






pretrain-finetune模型范式根据其训练方式可以分为监督学习方式和无监督学习方式,监督学习方式通常需要在有标签数据集上,用交叉熵来优化分类损失。基于对比学习策略,无监督学习方式则是基于对比损失来优化,不需要用到标签信息。通常来说,评判一个pretrain-finetune模型范式好坏的标准是考察其在下游任务的推广能力,即经过预训练后是否可以很好的迁移到下游目标任务上。经验来说,无监督学习的pretrain-finetune模型有着更好的迁移能力,以往的研究通常将其原因归结为以下两点:
1、无监督学习时没有用到高级的语义信息,因此避免了网络过分拟合实例标签,因此可以更加注重实例本身的信息。
2、依然是由于学习时没有用到高级的语义信息,因此学习的特征更加偏向于低级视觉信息,因此其更容易进行泛化。
我们知道自SimCLR以来,对比学习都习惯于在特征输出之前通过一个MLPs映射,这很有效,然而从结构上来讲这也正是监督学习和无监督学习的一大差异。因此本文作者从这个差异性结构入手,对MLPs如果影响泛化性进行了分析,并最终得出结论:MLPs是影响泛化性的重要因素,将MLPs添加到监督学习框架中同样可以提高模型泛化性。
基于预训练—测试时两个数据集语义差异越大,迁移难度越大,作者首先制作了两个玩具数据集:将ImageNet-1K中的生物类别组成了预训练数据集(Pre-D),之后又将ImageNet-1K中的工具类别组成了测试数据集(eval-D)。作者先用不同方法在Pre-D上进行预训练,然后固定特征提取部分,在eval-D上对分类头进行微调,并比较分类精度。此外在进行分类精度比较时,作者不仅比较了最终特征的分类精度,还使用了阶段级的评价策略,对多个阶段的特征都进行了分类精度的比较,具体如图所示:
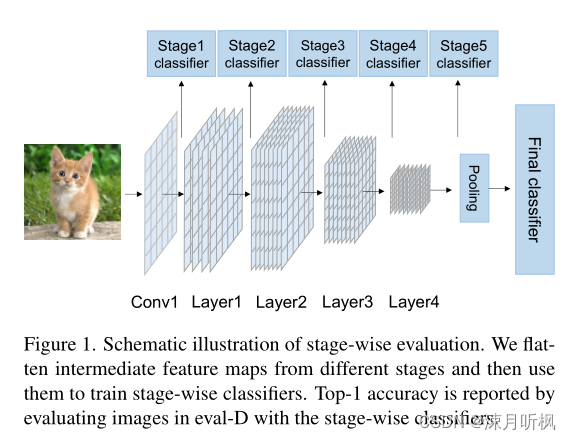
其中比较的模型有 conventional supervised pretraining method(SL)和Mocov1, Mocov2, Byol这三种无监督方式。具体比较结果如图所示:
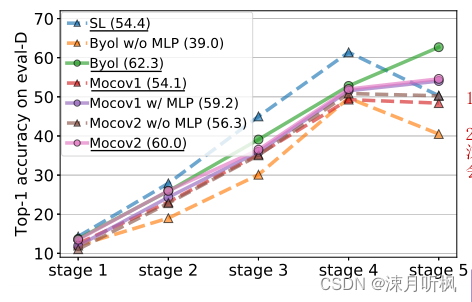
从图中可以直观的分析出两点:
1、stag1~stag4,SL方法的分类精度高于其他无监督方式,说明额外学习语义标签确实有效;
2、到了stag5,网络的特征已经非常深了,此时SL的精度反而开始迅速下降。除此之外,其他几种无监督方式的无MLP版本(w/o MLP)其精度也是从这一阶段开始下降,说明所有没有MLP的模型(MoCov1并没有MLP,因此为了对比,作者加了一个有MLP版本的MoCov1),在深层特征都出现了性能下降,因此作者提出了一个假设:MLP是防止深层特征性能下降的关键。
以上实验是在无监督框架下进行的消融,为了进一步验证以上猜想,作者提出将MLP移植到监督学习框架下,并通过四种不同的方式将SL,SL+MLP和无监督baseline(Byol)进行性能比较。首先看一下作者对监督学习框架进行的改变:
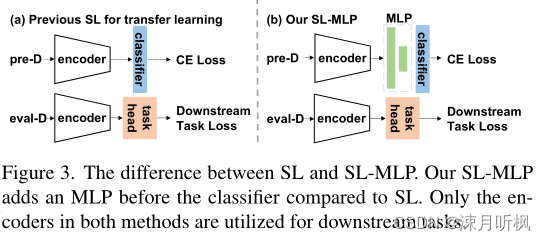
普通的监督学习框架如(a)所示,编码器后面加一个分类头进行预训练,之后去掉分类头并固定编码器参数,换上下游任务专属分类头进行微调,(b)中作者则是在预训练时,在编码器和分类头之间加了一个MLP,微调时与(a)一样。以下是四种比较方式:
1、测试集的分类精度
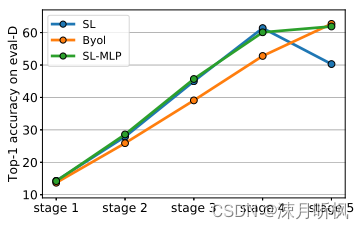
可以看到,相比于Byol,SL和SL-MLP在前4阶段的精度都更高,然而第5阶段是SL的精度突然下降,而添加了MLP的SL在第5阶段虽然精度上升的幅度没有很高,但是明显阻止了下降的趋势。
2、特征内部多样性
在预训练-微调模型中,通常更大的内部类多样性可以说明特征有着更高的实例级别的判别信息,通常来说也就有着更好的泛化性。*(所谓的特征内部多样性,通俗来讲就是一个类中每个不同样本特征的差异性,如果一类数据都被映射到了同一个点,那么内部多样性就非常低。)*为此作者可视化了在eval-D上的特征分布,如图:

可以看到当没有MLP时,无论是监督方法还是无监督方法,其特征的内部多样性都非常差(同一类特征几乎都被映射到了同一位置),然而添加了MLP后,其特征的类内多样性明显改善。此外作者引用了鉴别率
ϕ
(
I
)
\phi(I)
ϕ(I)来定量的比较了以上方式的类内多样性(这个值最早提出时并不是用在这类问题上,作者在这里第一次将其用在这类问题,可以看做是一种创新,原文4.3部分作者专门对其有效性进行了分析,这里不再赘述),其公式如下:

其具体解释如下,这里我直接贴出原文描述

直观理解就是:
μ
(
I
i
)
\mu(I_i)
μ(Ii)代表第
i
i
i类数据中每一个数据类中心的距离和;
D
i
n
t
e
r
D_{inter}
Dinter和
D
i
n
t
r
a
D_{intra}
Dintra则分别代表类别之间的离散度和每个类内的离散度之和。由此,越小的
ϕ
(
I
)
\phi(I)
ϕ(I)代表特征分布的类内多样性越大,对应这一部分开头的结论就是模型的泛化性越好,具体实验结果如下:
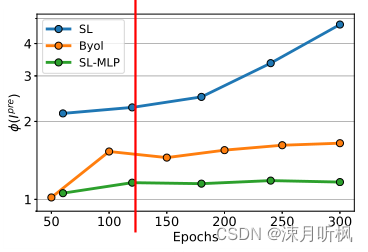
Byol和SL-MLP的
ϕ
(
I
)
\phi(I)
ϕ(I)在整个训练阶段一直都维持在一个较低的水平,而SL的
ϕ
(
I
)
\phi(I)
ϕ(I)值则很高,并且随着训练进行,其值不断增高。
3、在特征空间上的特征距离
直观来说,降低预训练集合下游任务集的特征距离可以更容易的进行迁移,而两个集合的特征混合度则可以非常直观的表示两个集合特征的距离,混合的越好说明特征距离越小。因此作者进一步比较了两个集合的特征混合度,其计算方式如下:
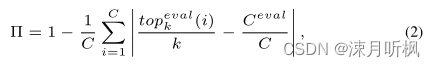
上式计算的是在特征空间上的特征相似度,因此依照本节开始的结论,这个值越大越好:
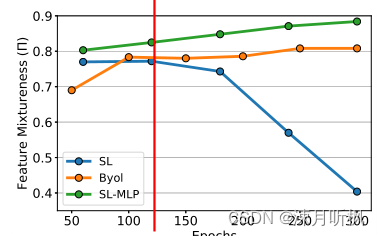
可以看到在训练开始阶段,三种方式的特征混合度还是不相上下的,随着训练进行,SL的特征混合度迅速下降,这说明在SL训练的开始阶段,其学习的特征是浅层特征,随着训练进行,其利用语义标签将浅层特征整合成了深层特征,然而这种特征整合也降低了特征的泛化性。
4、特征冗余性
预训练的目的是使得网络在微调开始阶段就对输入数据有着一定的特征提取能力,而提取的特征显然是越精炼越好*(否则当提取的特征冗余性非常高时,预训练网络就近似成了一个恒等映射)*,因此作者通过定量的比价特征冗余性来比较以上不同方法,其计算公式如下:
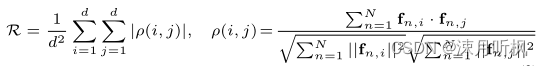
直挂来说,以上公式就是计算所有特征其自身不同通道的相关性,实验结果如下:
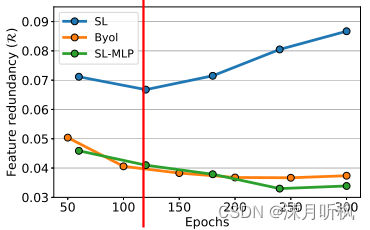
类似于上面三个实验,这里也显示出随着训练进行,SL的特征冗余性迅速提升,而MLP则可以阻止这种趋势。
个人理解:
越高级的特征,或者说是越接近语意级别的特征通常是越难以被泛化的,这其实是符合人类直觉的。试想一下,当你整体的去学习一个猫长啥样,一个狗长啥样(类比图像的high-level信息),那么此时再给你一只猴子让你去学习,你无法将其整体的代入到你以学习的猫和狗的知识中,那么此时你只能从头学起;而当你学习的是更低级的信息,如四条腿、有尾巴这些局部结构(类比图像的middle-level信息),甚至是皮毛的纹理,颜色等(类比图像的low-leve信息),那么此时你的已知信息就很容易被应用到去学习猴子。而网络模型在处理图像数据时,其规律是浅层网络倾向于处理low-level特征,随着网络的深入,其特征会逐渐向high-leve过渡,这也对应了以上实验中SL在浅层时的泛化性并不差,而深层的泛化性反而变差的现象。
进一步的,个人大胆猜测,当SL的编码器输出的特征之间将其进行分类时,由于此时特征空间被高度限制(假如编码器输出的特征维度是
k
k
k,那么其特征空间就是
k
k
k),因此不同实例特征也被高度压缩,为了迎合被高度限制的空间范围,特征被推向了更抽象的语义维度。而添加了MLP后,给输出特征加了一个缓冲的阶段,相当于给输出的特征变相的扩大了特征空间的范围(假如编码器输出的特征维度是
k
k
k,MLP是
k
1
×
k
2
k_1 \times k_2
k1×k2的两层映射,那么特征空间就是
k
×
k
1
×
k
2
k \times k_1 \times k_2
k×k1×k2 or 三者的指数关系??)因此特征可以继续保持在低级的维度,因此不至于损失太多的泛化性,从这个角度来讲,理论上这个MLPs真正起作用的是其fc部分,而激活部分则并没有起作用(可以通过构建一个正常的MLP和没有激活的MLP以及一个较深的MLP进行消融实验对比来验证以上猜想)。
本人目前 烟台大学 数学与信息科学学院 研二在读,主要感兴趣的方向为:底层视觉处理,对比学习,因果推断,多模态等。感兴趣的小伙伴可以+我:w13375533677 共同进步!!!














 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









