






SPG-Net: Segmentation Prediction and Guidance Network for Image Inpainting
背景和动机
对于图像inpainting任务,直接将缺失图像映射成完整图像会使得结果过于平滑以及存在人造伪影,为了克服这个问题,一系列通过构造先验信息,然后再通过先验信息引导后续图像inpainting的模型便诞生了。这些模型里面比较有名的两个流派一个是以图像edge作为先验信息(开山之作:EdgeConnet),另一个是以图像的语义分割信息作为先验,其开山之作就是本文介绍的方法。
了解过语义分割的都知道,语义分割是对图像中的pixel进行分类,最终使得每个pixel都被分配到某个预先给定的类集合中的某一类。每个不同的类object,最直接的差异就是其texture。谈到texture,这就可以与图像inpainting进行联系了,为什么之前的inpainting结果存在texture过于平滑,作者认为由于不同语义区域的先验信息是不同的,不假思索的将不同的语义信息映射到同一个流形中,这就会导致模型生成不真实的texture。而通过先生成语义分割图的方式,然后将语义分割图作为先验信息,使得在进行图像修复的时候对于缺失区域只使用相同object的texture特征进行inpainting,就会大大缓解这种问题。
方法介绍
本文的模型结构与EdgeConnet极其的相似,为了对比,这里我同时给出两个模型的结构图:
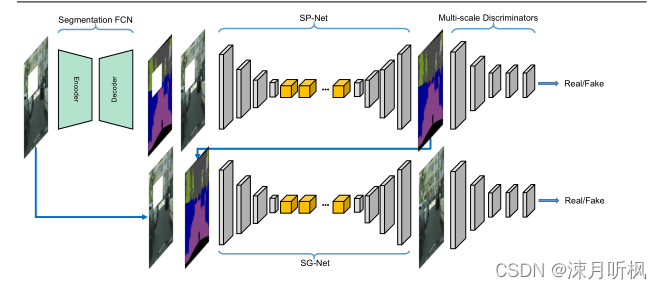
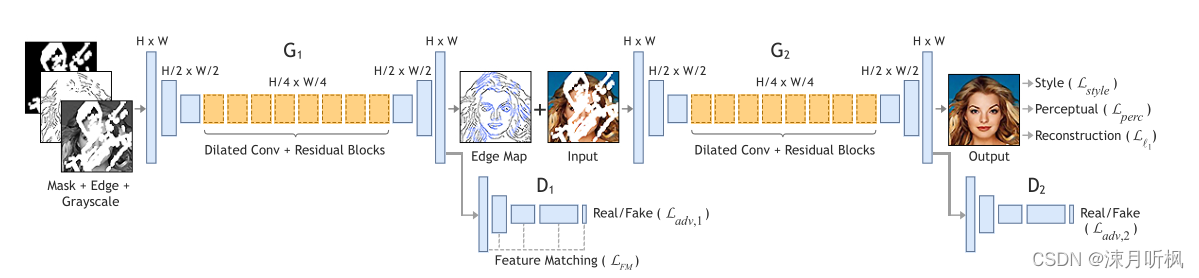
可以看到,两个模型都是使用了两阶段的结构,第一阶段将缺失图像的语义信息图/edge图通过一个生成对抗网络得到完整的语义信息图/edge图,第二阶段用第一阶段的结果作为先验信息进行图像inpainting。本文在第一阶段直接使用了经典的语义分割模型FCN,但是对其做了一点调整:将其中的dilation convolution替换为了residual blocks,从而获得更好的学习能力。第二阶段的网络结构是经典的encode-decode,具体参数可参见原文。
损失函数方面,本文也并没有什么亮眼的地方,第一阶段的损失:
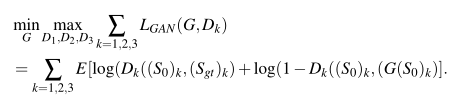
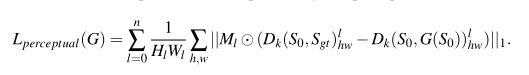
其中对抗损失使用的是多尺度损失,
(
S
0
)
k
(S_0)_k
(S0)k和
(
S
g
t
)
k
(S_{gt})_k
(Sgt)k代表第
k
k
k个尺度的语义分割图。第二阶段的损失和第一阶段基本相同,唯一要说的是作者在这里添加了额外的一项AlexNet损失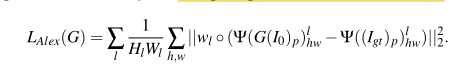
作者给的解释是相比于Vgg-19,AlexNet所提取的特征更加符合人类的认知。所以这里的
L
A
l
e
x
L_{Alex}
LAlex完全可以看成是将VGG-19换成AlexNet的感知损失。














 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









