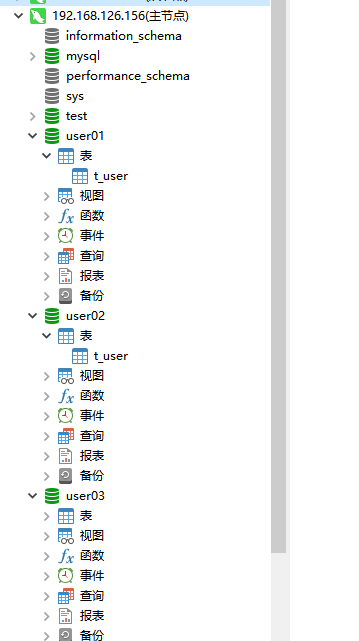
修改schema.xml
vim conf/schema.xml
内容如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="mycat" checkSQLschema="true" dataNode="dn1" sqlMaxLimit="100">
<table name="t_user" dataNode="dn1,dn2,dn3" rule="role1"/>
</schema>
<dataNode name="dn1" dataHost="jdbchost" database="user01" />
<dataNode name="dn2" dataHost="jdbchost" database="user02" />
<dataNode name="dn3" dataHost="jdbchost" database="user03" />
<dataHost name="jdbchost" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostMaster" url="192.168.126.156:3306" user="root" password="123456">
<readHost host="hostSlave" url="192.168.126.156:3307" user="root" password="123456"/>
</writeHost>
</dataHost>
</mycat:schema>
修改rule.xml
vim conf/rule.xml
内容如下
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="role1">
<rule>
<columns>id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!--指定分片数量-->
<property name="count">3</property>
</function>
</mycat:rule>
重启MyCat
./bin/mycat stop
./bin/mycat start
效果展示:
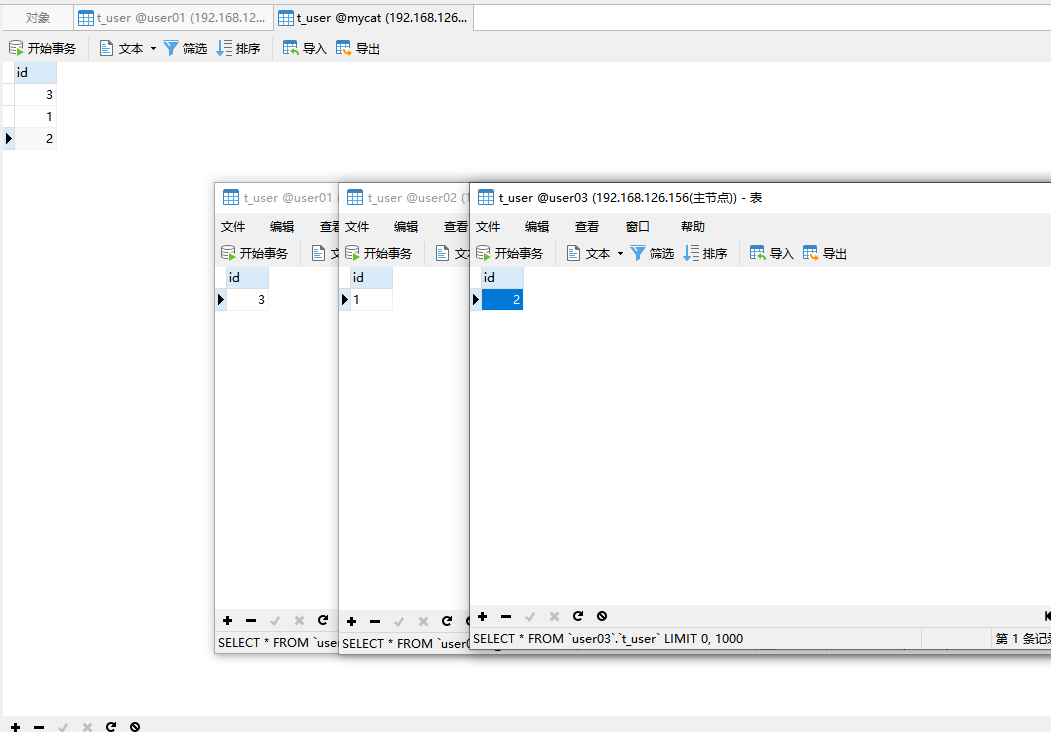
总结:
在真实数据库看到
user01库:3(3%3=0)
user02库:1(1%3=1)
user03库:2(2%3=2)
MyCat中间件插入的时候帮取模算法,查询帮我们我们数据汇总,看起来像是同一个库。
MyCat分片原理
日志分析
修改日志配置文件
vim conf/log4j2.xml
将asyncRoot level="info"修改成asyncRoot level=“debug”
查看日志:
tail -200f mycat.log
找到这段日志:
SELECT * FROM `t_user` LIMIT 0, 1000, route={
1 -> dn1{SELECT *
FROM `t_user`
LIMIT 0, 1000}
2 -> dn2{SELECT *
FROM `t_user`
LIMIT 0, 1000}
3 -> dn3{SELECT *
FROM `t_user`
LIMIT 0, 1000}
} rrs
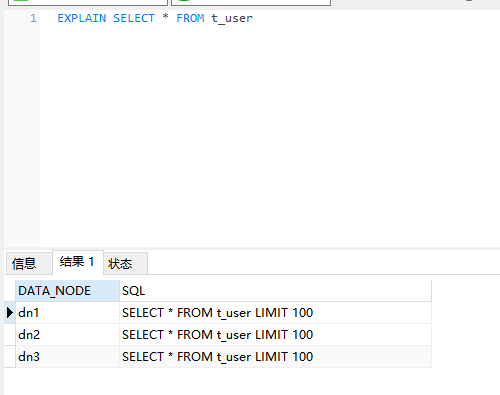
原理分析,在不带条件的情况下,MyCat会执行3次SQL语句,并且把结果拼在一起返回。
执行计划
除了使用日志分析,MyCat 封装了执行计划
EXPLAIN SELECT * FROM t_user
查询结果如下
如果查询字段是分片字段,MyCat会优化SQL如下:
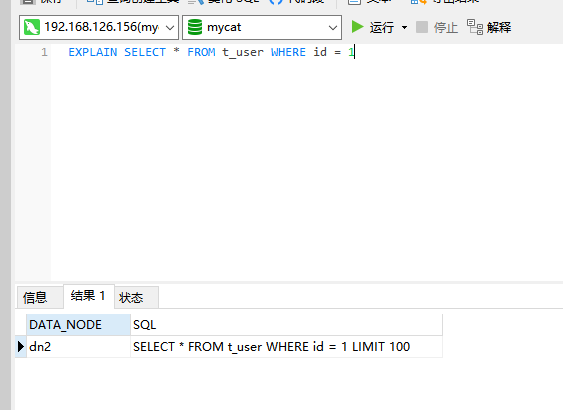
查询字段非分片字段,会查全部表。这样效率是很慢的,这也是MyCat中的不足。

















 1554
1554











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











